Code
library(sf) # Handling Simple Features in R
library(terra) # Handling Rasters in R
library(tidyverse) # Data Wrangling
library(spData) # Spatial Data-setsKey Learnings from, and Solutions to the exercises in Chapter 3 of the book Geocomputation with R by Robin Lovelace, Jakub Nowosad and Jannes Muenchow.
library(sf) # Handling Simple Features in R
library(terra) # Handling Rasters in R
library(tidyverse) # Data Wrangling
library(spData) # Spatial Data-setssf Package:
data.frame with a geometry column (sfc class) for spatial features (points, lines, polygons).geometry or geom, but customizable.Manipulation Methods:
methods(class = "sf") |>
as_tibble() |>
rename(methods = x) |>
mutate(methods = str_replace_all(methods, ",sf", " ")) |>
mutate(methods = str_replace_all(methods, ".sf", " ")) |>
gt::gt() |>
gt::tab_header(
title = "Methods available"
) |>
gt::opt_interactive()Methods like aggregate(), cbind(), merge(), and rbind() work seamlessly with sf objects.
Compatible with tidyverse functions (dplyr, tidyr) and can be used with data.table (partial compatibility noted in issue #2273).
Dropping geometry (st_drop_geometry()) can speed up attribute data operations when spatial data is not required.
# Original 'world' dataset
dim(world)
## [1] 177 11
class(world)
## [1] "sf" "tbl_df" "tbl" "data.frame"
# Dropping the geometry column: Effects
st_drop_geometry(world) |>
dim()
## [1] 177 10
st_drop_geometry(world) |>
class()
## [1] "tbl_df" "tbl" "data.frame"Advantages:
sf’s integration with the tidyverse allows robust, efficient data manipulation.dplyr), making it versatile for data analysis.Major Pitfalls of Using Spatial Data with the Tidyverse
select() from dplyr can mask similar functions from the raster package.dplyr::select()) to avoid conflicts.sp Package
sp package does not integrate well with tidyverse functions.sp to sf object types using functions like st_as_sf().st_cast(to = "POLYGON").Verbose syntax when using tidyverse functions like filter() with spatial predicates like st_intersects().
May result in altered row names, complicating joins and comparisons.
Other option is spatial subsetting using base R
lnd_buff = lnd[1, ] %>%
st_transform(crs = 27700) %>% # uk CRS
st_buffer(500000) %>%
st_transform(crs = 4326)
near_lnd = world[lnd_buff, ]
world_poly = world %>%
st_cast(to = "POLYGON")
near_lnd_new = world_poly[lnd_buff, ]
near_lnd_tidy = world %>%
filter(st_intersects(., lnd_buff, sparse = FALSE))filter() vs base R subsetting ([]).bind_rows()
bind_rows() fails on spatial objects; use alternatives like setting geometries to NULL with st_set_geometry() before combining.raster data is minimal.tabularaster, sfraster, and stars aim to enhance support.Uses [ operator and subset() function for rows and columns selection.
Syntax: object[i, j] returns rows indexed by i and columns by j.
dplyr Sub-setting Functions:
filter() and slice() for rows, select() for columns.
select(): Subsets columns by name or position.
Helper functions in select() like contains(), starts_with(), num_range().
pull() (dplyr), $, or [[ (base R).slice(): Selects rows by index.
filter(): Filters rows based on conditions.
filter(): <, >, <=, >=, ==, !=.The dplyr functions (filter(), select(), pull()) are intuitive and integrate well with the tidyverse workflows.
%>% (from the magrittr package) and native |> (from R 4.1.0 onwards) enable chaining commands, improving readability and flow of code.aggregate():
aggregate() groups data and applies a function (e.g., sum). Result: A non-spatial data frame with two columns (continent, pop).aggregate.sf():
sf), use aggregate() with by argument. This results in an sf object with eight features representing continents.dplyr Approach
group_by() and summarize():
Equivalent to aggregate(), but offers flexibility and control:
group_by() defines grouping variables.summarize() applies aggregation functions.library(dplyr)
world |>
group_by(continent) |>
summarize(pop = sum(pop, na.rm = TRUE))Simple feature collection with 8 features and 2 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -180 ymin: -89.9 xmax: 180 ymax: 83.64513
Geodetic CRS: WGS 84
# A tibble: 8 × 3
continent pop geom
<chr> <dbl> <GEOMETRY [°]>
1 Africa 1154946633 MULTIPOLYGON (((36.86623 22, 36.69069 22.2…
2 Antarctica 0 MULTIPOLYGON (((-180 -89.9, 180 -89.9, 180…
3 Asia 4311408059 MULTIPOLYGON (((36.14976 35.82153, 35.9050…
4 Europe 669036256 MULTIPOLYGON (((26.29 35.29999, 25.74502 3…
5 North America 565028684 MULTIPOLYGON (((-82.26815 23.18861, -82.51…
6 Oceania 37757833 MULTIPOLYGON (((166.7932 -15.66881, 167.00…
7 Seven seas (open ocean) 0 POLYGON ((68.935 -48.625, 68.8675 -48.83, …
8 South America 412060811 MULTIPOLYGON (((-66.95992 -54.89681, -66.4…summarize() from the dplyr package vignettes.dplyr functions are highly effective when applied to grouped data frames (grouped_df objects). Here are the main points covered:
Grouping Data: Use group_by() to create groups within a data frame based on one or more variables.
tally().Accessing Group Metadata:
group_keys(): Shows underlying group data. Details here.group_vars(): Retrieves names of the grouping variables. Details here.Modifying Groups:
Verbs and Grouping:
summarise(): Computes summary statistics per group. The .groups argument controls grouping structure. More on summarise().Column Manipulation:
select() retains grouping variables by default. More on select().rename() and relocate() function the same way for grouped and ungrouped data. Details here.Sorting Groups:
arrange(): Sorts data, with .by_group = TRUE option to sort within groups. More on arrange().Joining involves combining tables based on a shared key variable. In R, dplyr functions like left_join() and inner_join() are commonly used for this purpose.
dplyr (left_join, inner_join, etc.) follow conventions from SQL, allowing easy and consistent data merging.data.frame) and spatial (sf) objects. The geometry list column in sf objects is the key difference.When merging an sf object with a data.frame
sf object, keeping its spatial features intact while adding new columns for coffee production.Handling Key Variables:
name_long), joining works automatically.by argument to specify the joining variables explicitly.Inner Joins:
Troubleshooting Joins:
setdiff().stringr package to identify correct key names for adjustments.Reversing Joins:
sf object.data.frame (tibble), unless explicitly converted to an sf object using st_as_sf().Further Resources:
Chapter 13 on Relational Data in R for Data Science by Grolemund and Wickham (2016)
The documentation describing joins with data.table package.
The join vignette in the geocompkg package, which is summarized below: —
Spatial Joins Extended
Case: If key columns have different names, use a named vector to specify the keys
Issue: Duplicate columns (e.g., tbl_1_var.x and tbl_2_var.y). Resolved by specifying all keys.
