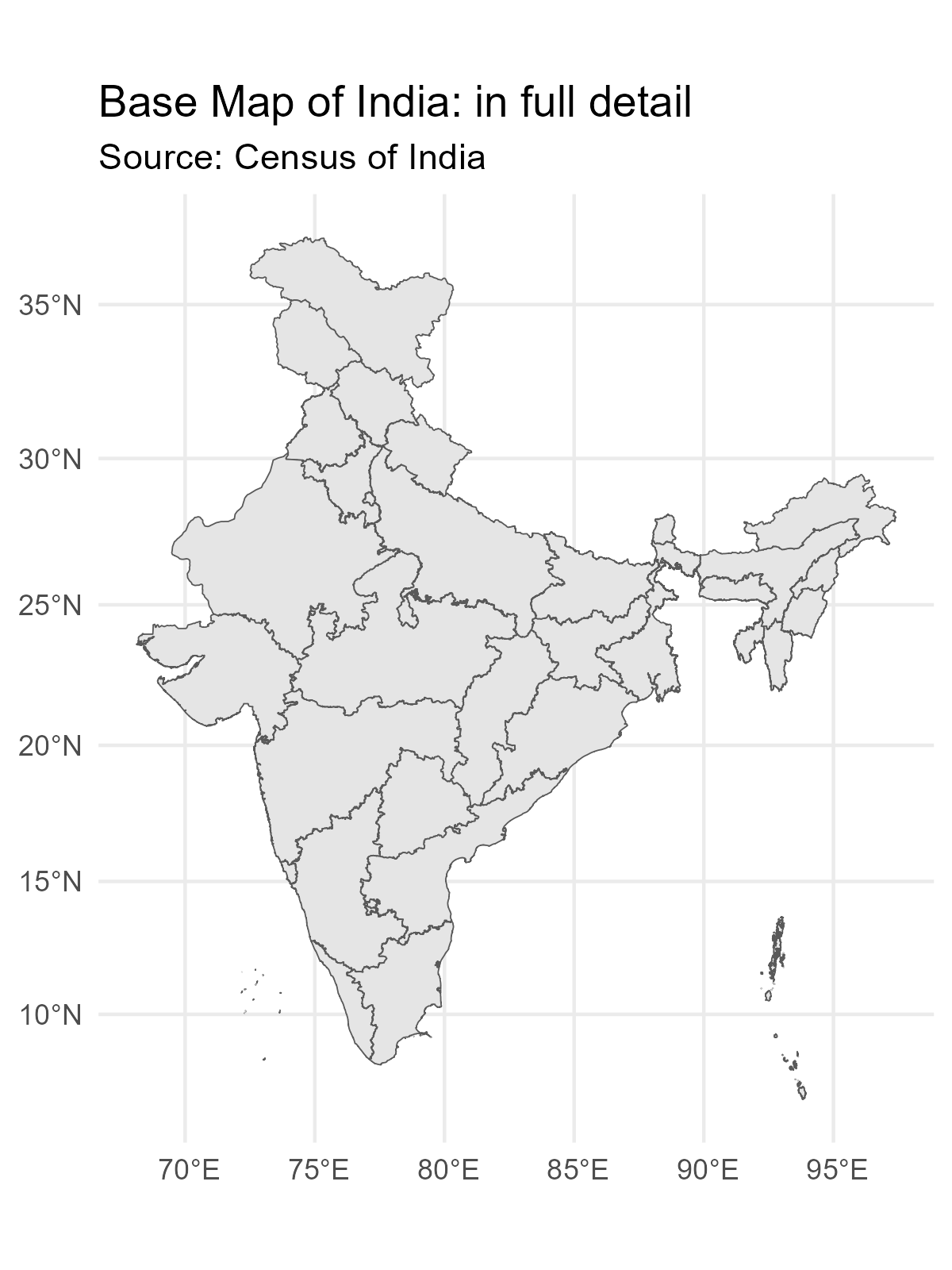
Key Learnings from, and Solutions to the exercises in Chapter 4 of the book Geocomputation with R by Robin Lovelace, Jakub Nowosad and Jannes Muenchow.
Geocomputation with R
Textbook Solutions
Author
Aditya Dahiya
Published
December 16, 2024
Code
library(sf) # Simple Features in Rlibrary(terra) # Handling rasters in Rlibrary(tidyterra) # For plotting rasters in ggplot2library(magrittr) # Using pipes with raster objectslibrary(tidyverse) # All things tidy; Data Wranglinglibrary(spData) # Spatial Datasetslibrary(patchwork) # Composing plots
Unary operations: Simplifications, buffers, centroids, and affine transformations (Sections 5.2.1–5.2.4).
Binary operations: Modifying geometries through clipping and unions (Sections 5.2.5–5.2.7).
Type transformations: Converting geometry types, e.g., polygons to lines (Section 5.2.8).
Section 5.3: Raster transformations:
Alter pixel size, resolution, extent, and origin.
Align raster datasets for map algebra.
5.2 Geometric operations on vector data
Focus: Operations that modify the geometry of vector (sf) objects.
Key distinction: Works directly on geometry-level objects of class sfc, in addition to sf objects.
Examples: Drilling into geometry to transform, simplify, or reshape vector data.
5.2.1 Simplification
Generalizes vector geometries (lines/polygons) for smaller scale maps, reducing memory, disk space, and bandwidth usage. Useful for publishing interactive maps by simplifying complex geometries.
Retains topology by default (keep_shapes = TRUE) and allows fine control over the vertex retention (keep: the % of vertices that are to be retained, given as a proportion).
Note: This converts the CRS of the new sfc object to NA and thus needs st_set_crs() to return it back to the original CRS.
Scaling: Enlarges or shrinks geometries.
Global Scaling:
Multiplies all coordinates relative to the origin, preserving topological relations.
Local Scaling:
Scales geometries around specific points (e.g., centroids).
Steps:
Shift geometries so the centroid becomes (0,0).
Scale by a factor.
Shift back to original centroid coordinates.
Rotation: Rotates coordinates using a rotation matrix.
Rotation matrix: Define a function to create the rotation matrix and apply it to the geometry. R=[cosθ/sinθ − sinθ/cosθ]
Replacing Old Geometry: Once the affine transformation has been completed, use st_set_geometry() from the sf package to finally Replace original geometry with scaled versions (shifted, rotated or scaled)
Applications:
Shifting: For label placement.
Scaling: In non-contiguous cartograms.
Rotation: Correcting distorted geometries during re-projection.
Code
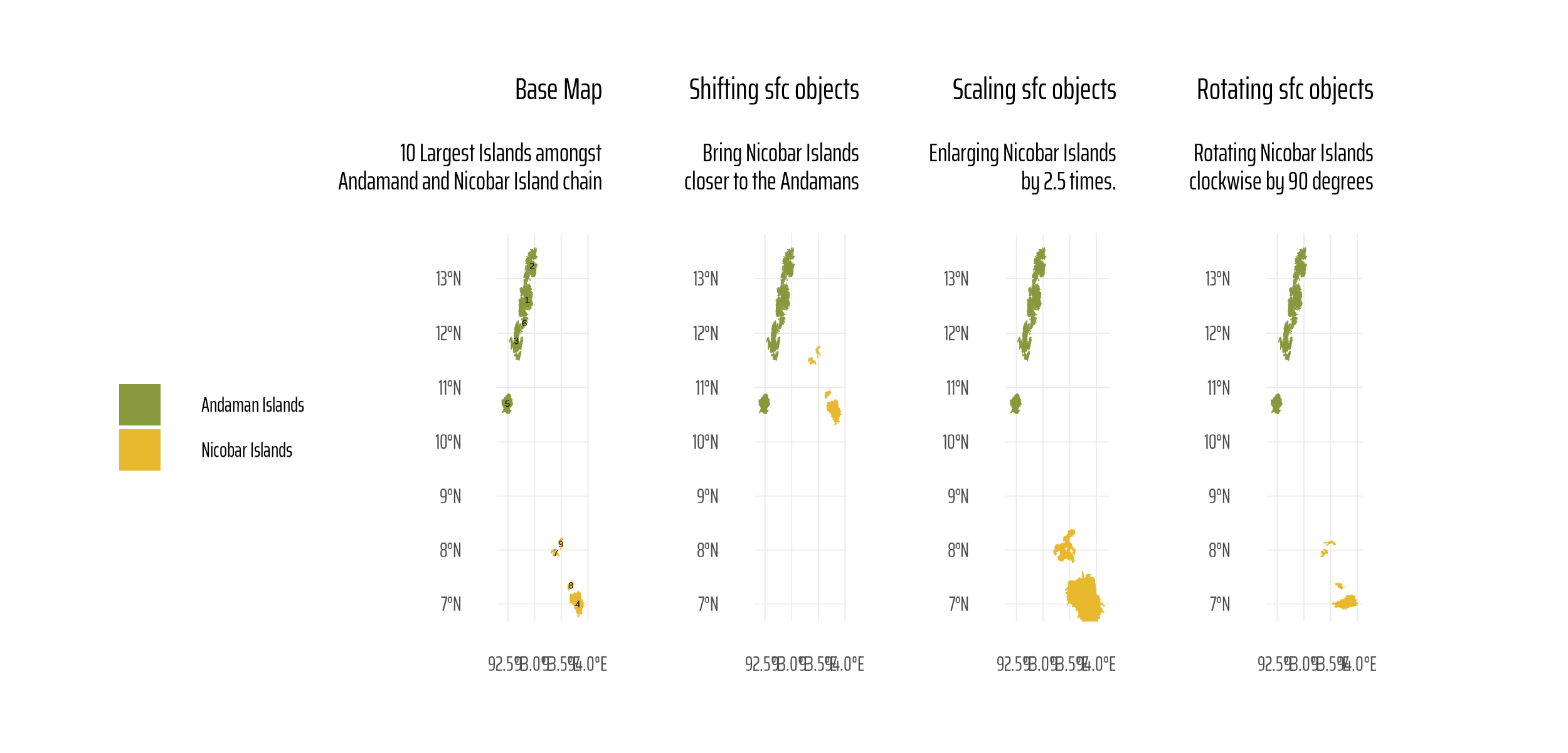
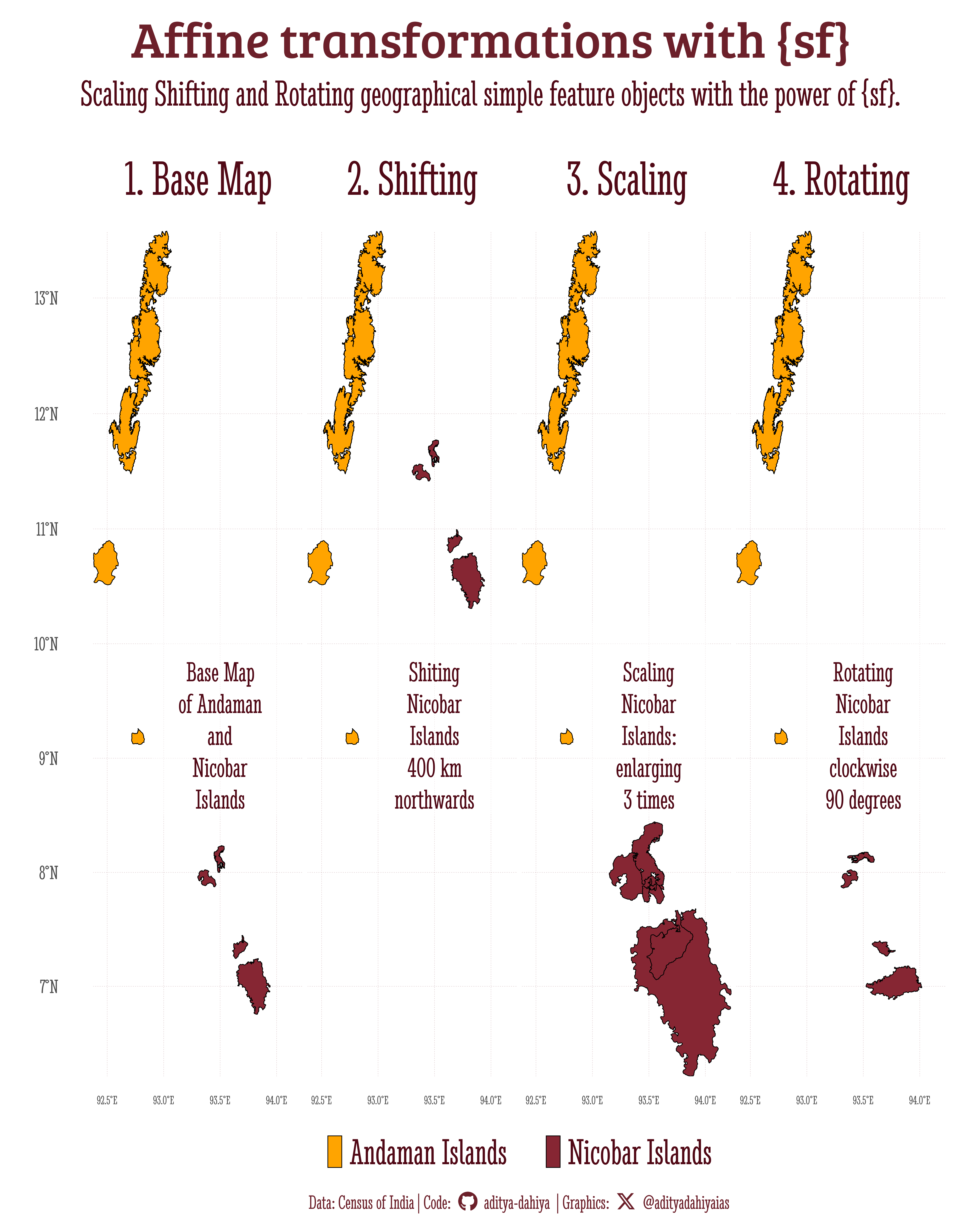
sysfonts::font_add_google("Saira Extra Condensed", "caption_font")showtext::showtext_auto()ggplot2::theme_set(theme_minimal(base_size =30,base_family ="caption_font" ) +theme(text =element_text(lineheight =0.3,hjust =0.5 ),plot.title.position ="plot",plot.title =element_text(hjust =1),plot.subtitle =element_text(hjust =1),panel.grid =element_line(linewidth =0.2 ) ))df1 <- andaman |>st_cast("POLYGON") |>mutate(id =row_number()) |>filter(id <10) |>mutate(name =case_when( id %in%c(4,8, 9, 7) ~"Nicobar Islands",.default ="Andaman Islands" ) )# Pull out only sfc class (i.e. geometry for Andaman Islands)a1 <- df1 |>filter(name =="Andaman Islands") |>st_geometry()# Pull out only sfc class (i.e. geometry for Nicobar Islands)n1 <- df1 |>filter(name =="Nicobar Islands") |>st_geometry()g1 <- df1 |>ggplot(aes(fill = name)) +geom_sf(colour ="transparent") +geom_sf_text(aes(label = id)) +coord_sf(ylim =c(7, 13.5),default_crs =4326 ) +labs(title ="Base Map",subtitle ="10 Largest Islands amongst\nAndamand and Nicobar Island chain",fill =NULL, x =NULL, y =NULL ) +scale_fill_manual(values =c("#89973DFF", "#E8B92FFF")) +theme(legend.position ="left" )g2 <-ggplot() +geom_sf(data = a1, fill ="#89973DFF", colour ="transparent") +geom_sf(data = n1, fill ="#E8B92FFF", colour ="transparent") +coord_sf(ylim =c(7, 13.5),default_crs =4326 ) +labs(title ="Plotting as separate\nsfc objects",subtitle ="10 Largest Islands" )#################### Shifting #########################n_shift <- n1 |>add(c(0, 400000)) |>st_set_crs(st_crs(n1))g3 <-ggplot() +geom_sf(data = a1, fill ="#89973DFF", colour ="transparent") +geom_sf(data = n_shift, fill ="#E8B92FFF", colour ="transparent" ) +coord_sf(ylim =c(7, 13.5),default_crs =4326 ) +labs(title ="Shifting sfc objects",subtitle ="Bring Nicobar Islands\ncloser to the Andamans" )#################### Scaling ##########################n1_centroid <-st_centroid(n1)n1_scale <- (n1 - n1_centroid) |>multiply_by(2.5) |>add(n1_centroid) |>st_set_crs(st_crs(n1))g4 <-ggplot() +geom_sf(data = a1, fill ="#89973DFF", colour ="transparent") +geom_sf(data = n1_scale, fill ="#E8B92FFF", colour ="transparent" ) +coord_sf(ylim =c(7, 13.5),default_crs =4326 ) +labs(title ="Scaling sfc objects",subtitle ="Enlarging Nicobar Islands\nby 2.5 times." )##################### Rotation ########################rotation =function(a){ r = a * pi /180#degrees to radiansmatrix(c(cos(r), sin(r), -sin(r), cos(r)), nrow =2, ncol =2)} n1_rotate <- (n1 - n1_centroid) |>multiply_by(rotation(90)) |>add(n1_centroid) |>st_set_crs(st_crs(n1))g5 <-ggplot() +geom_sf(data = a1, fill ="#89973DFF", colour ="transparent") +geom_sf(data = n1_rotate, fill ="#E8B92FFF", colour ="transparent" ) +coord_sf(ylim =c(7, 13.5),default_crs =4326 ) +labs(title ="Rotating sfc objects",subtitle ="Rotating Nicobar Islands\nclockwise by 90 degrees" )g <- patchwork::wrap_plots(g1, g3, g4, g5) + patchwork::plot_layout(widths =c(1,1,1,1,1), nrow =1)ggsave(filename = here::here("book_solutions", "images", "chapter5-2-4_1.png"),plot = g,height =1200,width =2500,units ="px")
Data Viz demonstration
Here’s a more visually appealing version of the same graphic, produced using complete code given on this page.
This plot demonstrates the application of spatial transformations on the Andaman and Nicobar Islands using the `sf` package in R. It showcases four techniques: base mapping, northward shifting, scaling (enlargement), and rotation (90° clockwise), highlighting their effects on spatial geometries. The `facet_wrap` function neatly organizes the transformations for comparison, while `geom_sf` and custom labels enhance the visualization.
5.2.5 Clipping
Definition: A form of spatial subsetting that modifies the geometry column of affected features. Applies to lines, polygons, and their multi equivalents (not points).
Purpose: Identifies or extracts areas of overlap or subsets of spatial features. Commonly used in geographic data analysis to focus on regions of interest.
