A deep dive into the Data on H1B Visas released by USA
analysis
Author
Aditya Dahiya
Published
October 14, 2024
The H1B visa program enables U.S. companies to hire foreign workers in specialized fields, such as technology, with visas granted via an annual lottery. A recent Bloomberg News investigation exposed how some companies exploited the lottery system, submitting multiple applications to increase their chances. The dataset used in this analysis, covering fiscal years 2021-2024, was obtained from U.S. Citizenship and Immigration Services (USCIS) through a Freedom of Information Act (FOIA) request. The detailed dataset, including information on employers, job titles, salaries, and visa petitions, can be accessed on GitHub.
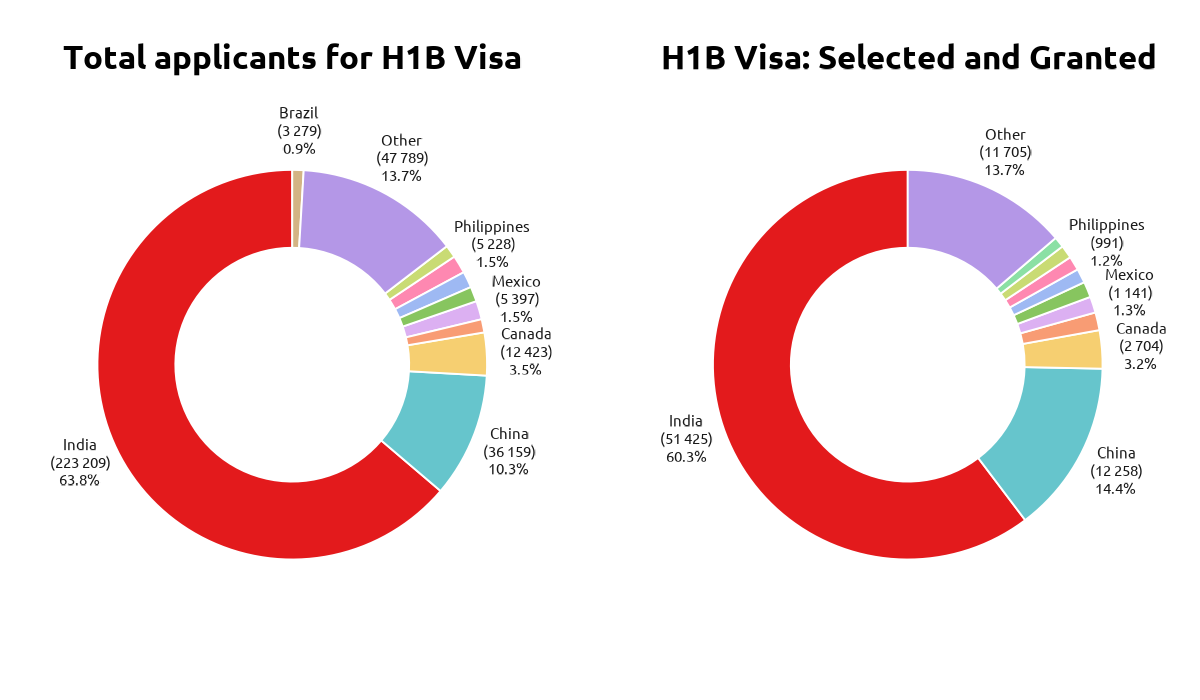
Almost 60% applicants are from India, and as expected in the lottery approx 60% of all the H1B Visas go to Indians.