st_drop_geometry() removes spatial attributes, allowing joins with standard data frames.mutate() from dplyr. Example: population / area.mutate() to add the new column without overwriting the geometry column.unite() from tidyr to merge two or more columns into one (e.g., continent and region_un).unite() allows setting a separator (e.g., :) and can optionally remove the original columns.separate_wider_position() and separate_wider_delim()from tidyr to split a combined column back into its original components.rename() from dplyr for renaming specific columns.setNames() with a character vector for new names.st_drop_geometry() to drop the spatial information while retaining the attributes in a non-spatial data.frame. This method is preferred over manually selecting non-geometry columns as it avoids unintended issues.rast() function to create raster objects.vals argument assigns numeric values to each cell.clay, silt, sand).cats().levels().coltab() to view or set color tables.Raster Subsetting:
[ , ].Examples:
# A simple raster
elev <- rast(
nrows = 10, ncols = 10,
xmin = -1.5, xmax = 1.5, ymin = -1.5, ymax = 1.5,
vals = 1:100
)
# A raster with categorical levels
grain <- rast(
nrows = 10, ncols = 10,
xmin = -1.5, xmax = 1.5, ymin = -1.5, ymax = 1.5,
vals = sample(
x = c("Wheat", "Rice", "Maize", "Others"),
size = 100,
replace = TRUE
)
)
# Print the "elev" object to visualize the design
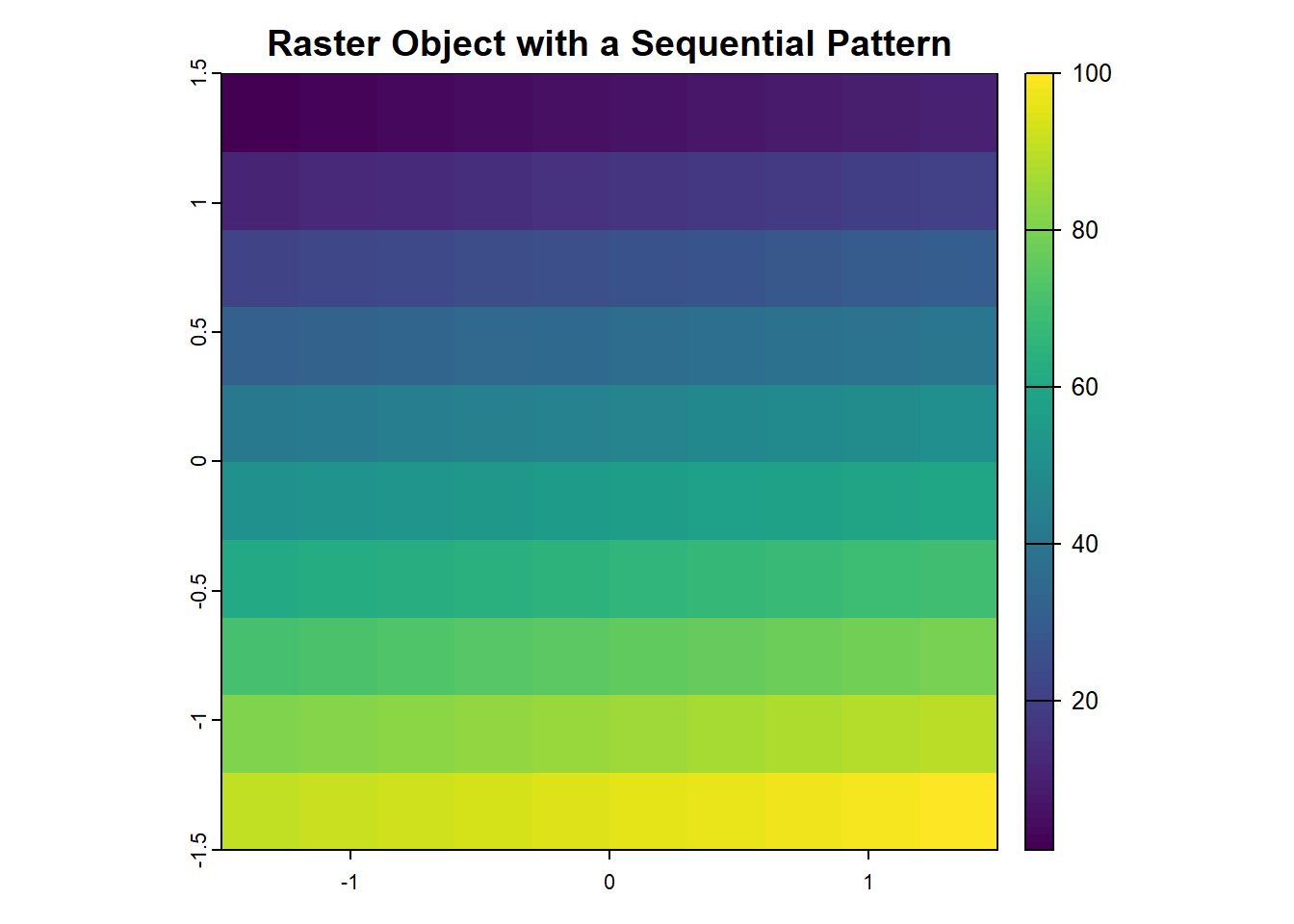
print(elev)
## class : SpatRaster
## dimensions : 10, 10, 1 (nrow, ncol, nlyr)
## resolution : 0.3, 0.3 (x, y)
## extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (CRS84) (OGC:CRS84)
## source(s) : memory
## name : lyr.1
## min value : 1
## max value : 100
# Plot the raster object to visualize the matrix as an image
plot(
elev,
main = "Raster Object with a Sequential Pattern"
)
# Accessing using row number and column number
elev[1, 1]
## lyr.1
## 1 1
elev[10,5]
## lyr.1
## 1 95
plot(
grain,
main = "Raster Object with 4 categorical levels"
)
# Accessing using row number and column number
grain[1,1]
## lyr.1
## 1 Rice
grain[10, 10]
## lyr.1
## 1 Others
# A multilayered raster - combining both
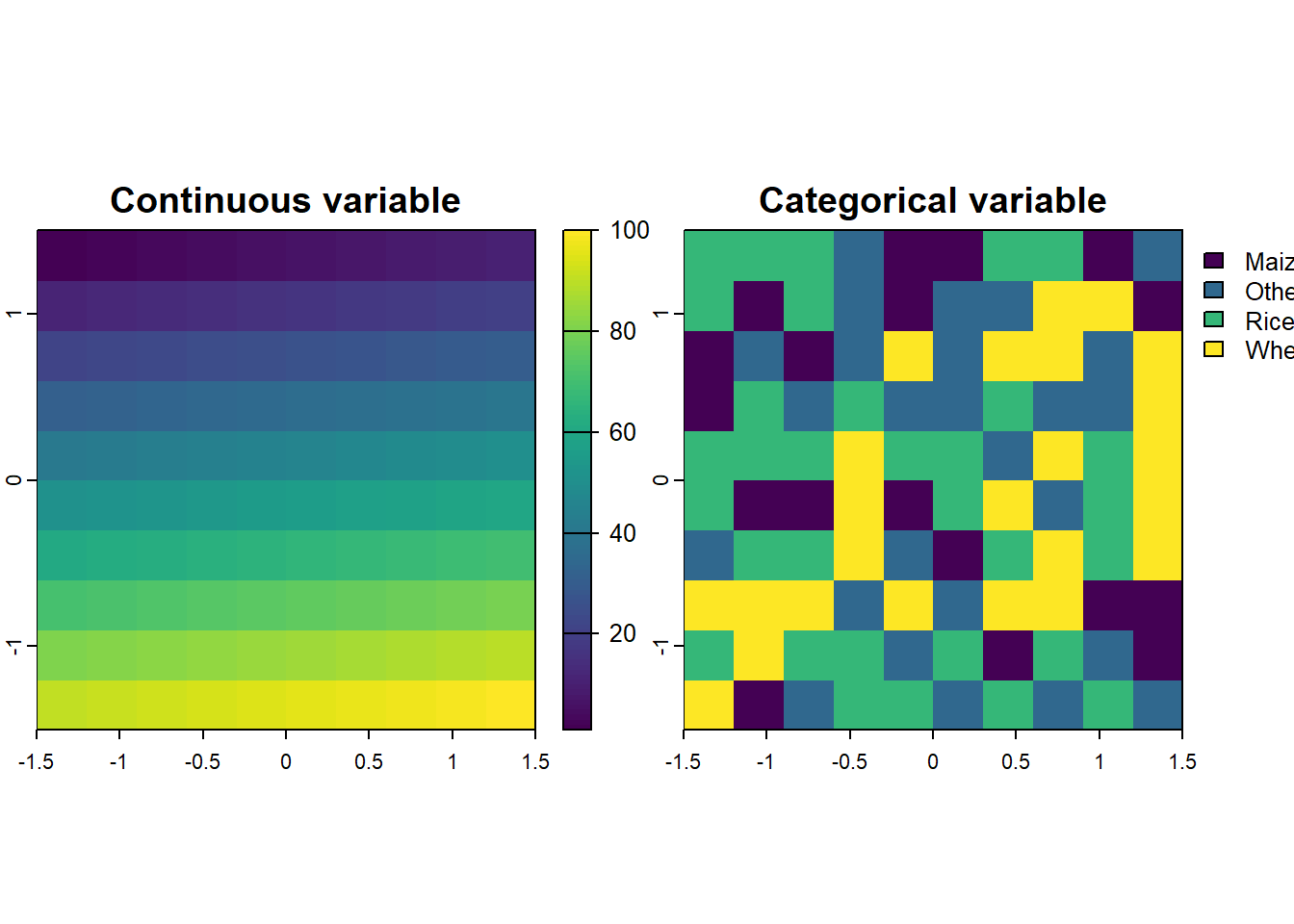
two_layers <- c(elev, grain)
print(two_layers)
## class : SpatRaster
## dimensions : 10, 10, 2 (nrow, ncol, nlyr)
## resolution : 0.3, 0.3 (x, y)
## extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (CRS84) (OGC:CRS84)
## source(s) : memory
## names : lyr.1, lyr.1
## min values : 1, Maize
## max values : 100, Wheat
names(two_layers) <- c("Continuous variable",