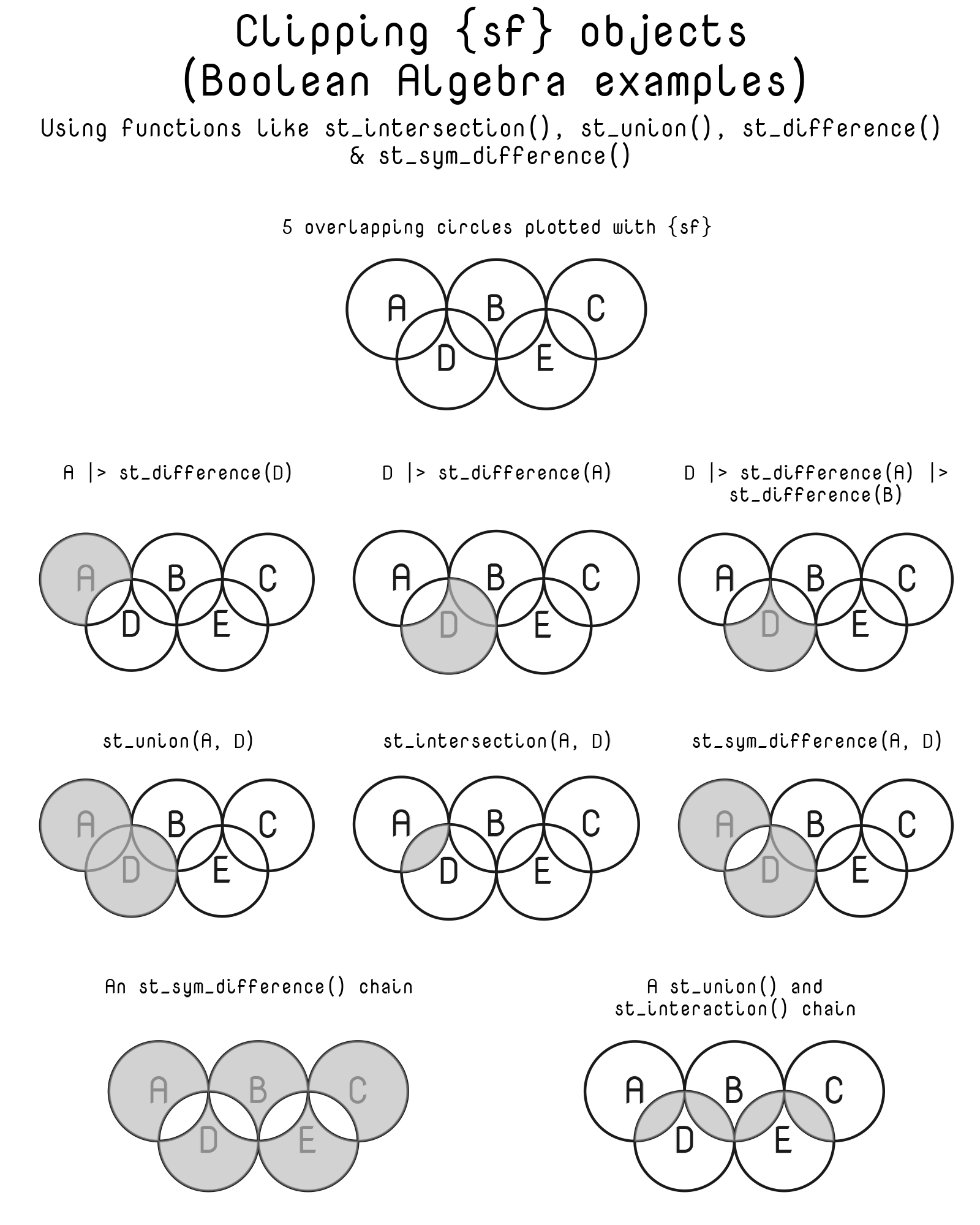
Logical Operations and Spatial Equivalents. Inspired by Figure 12.1 of R for Data Science (2e). Spatial equivalents to logical operators (e.g., AND, OR, NOT) allow flexible geometry subsetting (as shown in Figure 4)
Intersection (AND): st_intersection()
Union (OR): st_union()
Difference (NOT): st_difference()
Exclusive OR (XOR):st_sym_difference()
Applications:
Identifying overlapping regions.
Creating subsets of spatial data for specific analysis or visualization.
Figure 4: Various methods and examples (inspired by Boolean Algebra) for clipping {sf} objects in R
5.2.6 Sub-setting and Clipping
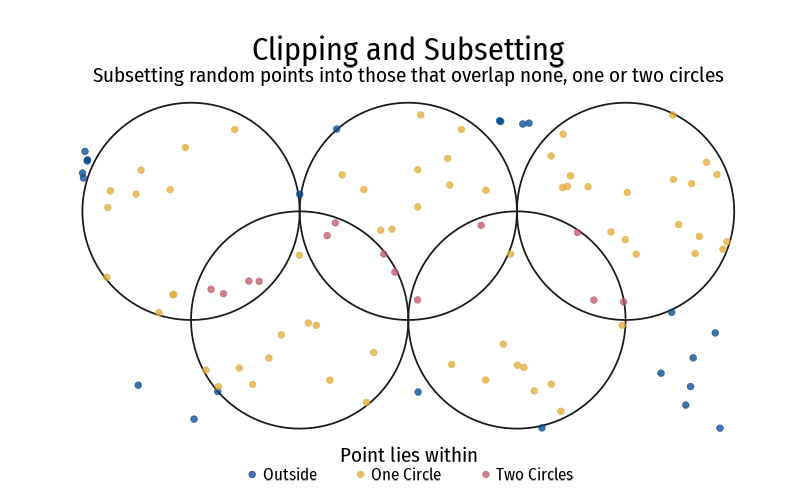
Clipping: Modifies geometry to match a subsetting object. Subsetting: Selects features that intersect or partly intersect with a clipping object. An example: Points randomly distributed within the bounding box of the five concentric circles. Some points are inside one circle, some inside two circles, or neither. Then, we subset points intersecting with one, two or no circles.
Key Functions:
st_sample(): Generates random points within a geometry.
Clipping and Subsetting Approaches:
Way #1: Use the intersection of x and y (x_and_y) as a direct subsetting object: p[x_and_y]
Way #2: Find the intersection between points (p) and x_and_y, modifying overlapping geometries: st_intersection(p, x_and_y) , or, using st_interesects() when working in a pipe (|>) chain.
Way #3: Use st_intersects() to determine logical overlap between p and the subsetting objects: sel_p_xy = st_intersects(p, x, sparse = FALSE)[, 1] & st_intersects(p, y, sparse = FALSE)[, 1] and then subset, using p_xy3 = p[sel_p_xy]
Preferred Implementation:
Way #2 (concise and efficient) and it is the tidyverse approach with |> compatibility. Example shown in Figure 5
Code
sysfonts::font_add_google("Fira Sans Condensed", "body_font")showtext::showtext_auto()theme_custom <-function(...) { ggthemes::theme_map(base_size =20,base_family ="body_font" ) +labs(x =NULL, y =NULL ) +theme(plot.title =element_text(hjust =0.5,lineheight =0.3,margin =margin(5,0,2,0, "mm") ),plot.margin =margin(0,0,0,0, "mm"), ... )}# Define the center points of the circlessf_circles <-tibble(x =c(0, 2, 4, 1, 3),y =c(0, 0, 0, -1, -1),colour_var =c("blue", "black", "red", "yellow", "green"),label_var = LETTERS[1:5] ) |># Convert the points to an sf objectst_as_sf(coords =c("x", "y"), crs =NA ) |># Create circular geometries using st_buffermutate(geometry =st_buffer(geometry, dist =1))# Naming the individual circlespull_a_circle <-function(ch_pick){ sf_circles |>filter(label_var == ch_pick)}a1 <-pull_a_circle("A") b1 <-pull_a_circle("B") c1 <-pull_a_circle("C") d1 <-pull_a_circle("D") e1 <-pull_a_circle("E") one_circle <- a1 |>st_sym_difference(d1) |>st_sym_difference(b1) |>st_sym_difference(c1) |>st_sym_difference(e1)overlap <- a1 |>st_intersection(d1) |>st_union(st_intersection(d1, b1)) |>st_union(st_intersection(b1, e1)) |>st_union(st_intersection(e1, c1))rm(a1, b1, c1, d1, e1)set.seed(42)random_points <- sf_circles |># Get a bounding boxst_bbox() |># Covert it into a polygonst_as_sfc() |># Get a sample of points within this polygonst_sample(size =100) |># Convert into a sf objectst_as_sf() |># Add identifiers for where the points fallmutate(colour_var =case_when(st_intersects(x, overlap, sparse = F) ~"Two Circles",st_intersects(x, one_circle, sparse = F) ~"One Circle",.default ="Outside" ),colour_var =fct( colour_var,levels =c("Outside","One Circle","Two Circles" ) ) )g <-ggplot() +geom_sf(data = sf_circles, fill ="transparent",linewidth =0.2,colour ="grey10" ) +geom_sf(data = random_points,mapping =aes(geometry = x,colour = colour_var ),alpha =0.75,size =0.7,stroke =0.1 ) +labs(title ="Clipping and Subsetting",subtitle ="Subsetting random points into those that overlap none, one or two circles",colour ="Point lies within" ) + paletteer::scale_colour_paletteer_d("khroma::highcontrast") + ggthemes::theme_map(base_family ="body_font",base_size =16 ) +theme(plot.title =element_text(size =24,hjust =0.5,margin =margin(0,0,0,0, "mm") ),plot.subtitle =element_text(hjust =0.5,lineheight =0.3,margin =margin(0,0,0,0, "mm") ),legend.position ="inside",legend.position.inside =c(0.5, 0),legend.justification =c(0.5, 1),legend.direction ="horizontal",legend.text =element_text(margin =margin(0,0,0,0, "mm") ),legend.title =element_text(margin =margin(0,0,0,0, "mm"),hjust =0.5 ),legend.margin =margin(0,0,0,0, "mm"),legend.key.size =unit(5, "pt"),legend.title.position ="top" )ggsave(filename = here::here("book_solutions", "images", "chapter5-2-6_1.png"),plot = g,height =500,width =800,units ="px",bg ="white")
Figure 5: Sub-setting points with clipped {sf} objects - an example
5.2.7 Geometry Unions
Spatial Aggregation and Geometry Dissolution:
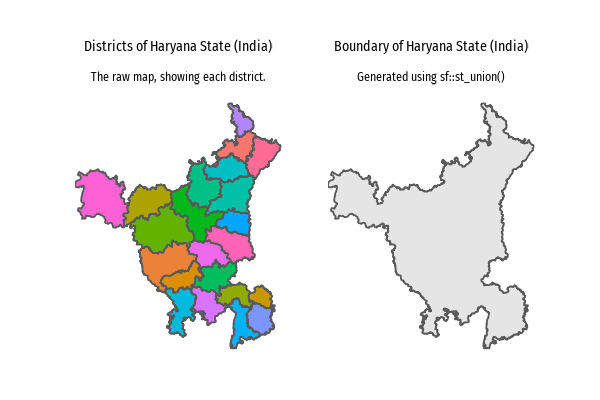
Spatial aggregation dissolves boundaries of touching polygons within the same group automatically. Example: Aggregating 22 districts of the State of Haryana into an overall boundary map with aggregate() (base R approach) or summarize() (tidyverse approach), for example in Figure 6
Geometric Operation Behind the Scenes: Functions aggregate() and summarize() internally call st_union() from the sf package to dissolve boundaries and merge geometries.
