We try out the Validation Set approach using Auto data set, and predict mpg using horsepower.
library(ISLR)set.seed(1)data(Auto)attach(Auto)library(tidyverse)library(kableExtra)# Create a train vector, to create a random sample as "Training Set".train <-sample(1:392, size =196, replace =FALSE)# Create a linear regression.fit.lm <-lm(mpg ~ horsepower, data = Auto, subset = train)pred.lm <-predict(fit.lm, newdata = Auto[-train, ])MSE.lin <-mean((pred.lm - Auto$mpg[-train])^2)MSE.lin
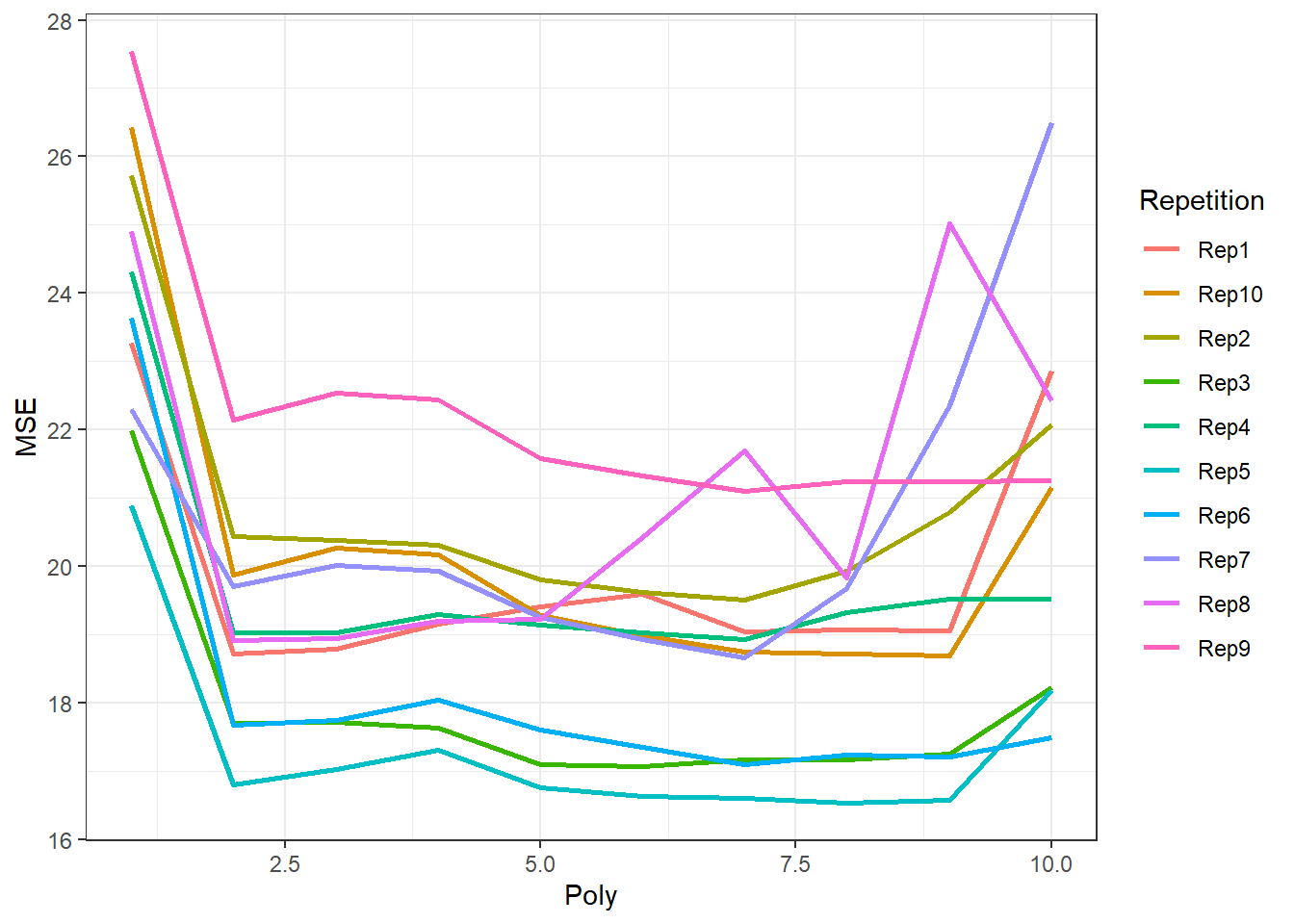
These results show that a quadratic fit is much better than linear fit, but the fits of higher order are not significantly better as MSE stays the same.