"Categorical variable")
plot(
two_layers
)
# Accessing raster values using cell ID
elev[1]
## lyr.1
## 1 1
elev[95]
## lyr.1
## 1 95Subsetting Multi-layered Rasters:
two_layers = c(grain, elev)), subsetting returns values from each layer:two_layers[1] Continuous variable Categorical variable
1 1 Rice# Extracting all values - single layer raster
elev[][1:10] [1] 1 2 3 4 5 6 7 8 9 10# It is Equivalent to using the values() function
values(elev)[1:10] [1] 1 2 3 4 5 6 7 8 9 10# Extracting all values - multi-layer raster
# It returns a data.frame
values(two_layers) |>
as_tibble()# A tibble: 100 × 2
`Continuous variable` `Categorical variable`
<int> <int>
1 1 3
2 2 3
3 3 3
4 4 2
5 5 1
6 6 1
7 7 3
8 8 3
9 9 1
10 10 2
# ℹ 90 more rowsModifying Raster Values:
elev[5, 5] = 0 # Sets the value of the 1 central cells to 0
plot(elev)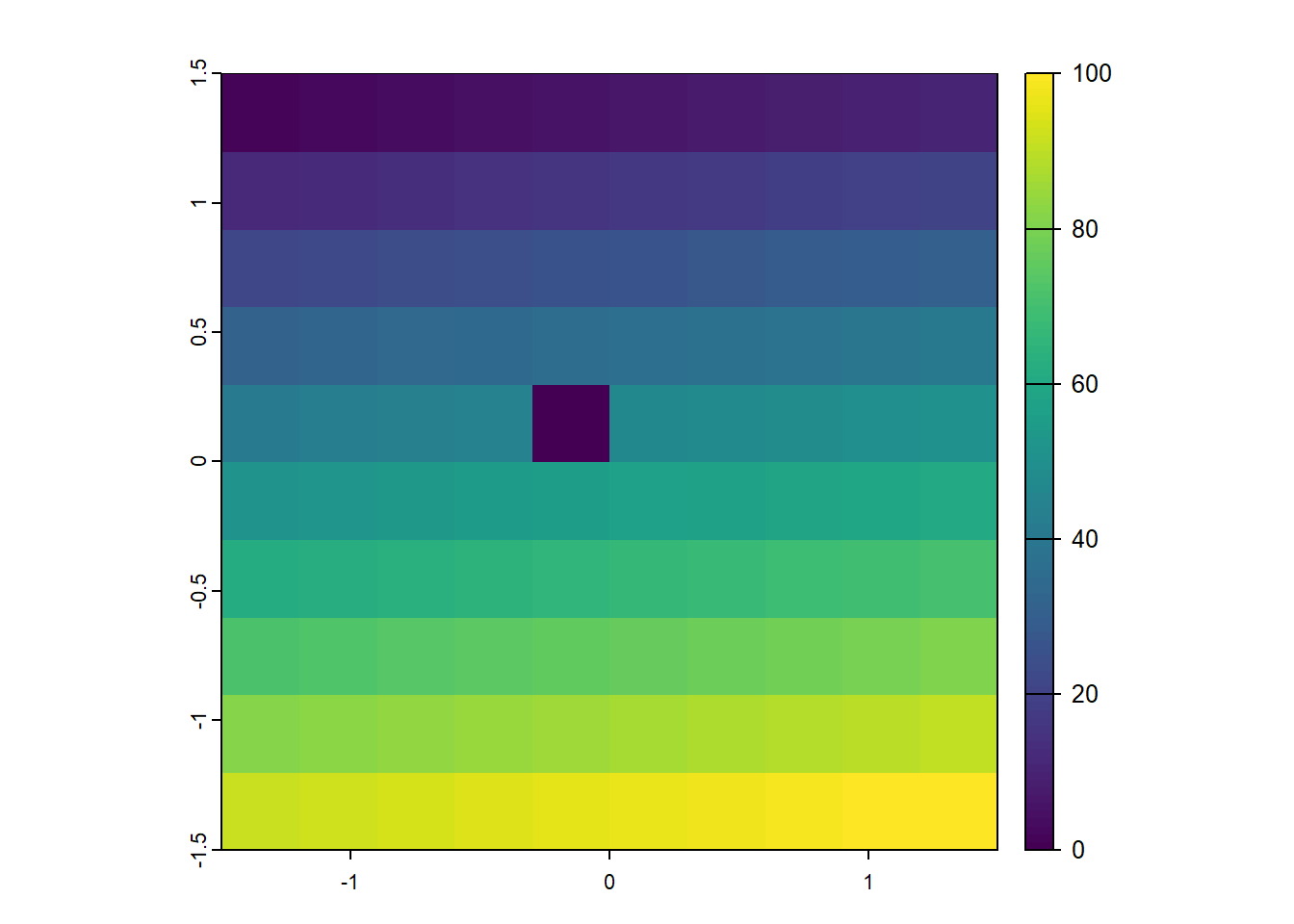
elev[5, c(5,6)] = 0 # Sets the value of the central 2 cells to 0
plot(elev)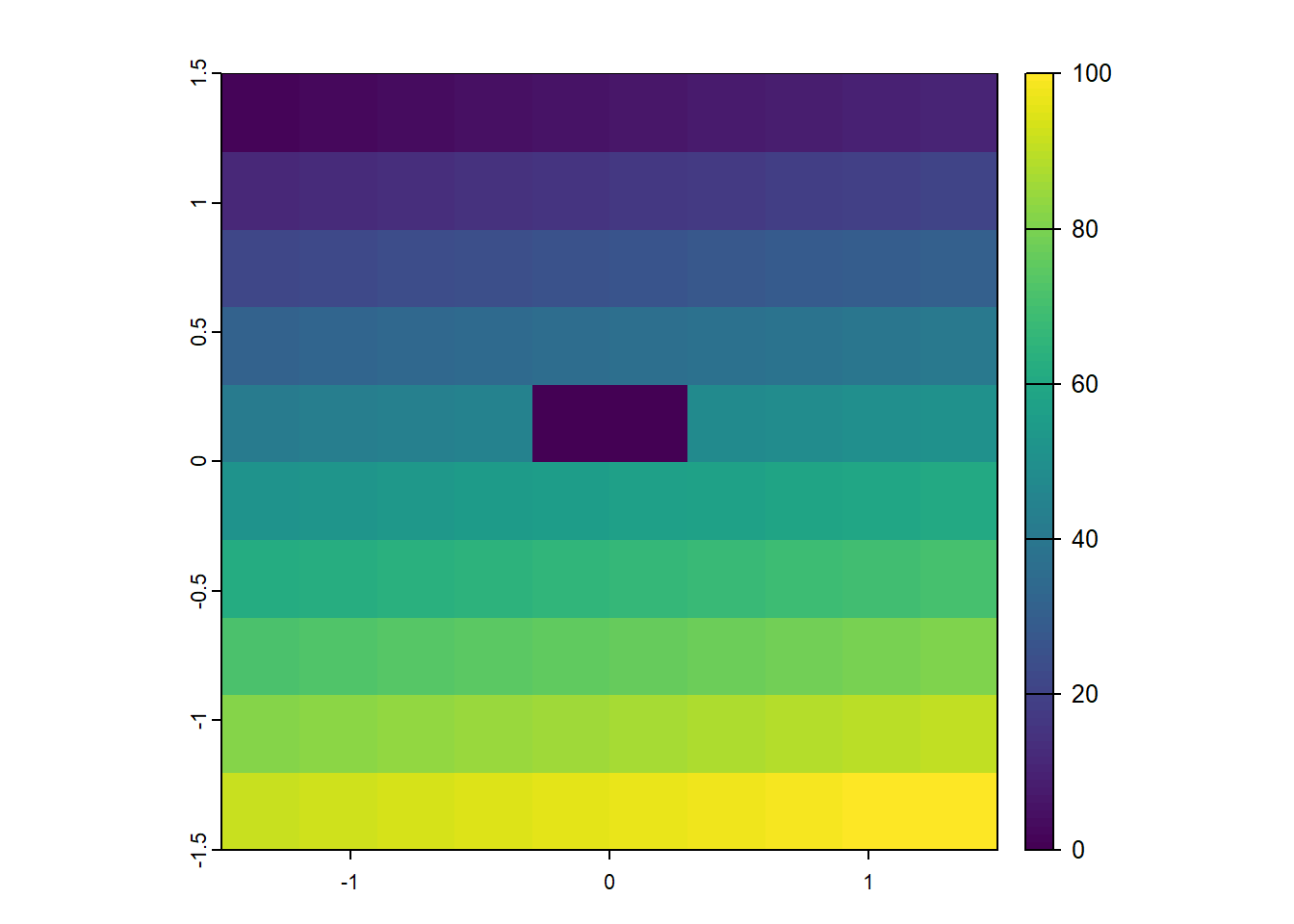
Replacing Values in Multi-layered Rasters:
# Assigns new values for Cell ID 1 in both layers
two_layers[45] = cbind(c(1), c(4))
plot(two_layers)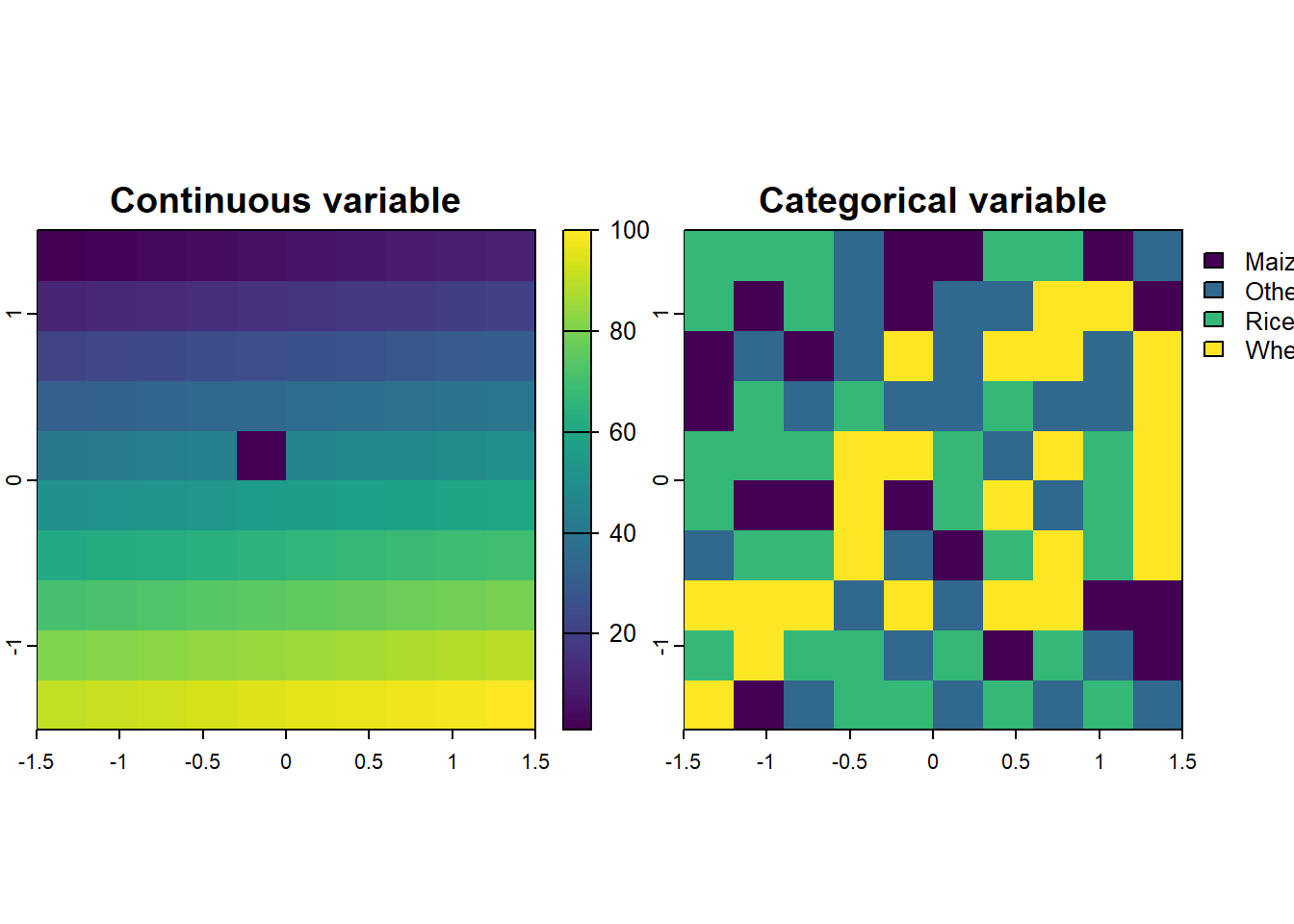
This subsetting approach allows efficient extraction and manipulation of raster cell values, enabling the customization of raster datasets for specific analytical needs.
summary() function provides detailed statistics:
summary(two_layers)
## Continuous.variable Categorical.variable
## Min. : 1.00 Maize :18
## 1st Qu.: 24.75 Others:26
## Median : 50.50 Rice :31
## Mean : 50.06 Wheat :25
## 3rd Qu.: 75.25
## Max. :100.00global() function calculates additional statistics like standard deviation and can be used to apply custom summary statistics.global(two_layers, sum) sum
Continuous variable 5006
Categorical variable 263global(two_layers, mean) mean
Continuous variable 50.06
Categorical variable 2.63freq() function generates a frequency table for categorical raster values, showing counts of each category.freq(two_layers$`Categorical variable`) |>
gt::gt() |>
gtExtras::gt_theme_538()| layer | value | count |
|---|---|---|
| 1 | Maize | 18 |
| 1 | Others | 26 |
| 1 | Rice | 31 |
| 1 | Wheat | 25 |
extract()) exist in multiple packages like terra and tidyr, leading to conflicts.tidyr::extract()).
detach() to unload conflicting packages, but be cautious as it may impact dependent packages.library(sf)
library(dplyr)
library(terra)
library(spData)
data(us_states)