Union of Geometries: Visualization Insight example is shown below.
Figure 6: A district map of Haryana, converted into an outer boundary map using st_union()
Code
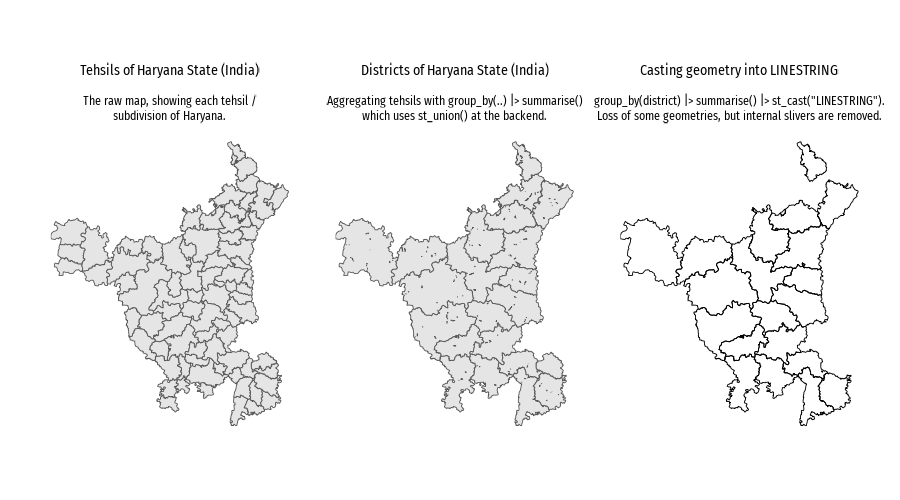
sysfonts::font_add_google("Fira Sans Condensed", "body_font")showtext::showtext_auto()haryana <-read_sf( here::here("data", "haryana_map","HARYANA_SUBDISTRICT_BDY.shp" )) |> janitor::clean_names() |>st_simplify(dTolerance =100) |>mutate(district =str_replace_all(district, ">", "A"),district =str_replace_all(district, "\\|", "I"),district =str_to_title(district),tehsil =str_to_title(str_replace_all(tehsil, ">", "A")) )g1 <-ggplot() +geom_sf(data = haryana, linewidth =0.1) + ggthemes::theme_map(base_family ="body_font" ) +coord_sf(expand =FALSE) +labs(title ="Tehsils of Haryana State (India)",subtitle ="The raw map, showing each tehsil /\nsubdivision of Haryana." ) +theme(plot.title =element_text(hjust =0.5 ),plot.subtitle =element_text(hjust =0.5,lineheight =0.35 ) )g2 <- haryana |>group_by(district) |>summarise() |>ggplot() +geom_sf(linewidth =0.1 ) + ggthemes::theme_map(base_family ="body_font" ) +coord_sf(expand =FALSE) +labs(title ="Districts of Haryana State (India)",subtitle ="Aggregating tehsils with group_by(..) |> summarise()\nwhich uses st_union() at the backend." ) +theme(plot.title =element_text(hjust =0.5 ),plot.subtitle =element_text(hjust =0.5,lineheight =0.35 ) )g3 <- haryana |>group_by(district) |>summarise() |>st_cast("LINESTRING") |>ggplot() +geom_sf(linewidth =0.1 ) + ggthemes::theme_map(base_family ="body_font" ) +coord_sf(expand =FALSE) +labs(title ="Casting geometry into LINESTRING",subtitle ="group_by(district) |> summarise() |> st_cast(\"LINESTRING\").\nLoss of some geometries, but internal slivers are removed." ) +theme(plot.title =element_text(hjust =0.5 ),plot.subtitle =element_text(hjust =0.5,lineheight =0.35 ) )ggsave(filename = here::here("book_solutions", "images", "chapter5-2-7_1.png"),plot = (g1 + g2 + g3),height =500,width =900,units ="px",bg ="white")
Note
When using the st_union() function in spatial analysis, “inside small lines” or “slivers” appearing in the resulting combined geometry often indicates slight discrepancies in the input geometries, particularly at boundary points, causing the union operation to create small, extra line segments where the geometries nearly overlap but don’t perfectly align, as shown in Figure 7
Figure 7: A sub-district / Tehsil map of Haryana, when converted into a district map with summarise() [which basically uses st_union() only] produces an imperfect result with internal slivers, as the boundary nodes are not overlapping amongst the sub-districts / tehsils. This depicts an inherent (limitation? / caution?) of sf::st_union().
5.2.8 Type Transformations
Geometry Casting: Transform geometry types using st_cast() from the sf package.
Works on simple feature geometry (sfg), simple feature column (sfc), and simple feature objects (sf).
Reversible Casting:
Example: st_cast(linestring, "MULTIPOINT") reverts to multipoint geometry.
Retains original geometry for compatible transformations.
Feature Splitting:
Converts multi-objects to non-multi-objects by splitting (e.g., MULTIPOINT to multiple POINTs).
Expands rows with duplicate attribute values during splitting.
Use cases:
Multipoint to Linestring: For path length calculations from ordered points.
Linestring to Polygon: To compute area, e.g., lake boundary.
Added attributes (e.g., road names, lengths) in case of feature splitting.
Measurements like st_length() for each LINESTRING.
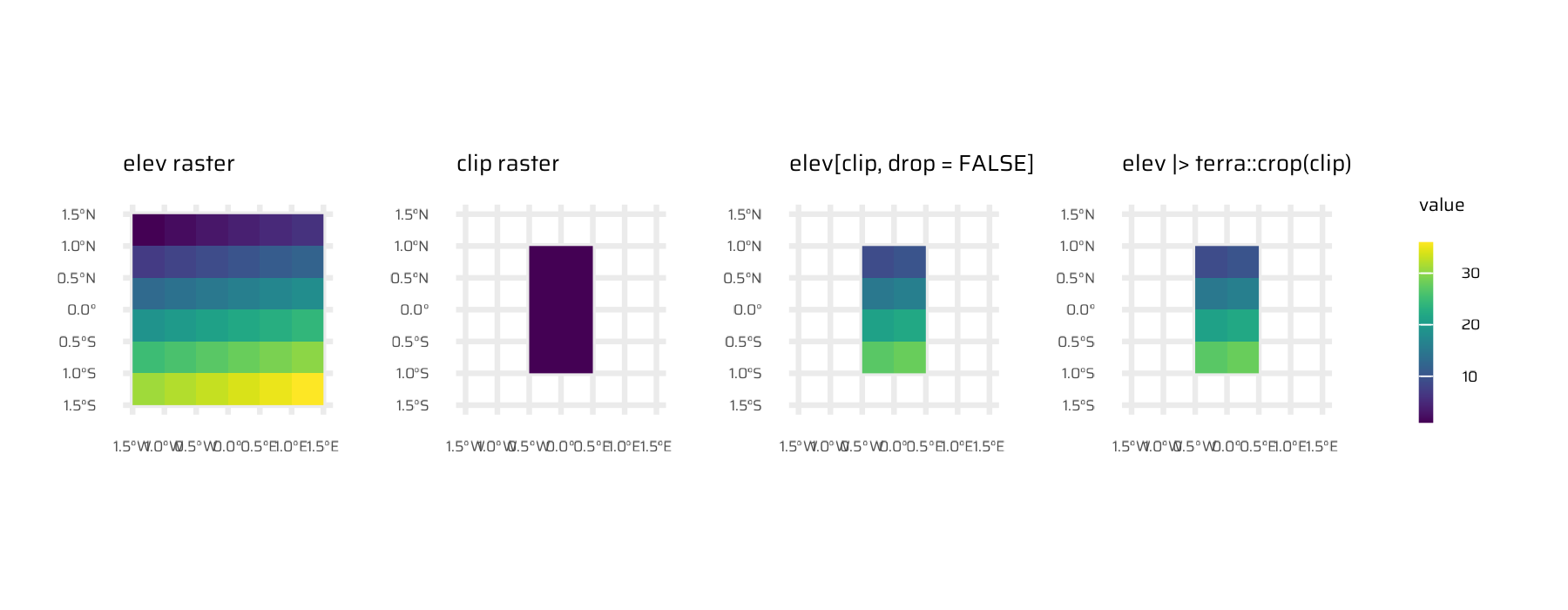
Figure 8: Comparing base R [] and terra::crop() for subsetting rasters
5.3.2 Extent and Origin
Raster alignment necessity: Mismatches in resolution, projection, origin, or extent must be addressed for map algebra or merging. For example, Adding a raster with a 0.2-degree resolution to one with a 1-degree resolution is impossible without alignment.