# Attempt to reproduce graph in Figure 5.2 (right hand side panel)ResultLong <-gather(Result, key ="Poly", value ="MSE", -Repetition)ResultLong <- ResultLong %>%mutate(Poly =parse_number(Poly)) %>%mutate(Repetition =paste0("Rep", Repetition, sep =""))ggplot(data = ResultLong) +geom_line(aes(x = Poly, y = MSE, color = Repetition), lwd =1) +theme(legend.position ="none") +theme_bw()
5.3.2 Leave-One-Out Cross Validation (LOOCV)
Perform LOOCV using cv.glm function of the boot library.
X Y
Min. :-2.43276 Min. :-2.72528
1st Qu.:-0.88847 1st Qu.:-0.88572
Median :-0.26889 Median :-0.22871
Mean :-0.07713 Mean :-0.09694
3rd Qu.: 0.55809 3rd Qu.: 0.80671
Max. : 2.46034 Max. : 2.56599
# Creating a function with an index which can then be use for the boot function# alpha.fn to return alpha with lowest variancealpha.fn <-function(data, index){ X <- data$X[index] Y <- data$Y[index]return((var(Y) -cov(X,Y)) / (var(X) +var(Y) -2*cov(X,Y) ) )}# Using alpha.fn to find alpha using the full data setalpha.fn(Portfolio, 1:100)
[1] 0.5758321
# Using alpha.fn to find alpha using a random sample of 100 with replacementset.seed(2)alpha.fn(Portfolio, sample(100, 100, replace =TRUE))
[1] 0.5539577
# We can repeat this many many times using different seed. Or,# We can use boot() function to automate thislibrary(boot)boot(Portfolio, alpha.fn, R =1000)
Estimating the accuracy of a linear regression model
# Comparing coefficients from a linear regression of mpg onto horsepower,# from standard least squares regression and bootstrap methods.# Creating a function to be used in bootstrap which computes output i.e. coefficients# of interest, and takes in an index vector as input.boot.fn <-function(data, index) {return(coef(lm(mpg ~ horsepower, data = data, subset = index)))}# Testing the boot.fn on the entire Auto data setboot.fn(Auto, 1:392)
(Intercept) horsepower
39.9358610 -0.1578447
# Getting coefficient estimates using a random sample of 392 with replacementboot.fn(Auto, sample(392, 392, replace =TRUE))
(Intercept) horsepower
39.5910901 -0.1524194
boot.fn(Auto, sample(392, 392, replace =TRUE))
(Intercept) horsepower
41.1261106 -0.1690852
# We can repeat this command a thousand times, or# Use bootstrap to automate this processboot(data = Auto, statistic = boot.fn, R =1000)
# Compare these with standard errors from least squares estimatessummary(lm(mpg ~ horsepower, data = Auto))$coef
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.9358610 0.717498656 55.65984 1.220362e-187
horsepower -0.1578447 0.006445501 -24.48914 7.031989e-81
Now, we perform bootstrap to compare standard errors from least squares estimates of linear regression of mpg on quadratic form of horsepower, and standard errors computed using bootstrap.
# creating a boot.fn to be used in boot() laterboot.fn <-function(data, index){return(coefficients(lm(mpg ~ horsepower +I(horsepower^2), data = data, subset = index)))}boot.fn(Auto, 1:392)