data(us_states_df)Create a new object called us_states_name that contains only the NAME column from the us_states object using either base R ([) or tidyverse (select()) syntax. What is the class of the new object and what makes it geographic?
us_states_name <- us_states |>
select(NAME)
class(us_states_name)[1] "sf" "data.frame"The new object of the class sf, and the stickiness of the geometry column makes it a geographical dataset.
Select columns from the us_states object which contain population data. Obtain the same result using a different command (bonus: try to find three ways of obtaining the same result). Hint: try to use helper functions, such as contains or matches from dplyr (see ?contains).
us_states |>
select(contains("pop"))
us_states |>
select(where(is.double)) |>
select(-AREA)
us_states |>
select(5:6)The above three methods all select the columns total_pop_10 and total_pop_15 . Notice that the column geometry is sticky, and can be removed using st_drop_geometry().
Find all states with the following characteristics (bonus: find and plot them):
Belong to the Midwest region.
The code shown below gives out the names of all such states.
us_states |>
filter(REGION == "Midwest") |>
pull(NAME) |>
paste(collapse = ", ")[1] "Indiana, Kansas, Minnesota, Missouri, North Dakota, South Dakota, Illinois, Iowa, Michigan, Nebraska, Ohio, Wisconsin"Belong to the West region, have an area below 250,000 km2and in 2015 a population greater than 5,000,000 residents (hint: you may need to use the function units::set_units() or as.numeric()).
Only Washington State qualifies all three conditions. Code is shown below.
us_states |>
filter(REGION == "West") |>
filter(total_pop_15 > 5e6) |>
filter(as.numeric(AREA) < 250000)Simple feature collection with 1 feature and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -124.7042 ymin: 45.54774 xmax: -116.916 ymax: 49.00236
Geodetic CRS: NAD83
GEOID NAME REGION AREA total_pop_10 total_pop_15
1 53 Washington West 175436 [km^2] 6561297 6985464
geometry
1 MULTIPOLYGON (((-122.7699 4...us_states |>
filter(REGION == "West") |>
filter(total_pop_15 > 5e6) |>
filter(AREA < units::set_units(250000, "km2"))Simple feature collection with 1 feature and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -124.7042 ymin: 45.54774 xmax: -116.916 ymax: 49.00236
Geodetic CRS: NAD83
GEOID NAME REGION AREA total_pop_10 total_pop_15
1 53 Washington West 175436 [km^2] 6561297 6985464
geometry
1 MULTIPOLYGON (((-122.7699 4...Belong to the South region, had an area larger than 150,000 km2 and a total population in 2015 larger than 7,000,000 residents.