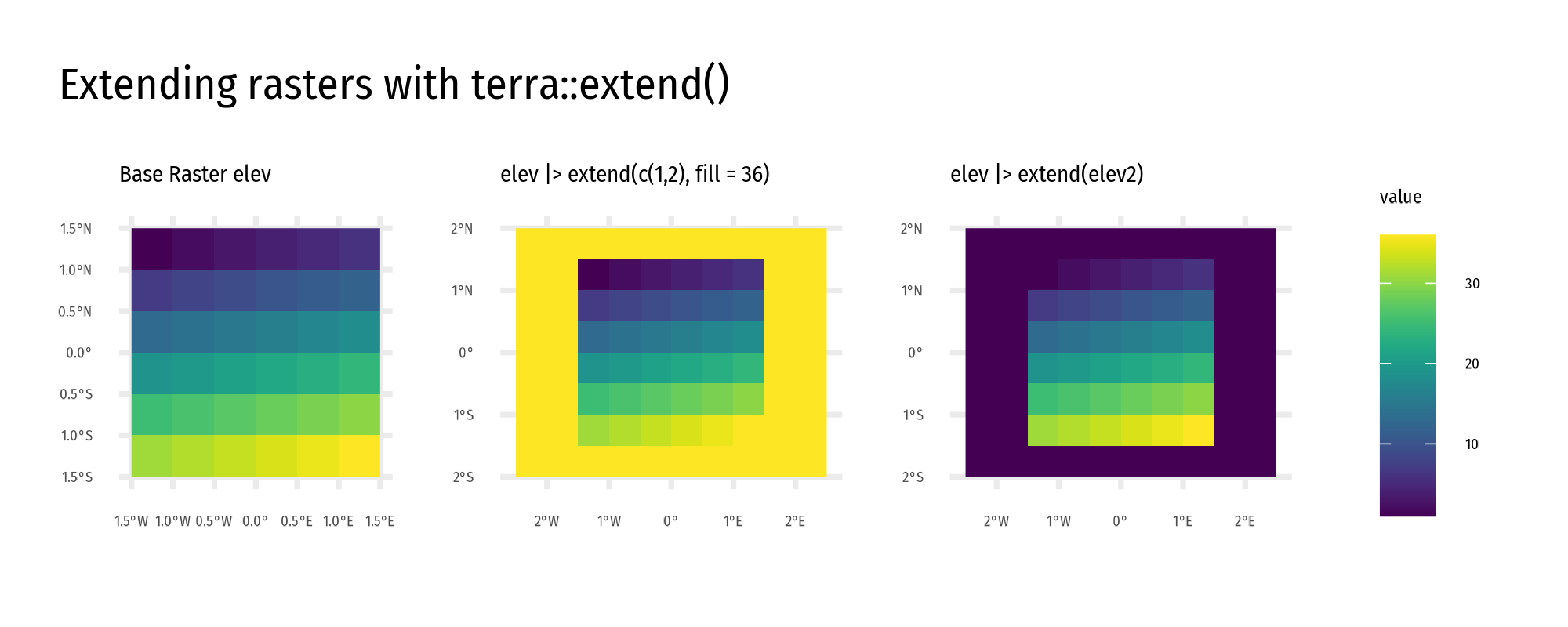
Extent mismatch: Extending a raster adds rows/columns filled with NA values. Use extend() from the terra package for this.
Extent alignment: Performing operations on rasters with differing extents throws an error. Solution: Use another raster as a reference to align extents via terra::extend().
The terra::extend() function in R enlarges the spatial extent of a SpatRaster or SpatExtent. It can add rows and columns, with values filled using the fill argument (default NA). The y argument specifies how much to extend, either as an extent object or numeric values indicating rows/columns to add. The snap argument controls alignment (“near”, “in”, “out”). Outputs can be saved using filename and overwrite.
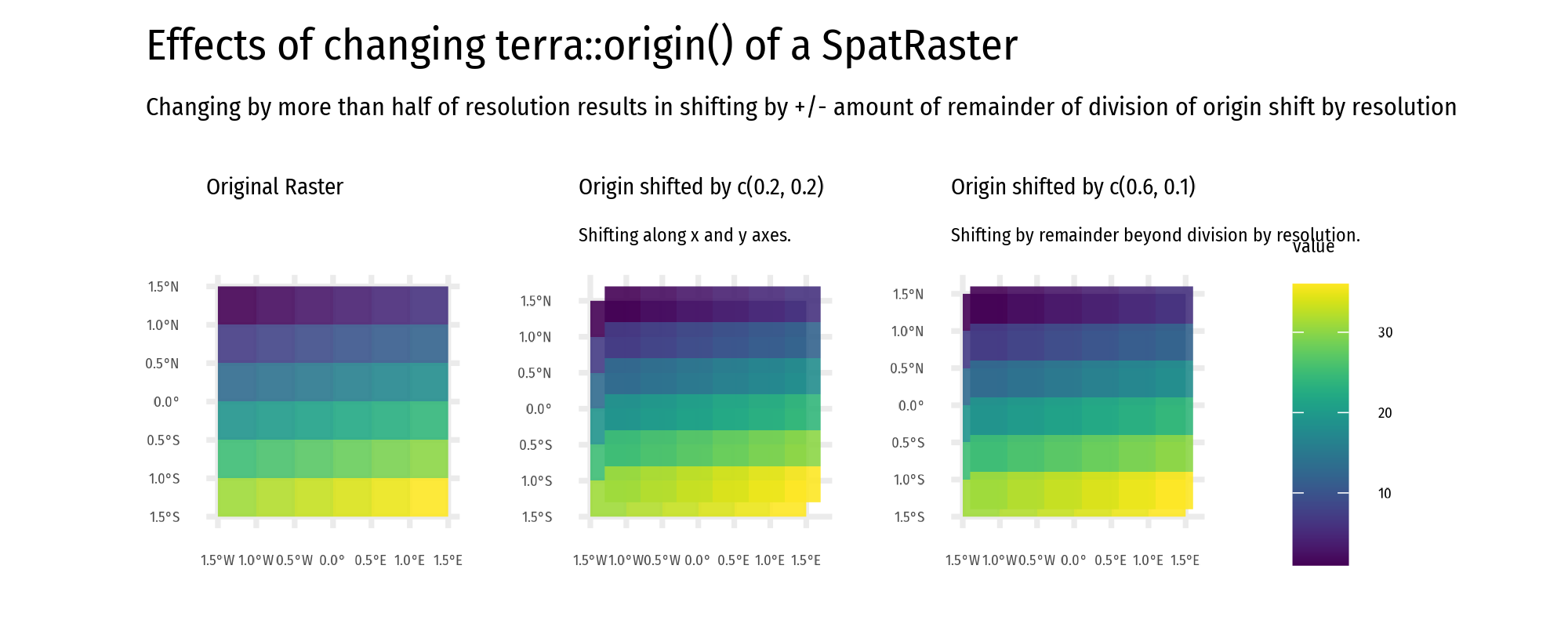
Origin:
The origin is the raster cell corner closest to coordinates (0, 0). Use terra::origin() to retrieve or modify the raster origin.
Misaligned origins cause raster cells not to overlap, making map algebra impossible. Adjust the origin with origin() to ensure proper alignment.
If two rasters are marginally apart, change tolerance argument for terra::terraOptions().
Visualization: Figure 9 illustrates raster extension and Figure 10 shows the effect of origin changes.