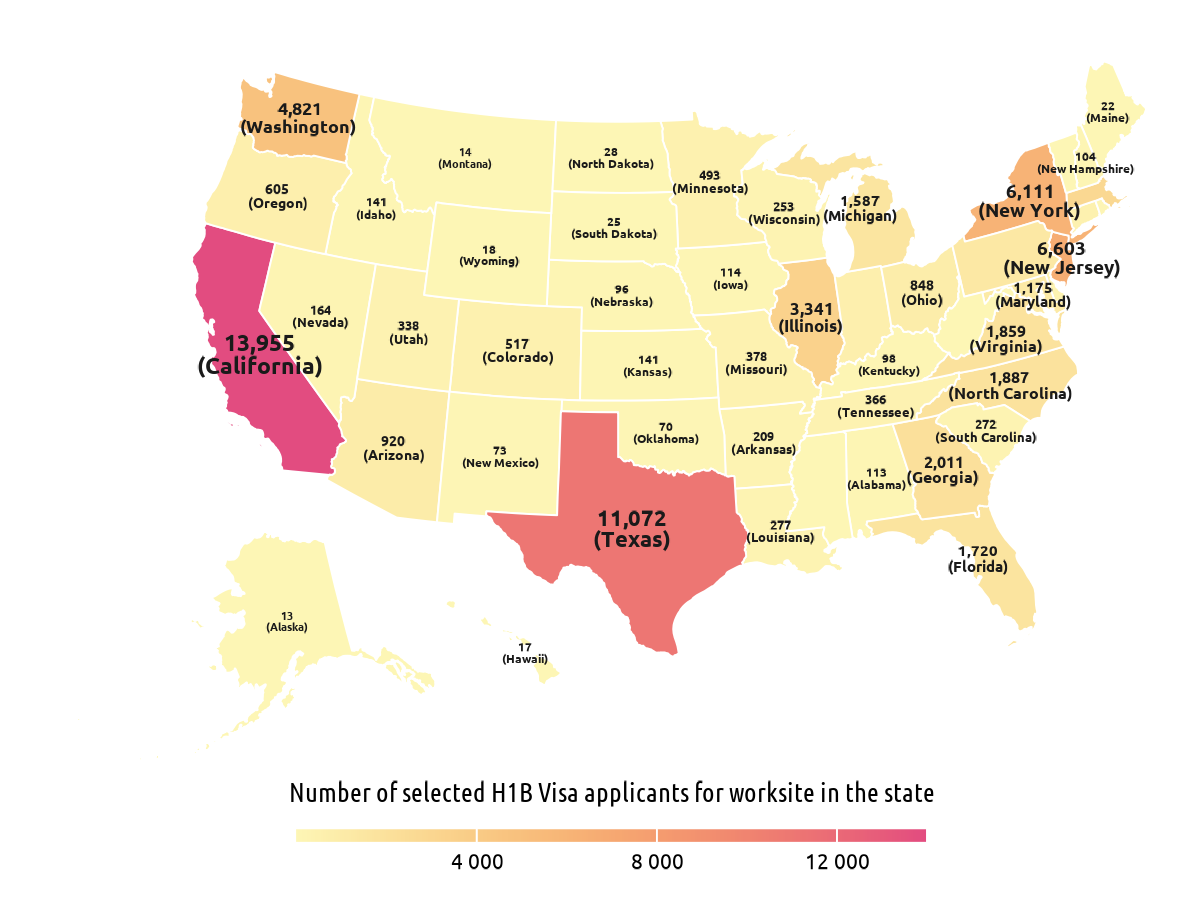
States in USA where the selected H1B visa applicants went to show us that most of the selected visa applicants went on to work in California or Texas.