The states that fulfil these conditions are Florida, Georgia and Texas.
us_states |>
filter(REGION == "South") |>
filter(AREA > units::set_units(150000, "km2")) |>
filter(total_pop_15 > 7e6) |>
pull(NAME)[1] "Florida" "Georgia" "Texas" What was the total population in 2015 in the us_states dataset? What was the minimum and maximum total population in 2015?
The total population in the us_states dataset in the year 2015 was 314,375,347. The minimum total population in 2015 was 579,679 (Wyoming), and the maximum total population was 38,421,464 (California).
us_states |>
st_drop_geometry() |>
as_tibble() |>
summarise(
total_pop_15 = sum(total_pop_15)
)
## # A tibble: 1 × 1
## total_pop_15
## <dbl>
## 1 314375347
us_states |>
st_drop_geometry() |>
slice_min(order_by = total_pop_15, n = 1)
## GEOID NAME REGION AREA total_pop_10 total_pop_15
## 1 56 Wyoming West 253309.6 [km^2] 545579 579679
us_states |>
st_drop_geometry() |>
slice_max(order_by = total_pop_15, n = 1)
## GEOID NAME REGION AREA total_pop_10 total_pop_15
## 1 06 California West 409747.1 [km^2] 36637290 38421464How many states are there in each region?
The number of states in each region are shown in Table 3 below.
us_states |>
st_drop_geometry() |>
count(REGION, name = "Number of States") |>
gt::gt() |>
gtExtras::gt_theme_538()| REGION | Number of States |
|---|---|
| Norteast | 9 |
| Midwest | 12 |
| South | 17 |
| West | 11 |
What was the minimum and maximum total population in 2015 in each region? What was the total population in 2015 in each region?
The minimum and maximum total population in 2015 in each region is shown in Table 4 (a). The total population in each region in 2015 is shown in Table 4 (b).
us_states |>
as_tibble() |>
group_by(REGION) |>
slice_min(order_by = total_pop_15, n = 1) |>
select(REGION, NAME, total_pop_15) |>
ungroup() |>
gt::gt() |>
gt::fmt_number(
columns = total_pop_15,
decimals = 0
) |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gtExtras::gt_theme_538()
us_states |>
as_tibble() |>
group_by(REGION) |>
summarise(
total_population_2015 = sum(total_pop_15)
) |>
select(REGION, total_population_2015) |>
ungroup() |>
gt::gt() |>
gt::fmt_number(
columns = total_population_2015,
decimals = 0
) |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gtExtras::gt_theme_538()| Region | Name | Total Pop 15 |
|---|---|---|
| Norteast | Vermont | 626,604 |
| Midwest | North Dakota | 721,640 |
| South | District of Columbia | 647,484 |
| West | Wyoming | 579,679 |
| Region | Total Population 2015 |
|---|---|
| Norteast | 55,989,520 |
| Midwest | 67,546,398 |
| South | 118,575,377 |
| West | 72,264,052 |
Add variables from us_states_df to us_states, and create a new object called us_states_stats. What function did you use and why? Which variable is the key in both datasets? What is the class of the new object?
The function we use to accomplish this task is left_join() and the key in both datasets are the state names, called NAME in us_states dataset, and state in us_states_df dataset.
The class of the new object depends on which object is used first on the left_join() function, if us_states (an sf object) is used first, the class of new object is sf . However, if the us_states_df (a data frame) is used first, the resulting object is a data.frame or tibble.
us_states |>
left_join(us_states_df, by = join_by(NAME == state)) |>
class()
## [1] "sf" "data.frame"
us_states_df |>
left_join(us_states, by = join_by(state == NAME)) |>
class()
## [1] "tbl_df" "tbl" "data.frame"us_states_df has two more rows than us_states. How can you find them? (Hint: try to use the dplyr::anti_join() function.)
The two rows that more more in us_states_df are shown below: —
us_states_df |>
anti_join(us_states, by = join_by(state == NAME)) |>
gt::gt() |>
gtExtras::gt_theme_538() |>
gt::cols_label_with(fn = snakecase::to_title_case)us_states_df
| State | Median Income 10 | Median Income 15 | Poverty Level 10 | Poverty Level 15 |
|---|---|---|---|---|
| Alaska | 29509 | 31455 | 64245 | 72957 |
| Hawaii | 29945 | 31051 | 124627 | 153944 |
What was the population density in 2015 in each state? What was the population density in 2010 in each state?
The Table 6 shows the population density.
us_states |>
st_drop_geometry() |>
as_tibble() |>
mutate(
population_density_2010 = total_pop_10 / as.numeric(AREA),
population_density_2015 = total_pop_15 / as.numeric(AREA),
.keep = "unused"
) |>
select(-GEOID) |>
gt::gt() |>
gt::opt_interactive() |>
gtExtras::gt_theme_espn() |>
gt::fmt_number(
decimals = 1
) |>
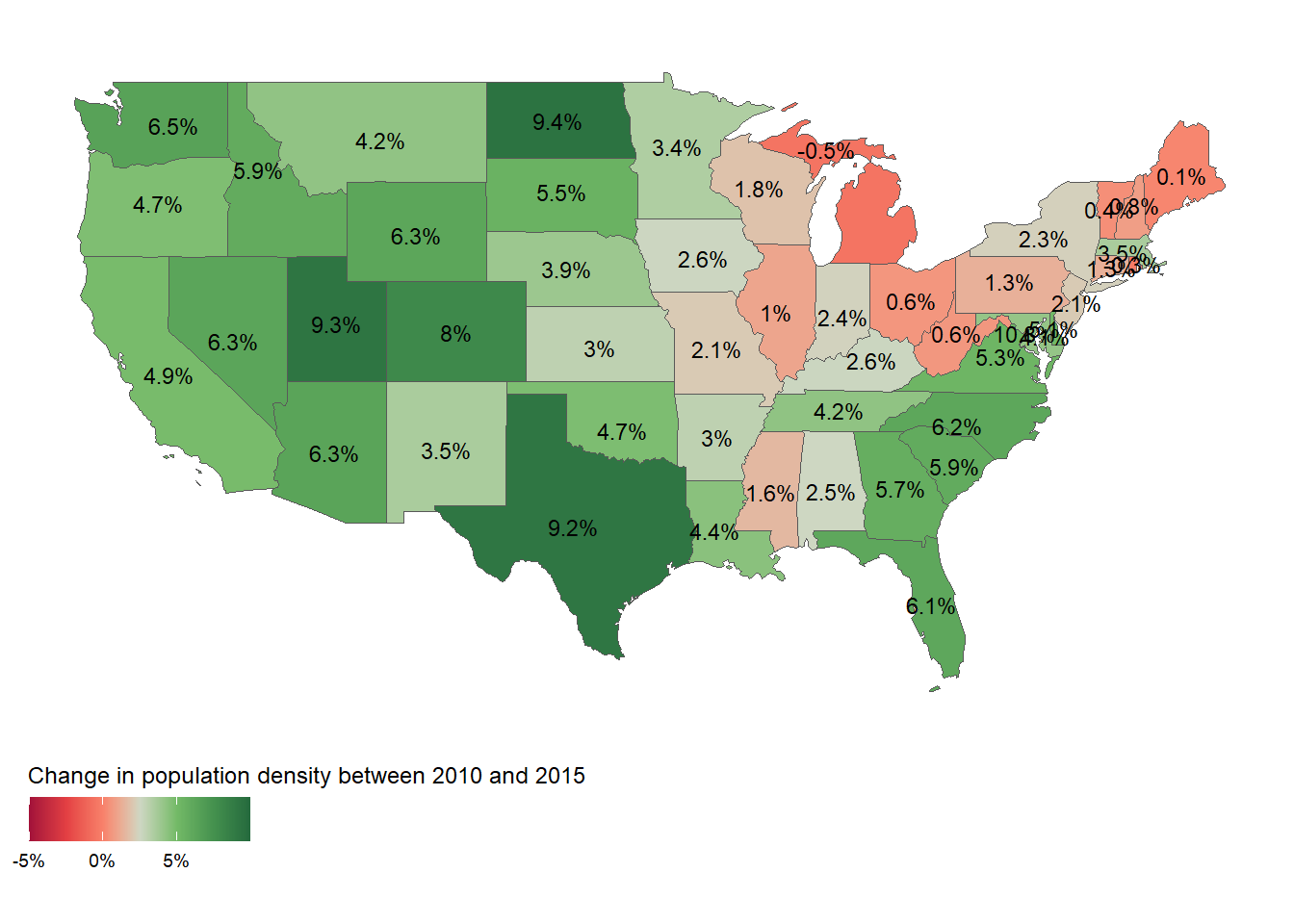
gt::cols_label_with(fn = snakecase::to_title_case)How much has population density changed between 2010 and 2015 in each state? Calculate the change in percentages and map them.