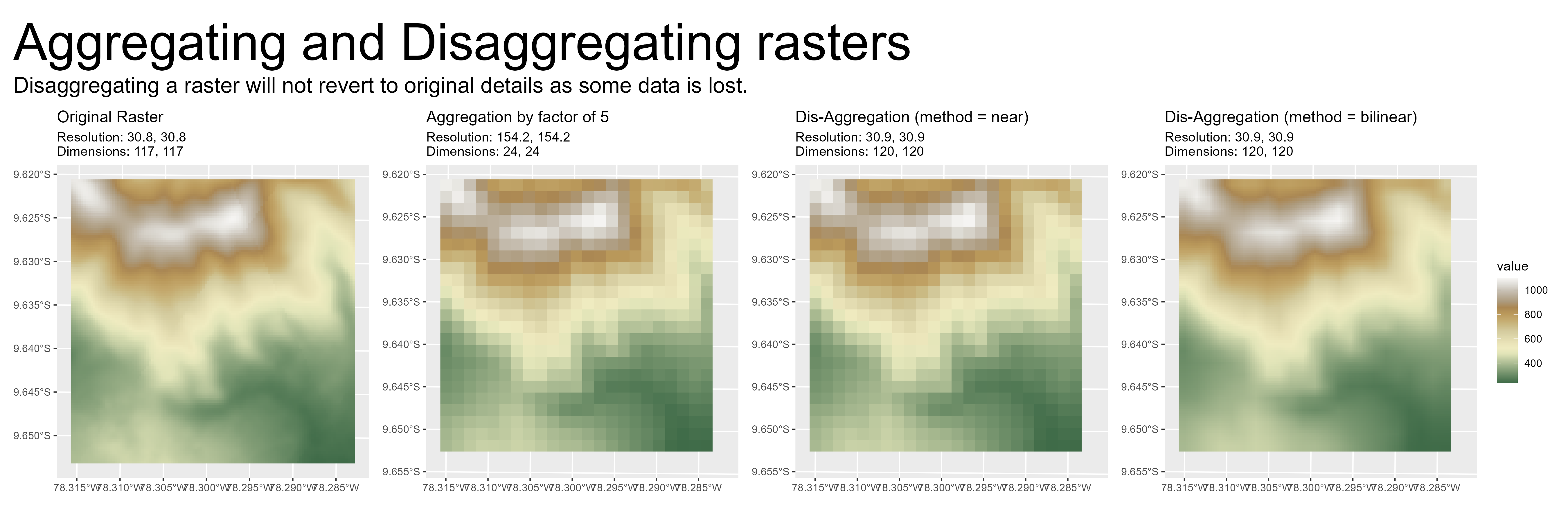
Figure 11: Aggregating and Disaggregating a raster by a factor of 5. Note the superiority of blinear method of disaggregatiion.
5.3.4 Resampling
Purpose: Adjusts pixel values for a target raster with different resolution and origin than the original raster (terra). Useful for combining rasters with varying resolutions/origins.
Methods: A comparison table on resampling methods available in the {terra} package’s resample() function with examples in Figure 12
No.
Method
Description
Suitable For
Complexity
Use Case
1
Nearest Neighbor
Assigns the value of the nearest cell of the original raster to the target cell.
Categorical rasters
Simple
Discrete data like land-use classifications
2
Bilinear Interpolation
Computes a weighted average of the four nearest cells from the original raster for the target cell.
Continuous rasters
Moderate
Continuous data; smoother transitions, elevation models or temperature data.
3
Cubic Interpolation
Uses the values of the 16 nearest cells, applying third-order polynomial functions for smooth output.
Continuous rasters
Higher
Continuous data requiring smoother surfaces; resampling satellite imagery.
Continuous data where smoothness is crucial; terrain modeling.
5
Lanczos Resampling
Uses the 36 nearest cells with a Lanczos windowed sinc function for smoother outputs.
Continuous rasters
High
Best for high-quality image scaling; maintains sharpness and reduces aliasing in photographic images.
6
Sum
Calculates the weighted sum of all non-NA contributing grid cells.
Spatially extensive variables
Variable
Aggregating data like population counts; ensures the total sum remains consistent.
7
Min
Finds the minimum value among all non-NA contributing grid cells.
Continuous rasters
Variable
Where the minimum value is of interest, such as finding the lowest temperature in a region.
8
Q1 (First Quartile)
Computes the first quartile value of all non-NA contributing grid cells.
Continuous rasters
Variable
To understand the lower distribution of data values.
9
Median (Med)
Computes the median value of all non-NA contributing grid cells.
Continuous rasters
Variable
Reducing the impact of outliers; in skewed data distributions.
10
Q3 (Third Quartile)
Computes the third quartile value of all non-NA contributing grid cells.
Continuous rasters
Variable
Focussing on the upper distribution of data values.
11
Max
Finds the maximum value among all non-NA contributing grid cells.
Continuous rasters
Variable
Identifying peak values, such as maximum elevation or highest temperature.
12
Average
Calculates the mean value of all non-NA contributing grid cells.
Continuous rasters
Variable
For smoothing data; provides an overall average.
13
Mode
Identifies the most frequent value among all non-NA contributing grid cells.
Continuous rasters
Variable
For categorical data; to determine the most common land cover type.
14
RMS (Root Mean Square)
Computes the root mean square of all non-NA contributing grid cells.
Continuous rasters
Variable
In error analysis; For assessing the variability in data values.
Notes:
Nearest Neighbor is the preferred method for categorical data to prevent the creation of non-existent categories.
Bilinear, Cubic, Cubic Spline, and Lanczos methods are more appropriate for continuous data, offering varying degrees of smoothness and detail preservation.
Categorical vs. Continuous:
Only nearest neighbor is suitable for categorical rasters.
Other methods can be used for continuous rasters but vary in outcomes, complexity, and processing time.
Additional Options:
Statistical Resampling:
Methods like sum, min, med, mode, and rms compute statistics over contributing cells.
Example: sum ensures the total remains unchanged for spatially extensive variables (e.g., population).
Target Raster (y): Raster with desired resolution/origin.
Method: Resampling method (e.g., “bilinear”).
Note: Raster Re-projection is a special case of raster re-sampling. A specific type of re-sampling used for target rasters with different Coordinate Reference Systems (CRS).
Figure 12: Various methods for re-sampling a raster with terra::resample()
Code
# Load required librarieslibrary(tibble)library(gt)# Create the resampling methods table as a tibbleresampling_methods <- tibble::tibble(`Resampling Method`=c("Nearest Neighbor", "Bilinear Interpolation", "Cubic Interpolation", "Cubic Spline Interpolation", "Lanczos Resampling", "Sum", "Min", "Q1 (First Quartile)", "Median (Med)", "Q3 (Third Quartile)", "Max", "Average", "Mode", "RMS (Root Mean Square)" ),Description =c("Assigns the value of the nearest cell of the original raster to the target cell.","Computes a weighted average of the four nearest cells from the original raster for the target cell.","Uses the values of the 16 nearest cells, applying third-order polynomial functions for smooth output.","Uses the 16 nearest cells, applying cubic splines (piece-wise third-order polynomial functions).","Uses the 36 nearest cells with a Lanczos windowed sinc function for smoother outputs.","Calculates the weighted sum of all non-NA contributing grid cells.","Finds the minimum value among all non-NA contributing grid cells.","Computes the first quartile value of all non-NA contributing grid cells.","Computes the median value of all non-NA contributing grid cells.","Computes the third quartile value of all non-NA contributing grid cells.","Finds the maximum value among all non-NA contributing grid cells.","Calculates the mean value of all non-NA contributing grid cells.","Identifies the most frequent value among all non-NA contributing grid cells.","Computes the root mean square of all non-NA contributing grid cells." ),`Suitable For`=c("Categorical rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Spatially extensive variables", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters", "Continuous rasters" ),Complexity =c("Simple", "Moderate", "Higher", "Higher", "High", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable" ),`Processing Time`=c("Fast", "Fast", "Moderate", "Moderate", "High", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable", "Variable" ),`Use Case`=c("Ideal for discrete data like land-use classifications; preserves original values without alteration.","Suitable for continuous data; provides smoother transitions, useful for elevation models or temperature data.","Appropriate for continuous data requiring smoother surfaces; beneficial for resampling satellite imagery.","Effective for continuous data where smoothness is crucial; often used in terrain modeling.","Best for high-quality image scaling; maintains sharpness and reduces aliasing in photographic images.","Useful for aggregating data like population counts; ensures the total sum remains consistent after resampling.","Applied in scenarios where the minimum value is of interest, such as finding the lowest temperature in a region.","Useful in statistical analyses to understand the lower distribution of data values.","Ideal for reducing the impact of outliers; provides a central tendency measure in skewed data distributions.","Beneficial for statistical analyses focusing on the upper distribution of data values.","Suitable for identifying peak values, such as maximum elevation or highest temperature in a dataset.","Commonly used for smoothing data; provides an overall average, useful in environmental data analyses.","Effective for categorical data to determine the most common category, such as predominant land cover type.","Applied in error analysis; useful for assessing the magnitude of variability in data values." ))# Display the table using gtresampling_methods |> gt::gt() |> gt::tab_header(title ="Resampling Methods for rasters in {terra}" ) |> gtExtras::gt_theme_espn()
Table 2: Comparison of Resampling Methods for rasters in
Resampling Methods for rasters in {terra}
Resampling Method
Description
Suitable For
Complexity
Processing Time
Use Case
Nearest Neighbor
Assigns the value of the nearest cell of the original raster to the target cell.
Categorical rasters
Simple
Fast
Ideal for discrete data like land-use classifications; preserves original values without alteration.
Bilinear Interpolation
Computes a weighted average of the four nearest cells from the original raster for the target cell.