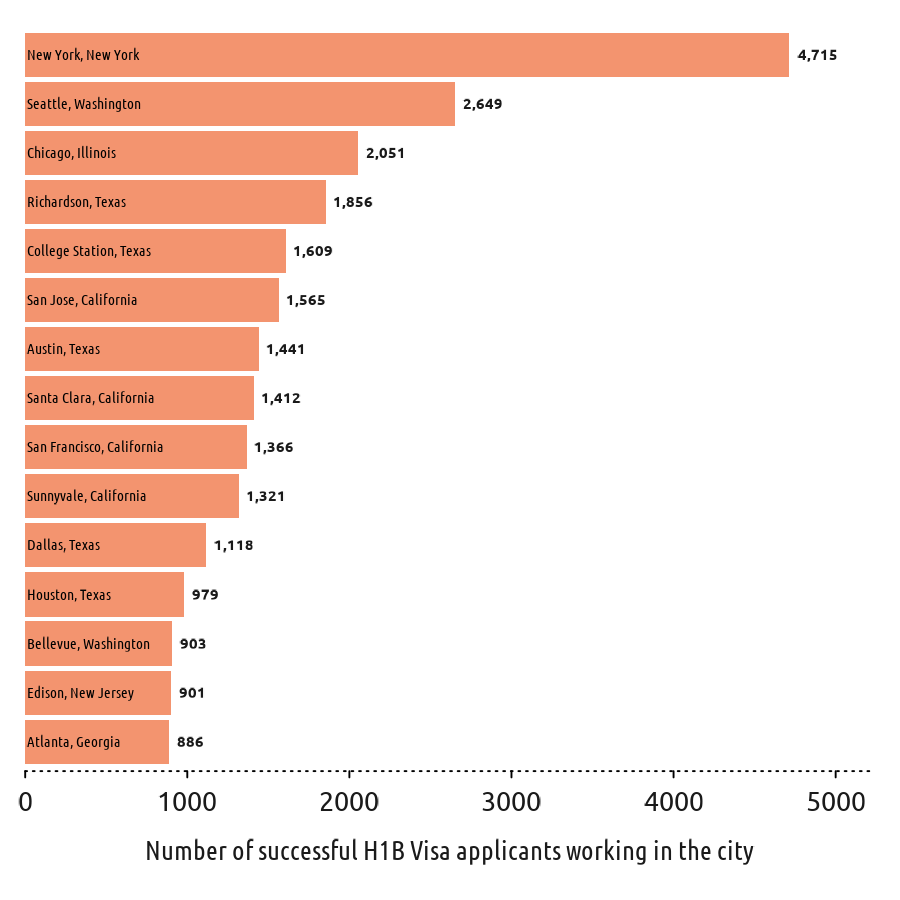
Popular Cities as destinations for H1B selected Visa applicants are New York City, followed by Seattle.
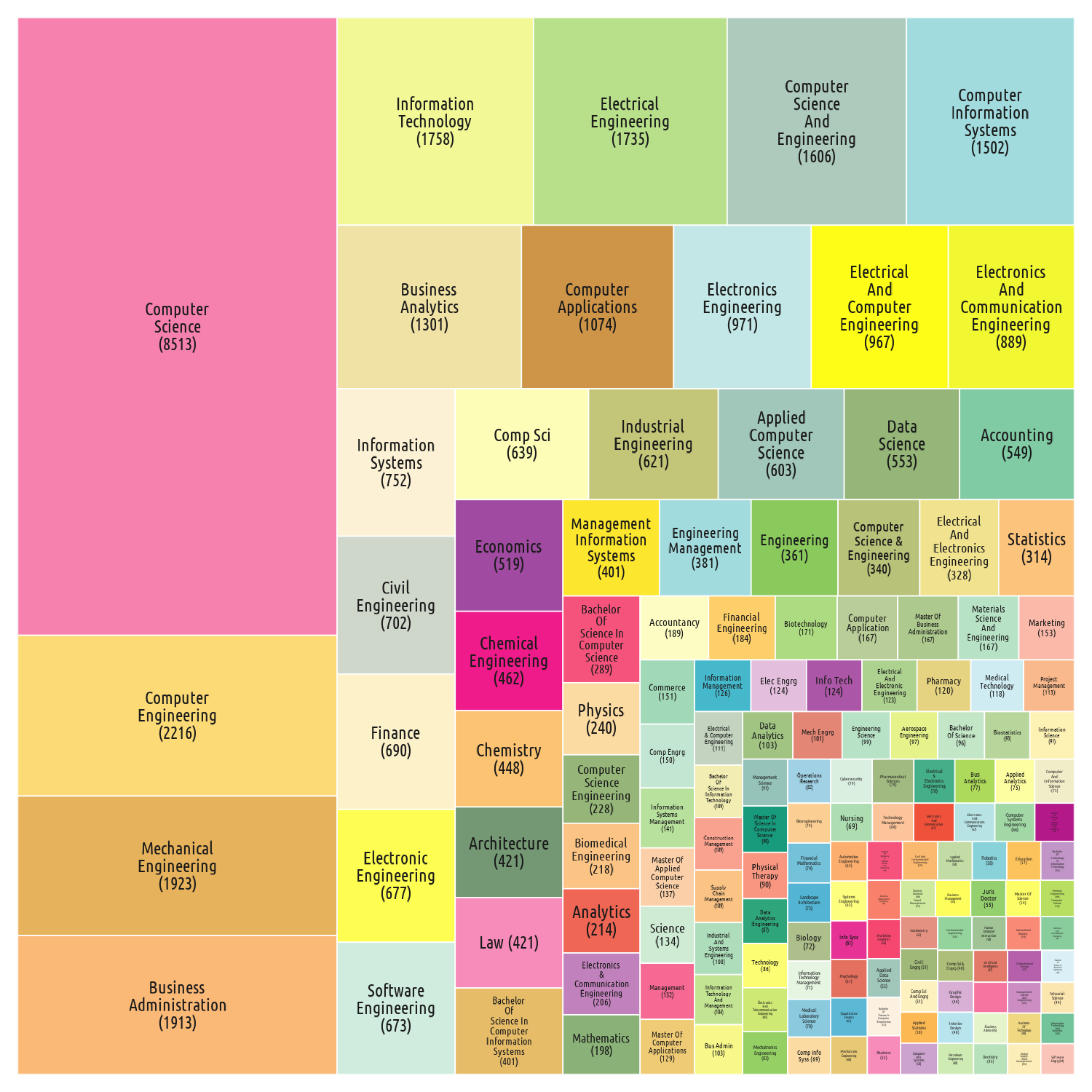
Occupations Sectors related to Computers and IT dominate the field of study for successful H1B Visa Applicants.
Figure 1: Most of the applicants are from India, and naturally most of the visas go to Indians.
Figure 2: A map of USA with number of successful visa applicants working in each state.
Figure 3: Most popular cities for worksites of successful H1B Visa applicants
Figure 4: The top 150 fields of study for the successful H1B Selected VISA Applicants
This article and analysis is a work in progress, and new material will be added soon.
The code used to prepare these graphics is given below.
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(patchwork) # Combining plotslibrary(magick) # Dealing with imageslibrary(httr) # Download fileslibrary(zip) # Handle ZIP fileslibrary(countrycode) # To get Country Codeslibrary(sf) # Mapping# Getting basic fonts etc. for the entire articlefont_add_google("Ubuntu Condensed", "caption_font")font_add_google("Ubuntu", "body_font")showtext_auto()text_col <-"grey10"bg_col ="white"
Code