The Table 7 shows how much the population density has changed between 2010 and 2015 in each state. The Figure 1 shows the percentage change in a map of the US.
us_states |>
st_drop_geometry() |>
as_tibble() |>
mutate(
population_density_2010 = total_pop_10 / as.numeric(AREA),
population_density_2015 = total_pop_15 / as.numeric(AREA),
change_in_density = (population_density_2015 - population_density_2010)/population_density_2010,
.keep = "unused"
) |>
select(-GEOID) |>
gt::gt() |>
gt::opt_interactive() |>
gtExtras::gt_theme_espn() |>
gt::fmt_number(
decimals = 1
) |>
gt::fmt_percent(
columns = change_in_density
) |>
gt::cols_label_with(fn = snakecase::to_title_case)us_states |>
mutate(
population_density_2010 = total_pop_10 / as.numeric(AREA),
population_density_2015 = total_pop_15 / as.numeric(AREA),
change_in_density = (population_density_2015 - population_density_2010)/population_density_2010,
.keep = "unused"
) |>
ggplot() +
geom_sf(
mapping = aes(
fill = change_in_density
)
) +
geom_sf_text(
mapping = aes(
label = paste0(
round(
change_in_density * 100,
1
),
"%"
)
),
size = 3
) +
paletteer::scale_fill_paletteer_c(
"ggthemes::Red-Green Diverging",
labels = scales::label_percent(),
name = "Change in population density between 2010 and 2015",
limits = c(-0.05, 0.1)
) +
ggthemes::theme_map() +
theme(
legend.position = "bottom",
legend.title.position = "top"
)
Change the columns’ names in us_states to lowercase. (Hint: helper functions - tolower() and colnames() may help.)
A very easy method is using the janitor package and the function clean_names()
us_states |>
janitor::clean_names() |>
as_tibble() |>
print(n = 5)# A tibble: 49 × 7
geoid name region area total_pop_10 total_pop_15 geometry
<chr> <chr> <fct> [km^2] <dbl> <dbl> <MULTIPOLYGON [°]>
1 01 Alaba… South 1.34e5 4712651 4830620 (((-88.20006 34.99563, -…
2 04 Arizo… West 2.95e5 6246816 6641928 (((-114.7196 32.71876, -…
3 08 Color… West 2.70e5 4887061 5278906 (((-109.0501 41.00066, -…
4 09 Conne… Norte… 1.30e4 3545837 3593222 (((-73.48731 42.04964, -…
5 12 Flori… South 1.51e5 18511620 19645772 (((-81.81169 24.56874, -…
# ℹ 44 more rowsUsing us_states and us_states_df create a new object called us_states_sel. The new object should have only two variables: median_income_15 and geometry. Change the name of the median_income_15 column to Income.
The new object us_states_sel is created as shown below.
us_states_sel <- us_states |>
left_join(us_states_df, by = join_by(NAME == state)) |>
select(Income = median_income_15, geometry)
us_states_selSimple feature collection with 49 features and 1 field
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -124.7042 ymin: 24.55868 xmax: -66.9824 ymax: 49.38436
Geodetic CRS: NAD83
First 10 features:
Income geometry
1 22890 MULTIPOLYGON (((-88.20006 3...
2 26156 MULTIPOLYGON (((-114.7196 3...
3 30752 MULTIPOLYGON (((-109.0501 4...
4 33226 MULTIPOLYGON (((-73.48731 4...
5 24654 MULTIPOLYGON (((-81.81169 2...
6 25588 MULTIPOLYGON (((-85.60516 3...
7 23558 MULTIPOLYGON (((-116.916 45...
8 25834 MULTIPOLYGON (((-87.52404 4...
9 27315 MULTIPOLYGON (((-102.0517 4...
10 24014 MULTIPOLYGON (((-92.01783 2...Calculate the change in the number of residents living below the poverty level between 2010 and 2015 for each state. (Hint: See ?us_states_df for documentation on the poverty level columns.) Bonus: Calculate the change in the percentage of residents living below the poverty level in each state.
The Table 8 shows the change in the number of residents living below the poverty level between 2010 and 2015 for each state.
us_states_df |>
mutate(
change_in_poverty = poverty_level_15 - poverty_level_10
) |>
select(state, change_in_poverty) |>
gt::gt() |>
gt::fmt_number(decimals = 0) |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gt::opt_interactive() The Table 9 shows the change in the percentage of residents living below the poverty level in each state.
us_states |>
st_drop_geometry() |>
left_join(us_states_df, by = join_by(NAME == state)) |>
as_tibble() |>
mutate(
state = NAME,
poverty_2010 = poverty_level_10 / total_pop_10,
poverty_2015 = poverty_level_15 / total_pop_15,
change_in_poverty = poverty_2015 - poverty_2010,
.keep = "none"
) |>
gt::gt() |>
gt::fmt_percent() |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gt::opt_interactive()What was the minimum, average and maximum state’s number of people living below the poverty line in 2015 for each region? Bonus: What is the region with the largest increase in people living below the poverty line?
The the minimum, average and maximum state’s number of people living below the poverty line in 2015 for each region are shown in Table 10 below.
us_states |>
st_drop_geometry() |>
select(state = NAME, region = REGION) |>
left_join(us_states_df) |>
as_tibble() |>
group_by(region) |>
summarise(
minimum_poverty_2015 = min(poverty_level_15),
maximum_poverty_2015 = max(poverty_level_15),
average_poverty_2015 = mean(poverty_level_15)
) |>
gt::gt() |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gt::fmt_number(decimals = 0)| Region | Minimum Poverty 2015 | Maximum Poverty 2015 | Average Poverty 2015 |
|---|---|---|---|
| Norteast | 69,233 | 3,005,943 | 804,465 |
| Midwest | 79,758 | 1,801,118 | 799,155 |
| South | 108,315 | 4,472,451 | 1,147,575 |
| West | 64,995 | 6,135,142 | 1,016,665 |
As evident in Table 11, the region with the largest increase in people living below the poverty line is the South Region.
us_states |>
st_drop_geometry() |>
select(state = NAME, region = REGION) |>
as_tibble() |>
left_join(us_states_df) |>
group_by(region) |>
summarise(
change_total_poverty = sum(poverty_level_15) - sum(poverty_level_10)
) |>
arrange(desc(change_total_poverty)) |>
gt::gt() |>
gt::cols_label_with(fn = snakecase::to_title_case) |>
gt::fmt_number(decimals = 0)| Region | Change Total Poverty |
|---|---|
| South | 2,718,396 |
| West | 2,102,479 |
| Midwest | 1,095,133 |
| Norteast | 877,493 |
Create a raster from scratch, with nine rows and columns and a resolution of 0.5 decimal degrees (WGS84). Fill it with random numbers. Extract the values of the four corner cells.
# Load the terra package
library(terra)
# Create a raster with 9 rows and 9 columns, resolution of 0.5 degrees
r <- rast(nrows = 9, ncols = 9,
resolution = 0.5,
crs = "EPSG:4326")
# Fill the raster with random numbers
values(r) <- runif(ncell(r))
# Print the raster
print(r)
## class : SpatRaster
## dimensions : 360, 720, 1 (nrow, ncol, nlyr)
## resolution : 0.5, 0.5 (x, y)
## extent : -180, 180, -90, 90 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (EPSG:4326)
## source(s) : memory
## name : lyr.1
## min value : 4.599569e-06
## max value : 9.999993e-01
plot(r)
# Extract the values of the four corner cells
# Top-left (1, 1), Top-right (1, 9), Bottom-left (9, 1),
# # Bottom-right (9, 9)
r[1,1]
## lyr.1
## 1 0.3572785
r[1,9]
## lyr.1
## 1 0.2861174
r[9,1]
## lyr.1
## 1 0.2665531
r[9,9]
## lyr.1
## 1 0.5069412What is the most common class of our example raster grain?
grain_order <- c("clay", "silt", "sand")
grain_char <- sample(grain_order, 36, replace = TRUE)
grain_fact <- factor(grain_char, levels = grain_order)
grain <-rast(nrows = 6, ncols = 6,
xmin = -1.5, xmax = 1.5,
ymin = -1.5, ymax = 1.5,
vals = grain_fact)
answer <- freq(grain) |>
arrange(desc(count))
gt::gt(answer) |>
gt::cols_label_with(fn = snakecase::to_title_case)grain.
| Layer | Value | Count |
|---|---|---|
| 1 | silt | 14 |
| 1 | clay | 13 |
| 1 | sand | 9 |
The most common class is the silt .