Continuous rasters
Moderate
Fast
Suitable for continuous data; provides smoother transitions, useful for elevation models or temperature data.
Cubic Interpolation
Uses the values of the 16 nearest cells, applying third-order polynomial functions for smooth output.
Continuous rasters
Higher
Moderate
Appropriate for continuous data requiring smoother surfaces; beneficial for resampling satellite imagery.
Effective for continuous data where smoothness is crucial; often used in terrain modeling.
Lanczos Resampling
Uses the 36 nearest cells with a Lanczos windowed sinc function for smoother outputs.
Continuous rasters
High
High
Best for high-quality image scaling; maintains sharpness and reduces aliasing in photographic images.
Sum
Calculates the weighted sum of all non-NA contributing grid cells.
Spatially extensive variables
Variable
Variable
Useful for aggregating data like population counts; ensures the total sum remains consistent after resampling.
Min
Finds the minimum value among all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Applied in scenarios where the minimum value is of interest, such as finding the lowest temperature in a region.
Q1 (First Quartile)
Computes the first quartile value of all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Useful in statistical analyses to understand the lower distribution of data values.
Median (Med)
Computes the median value of all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Ideal for reducing the impact of outliers; provides a central tendency measure in skewed data distributions.
Q3 (Third Quartile)
Computes the third quartile value of all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Beneficial for statistical analyses focusing on the upper distribution of data values.
Max
Finds the maximum value among all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Suitable for identifying peak values, such as maximum elevation or highest temperature in a dataset.
Average
Calculates the mean value of all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Commonly used for smoothing data; provides an overall average, useful in environmental data analyses.