# Get Data Dictionary used by Bloombergdictionary <- openxlsx::read.xlsx("https://github.com/BloombergGraphics/2024-h1b-immigration-data/raw/refs/heads/main/TRK_13139_I129_H1B_Registrations_FY21_FY24_FOIA_FIN.xlsx",sheet ="Data Dictionary",rows =1:57,cols =1:2) |> janitor::clean_names()# Single registrations data# Download the ZIP file from the URLurl <-"https://github.com/BloombergGraphics/2024-h1b-immigration-data/blob/main/TRK_13139_FY2024_single_reg.zip?raw=true"temp_zip <-tempfile(fileext =".zip")GET(url, write_disk(temp_zip, overwrite =TRUE))# Unzip the file to a temporary directorytemp_dir <-tempdir()unzip(temp_zip, exdir = temp_dir)# Read the CSV file into Rcsv_file <-file.path(temp_dir, "TRK_13139_FY2024_single_reg.csv")rawdf_single <-read_csv(csv_file) |> janitor::clean_names()# Multiple registrations dataurl1 <-"https://github.com/BloombergGraphics/2024-h1b-immigration-data/blob/main/TRK_13139_FY2024_multi_reg.zip?raw=true"temp_zip <-tempfile(fileext =".zip")GET(url1, write_disk(temp_zip, overwrite =TRUE))# Unzip the file to a temporary directorytemp_dir <-tempdir()unzip(temp_zip, exdir = temp_dir)# Read the CSV file into Rcsv_file <-file.path(temp_dir, "TRK_13139_FY2024_multi_reg.csv")rawdf_multi <-read_csv(csv_file) |> janitor::clean_names()# Clean up temporary filesunlink(temp_zip) # Delete the temporary zip file# Remove the temporary directory and its contents# unlink(temp_dir, recursive = TRUE) rm(csv_file, temp_dir, temp_zip, url, url1)print(object.size(rawdf_single), units ="Mb")print(object.size(rawdf_multi), units ="Mb")