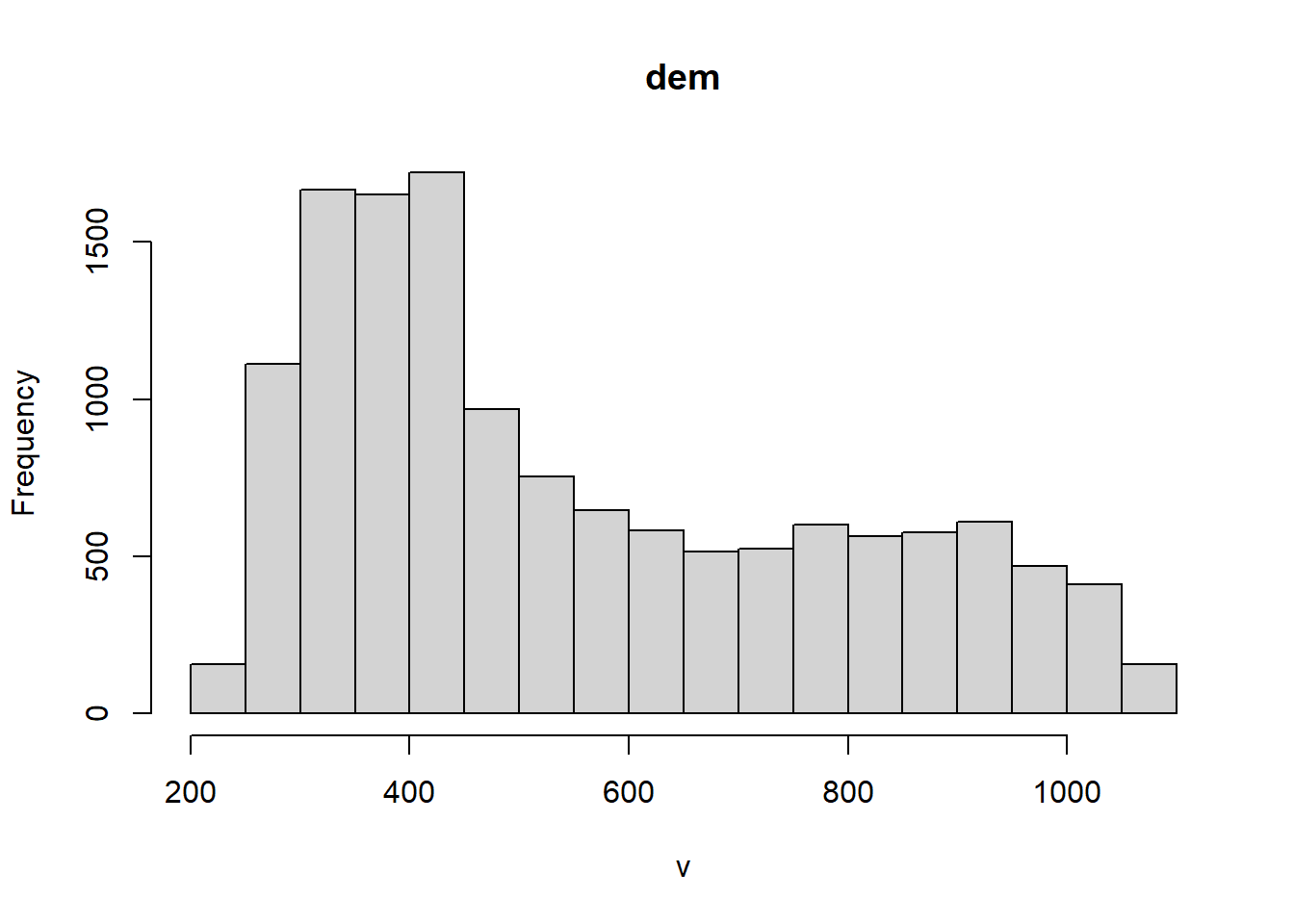
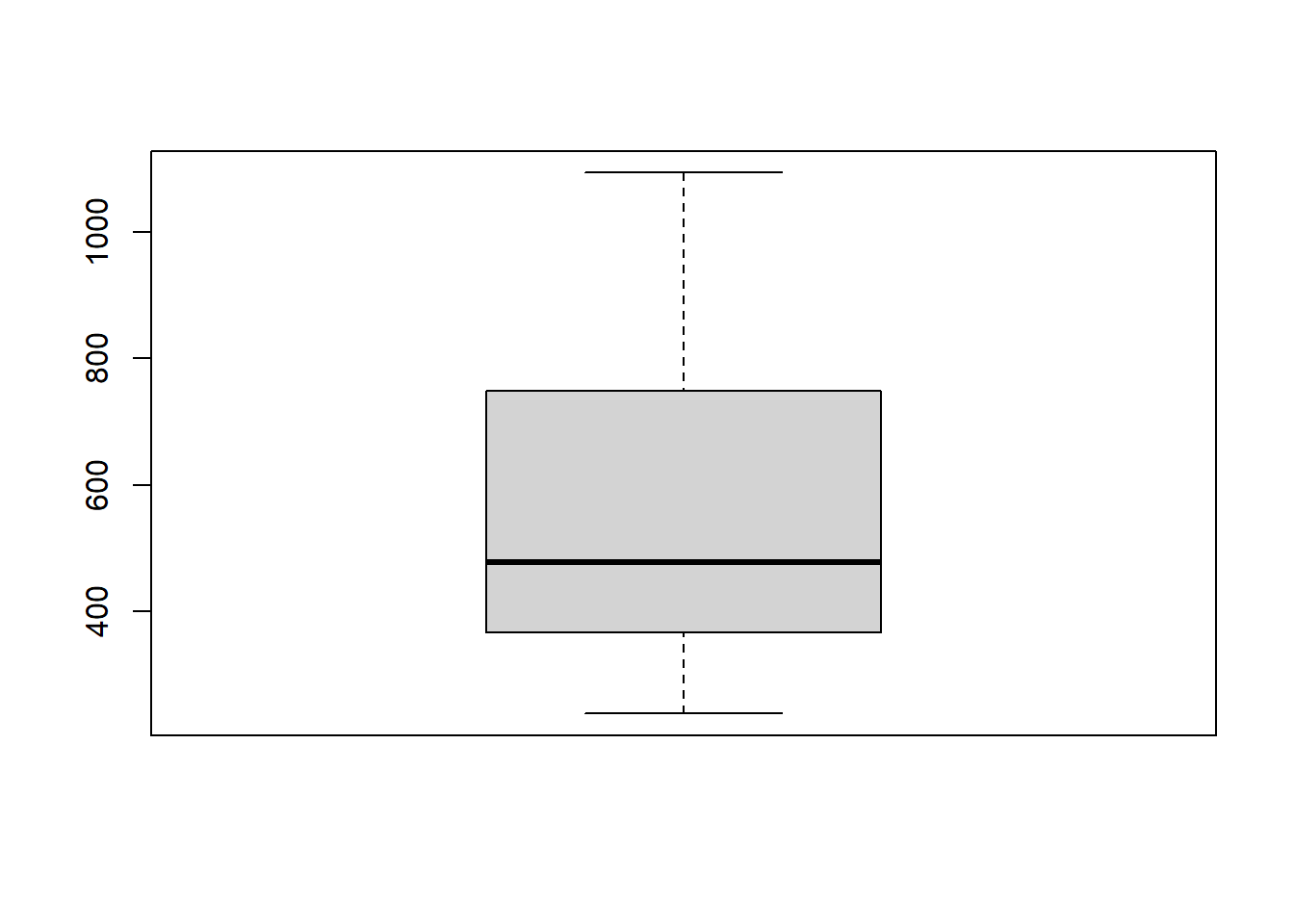
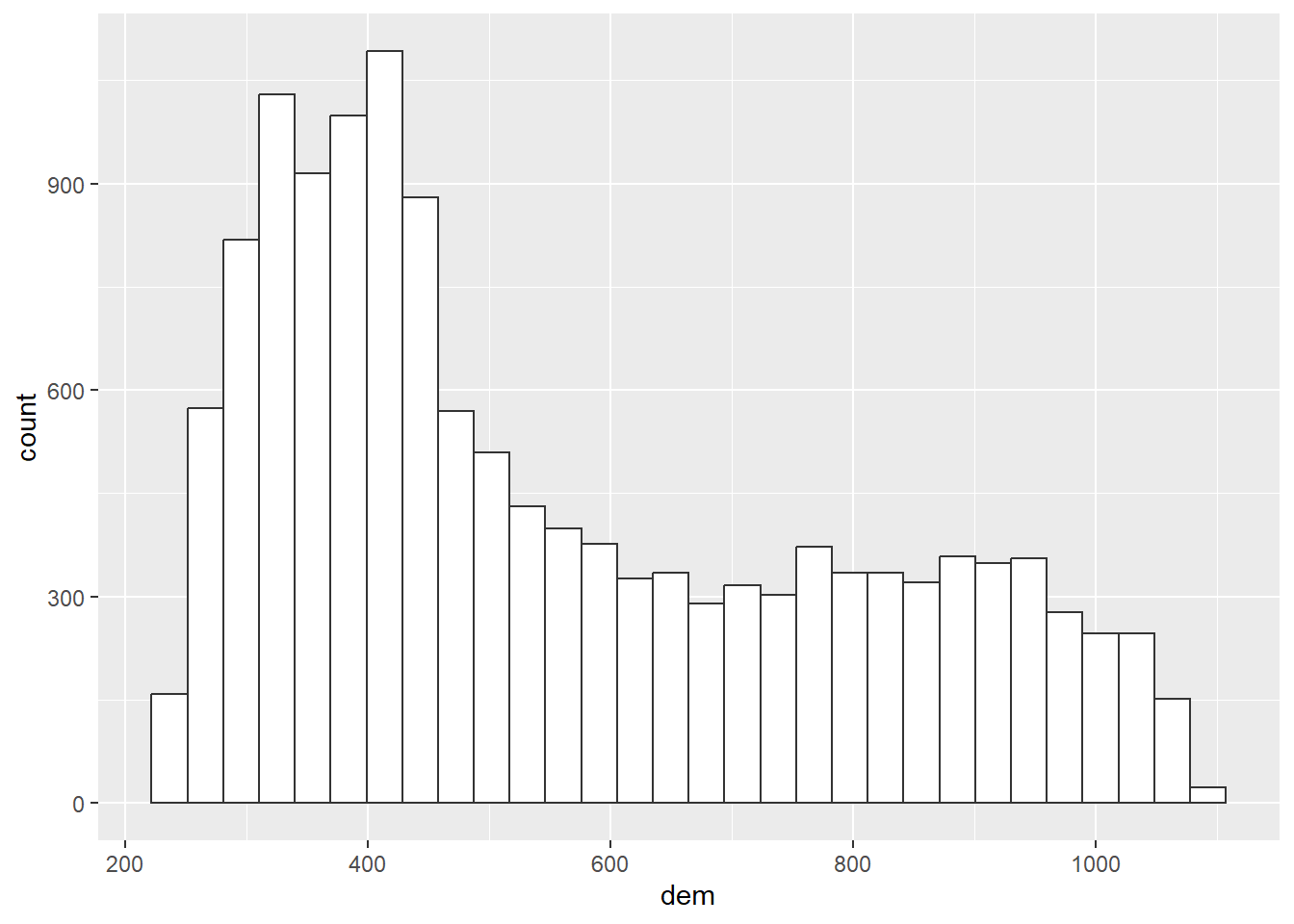
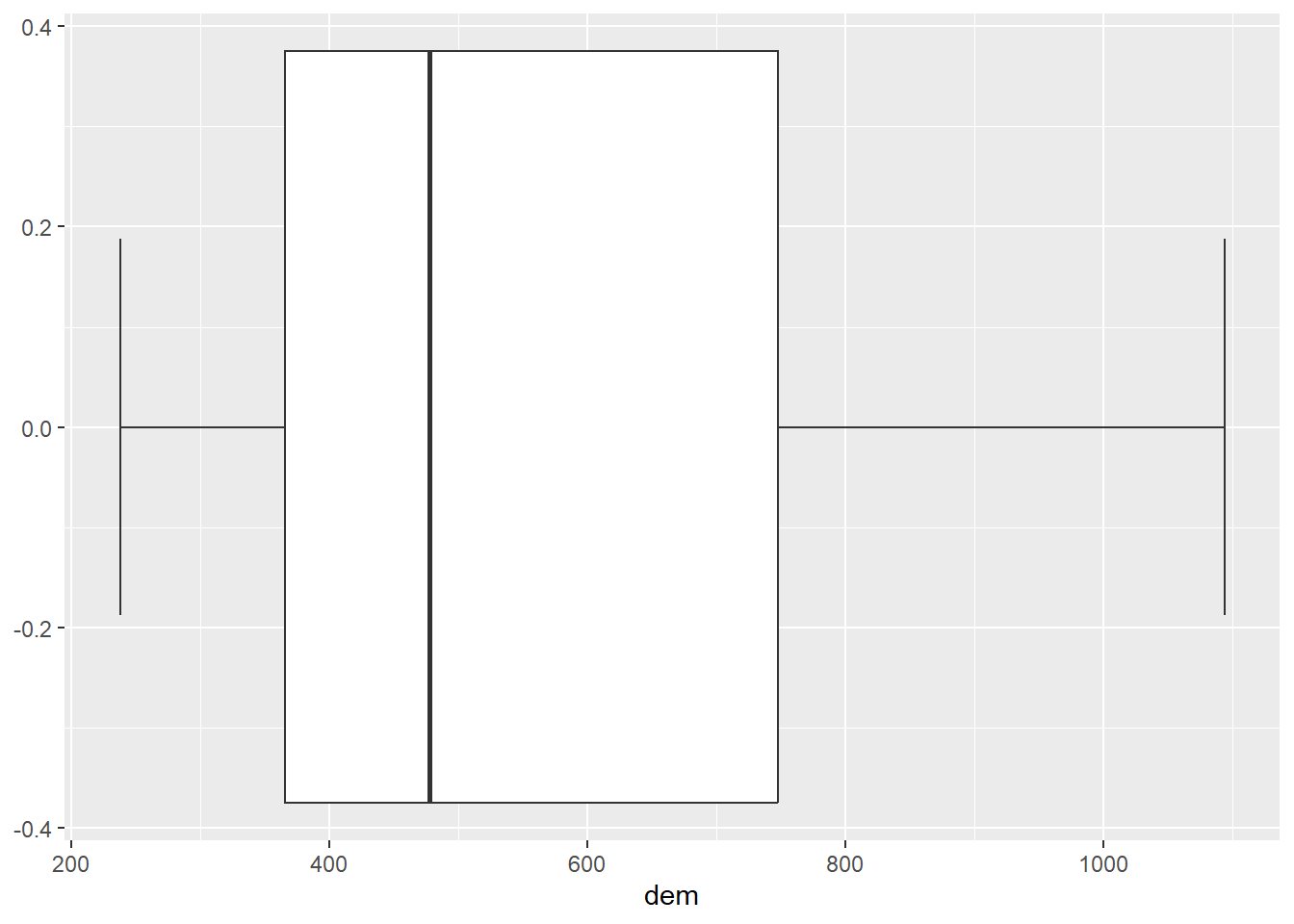
Plot the histogram and the boxplot of the dem.tif file from the spDataLarge package (system.file("raster/dem.tif", package = "spDataLarge")).
The plots are shown in Figure 2
temp_rast <- rast(system.file("raster/dem.tif", package = "spDataLarge"))
hist(temp_rast)
boxplot(temp_rast)
# Using ggplot2 methods
temp_rast |>
values() |>
as_tibble() |>
ggplot(aes(dem)) +
geom_histogram(
fill = "white",
colour = "grey20"
)
temp_rast |>
values() |>
as_tibble() |>
ggplot(aes(dem)) +
geom_boxplot(
fill = "white",
colour = "grey20",
staplewidth = 0.5
)