Mode
Identifies the most frequent value among all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Effective for categorical data to determine the most common category, such as predominant land cover type.
RMS (Root Mean Square)
Computes the root mean square of all non-NA contributing grid cells.
Continuous rasters
Variable
Variable
Applied in error analysis; useful for assessing the magnitude of variability in data values.
Alternatives to {terra} Functions
Why Alternatives? While {terra} is user-friendly and performs well for large rasters, it may not be the most efficient for extensive rasters or numerous raster files.
Key Alternatives via C++ Library GDAL (accessed via {gdalUtilities} or sf::gdal_utils() function):
gdalinfo:
Provides detailed information about a raster file (e.g., resolution, CRS, bounding box).
Useful for metadata exploration.
gdal_translate:
Converts raster files between formats.
Can also modify properties like compression or CRS (e.g., t_srs = "EPSG:4326").
gdal_rasterize:
Converts vector data into raster format.
Ideal for creating rasterized maps from vector datasets.
gdalwarp:
Performs raster mosaicing, cropping, resampling, and reprojection.
Essential for combining rasters, altering extents, or changing resolutions.
Integration with R:
GDAL functions are written in C++ but can be accessed in R using:
sf::gdal_utils(): Wrapper for calling GDAL functions.
gdalUtilities package: Dedicated functions for common GDAL tasks.
System Commands: Directly call GDAL commands from the terminal within R.
Input/output handling:
GDAL functions work with file paths. Output is often saved as a file rather than in-memory objects like {terra}’s SpatRaster.
When to Use GDAL:
For handling very large datasets or batch processing of raster files.
When advanced raster operations (e.g., raster mosaics) are required.
For compatibility with diverse raster file formats and global standards.
5.4 Exercises
E1.
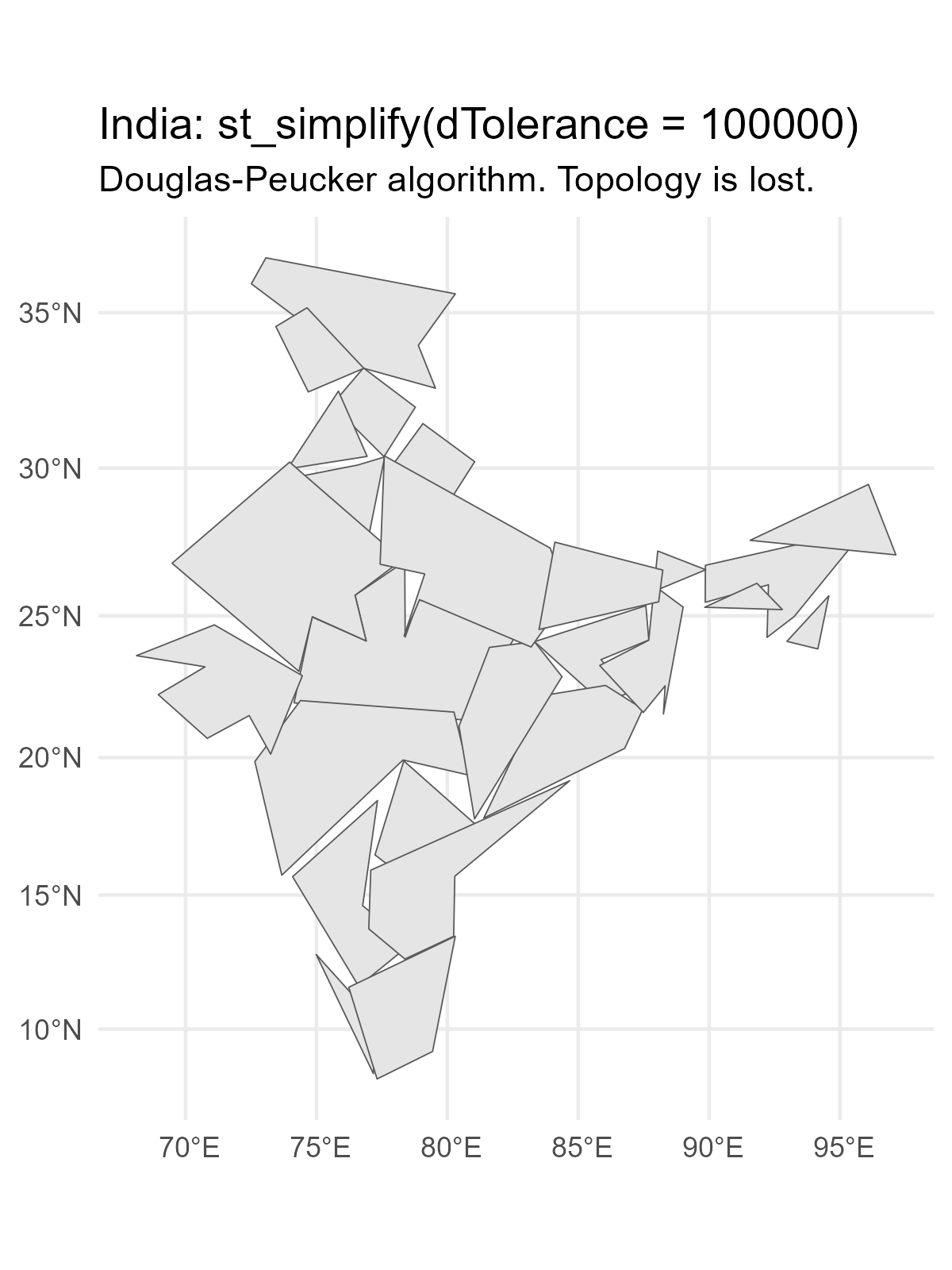
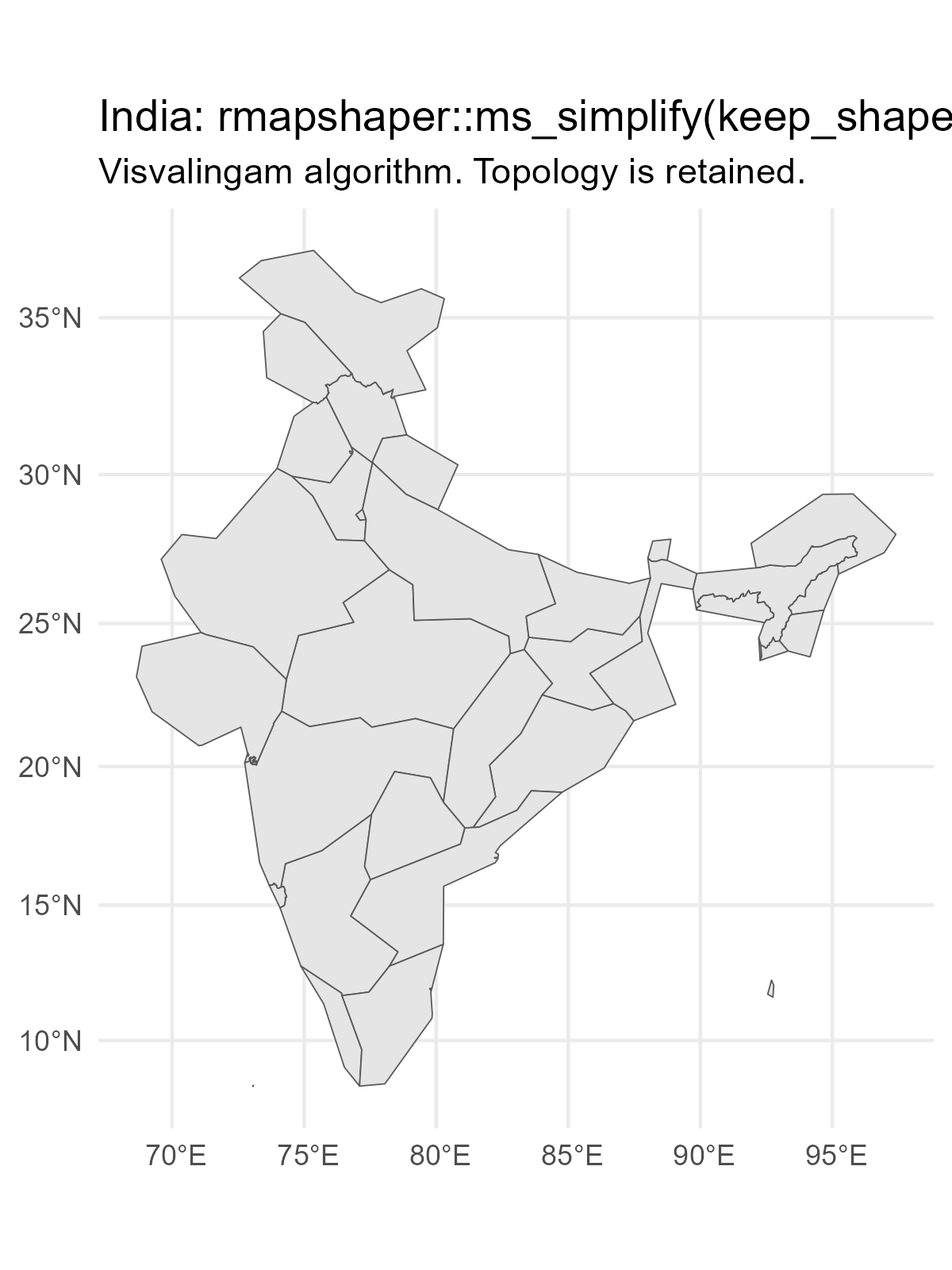
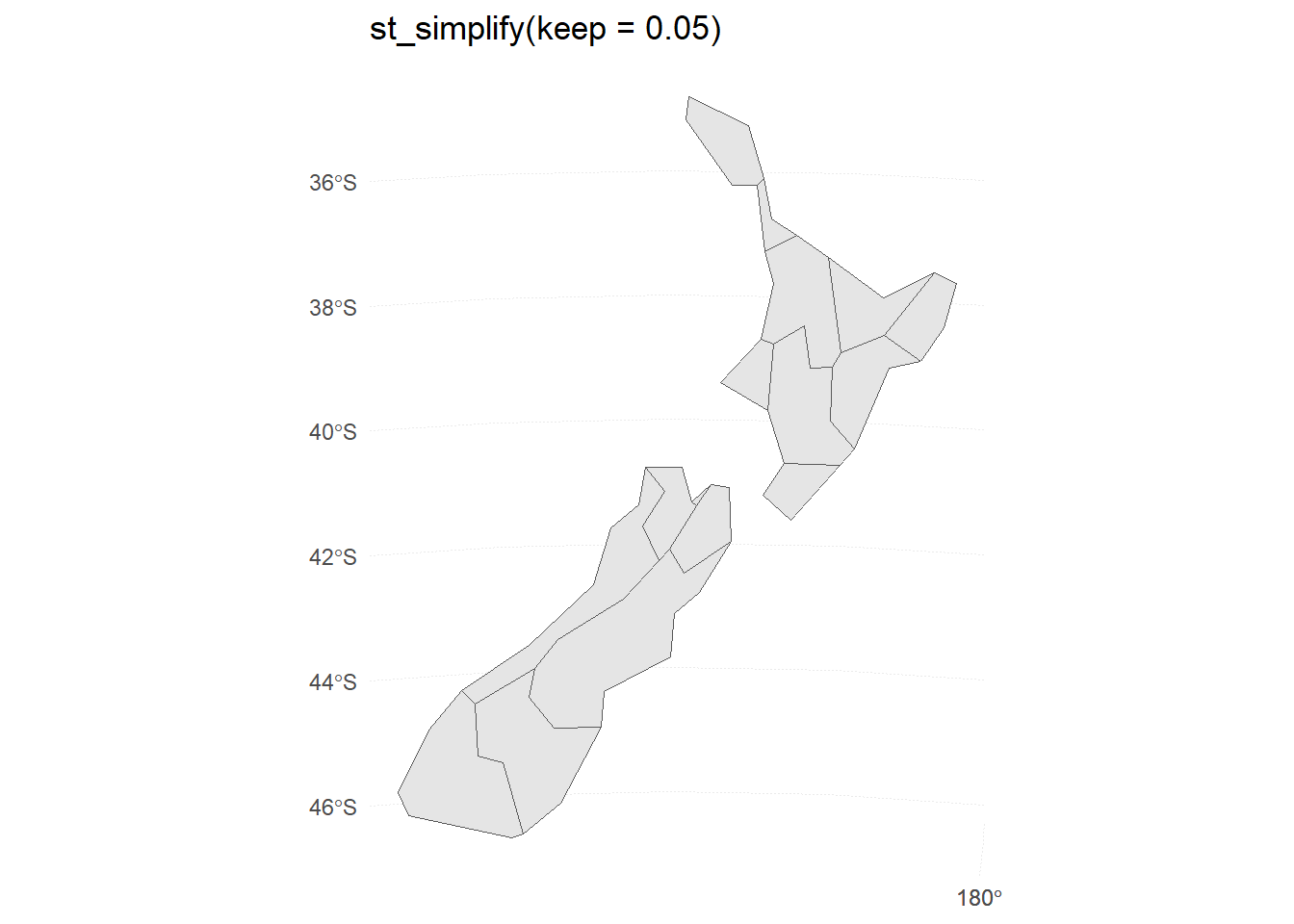
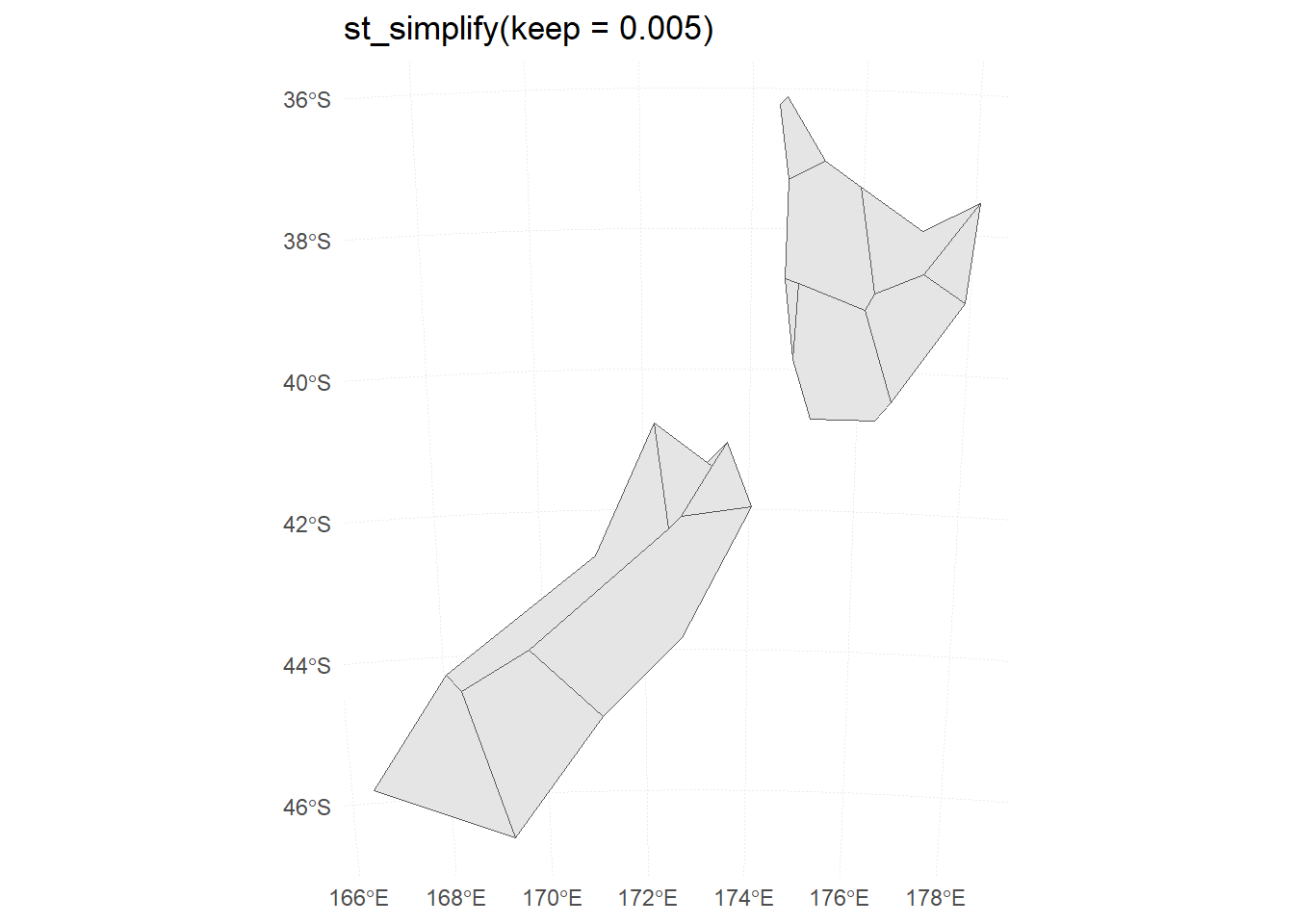
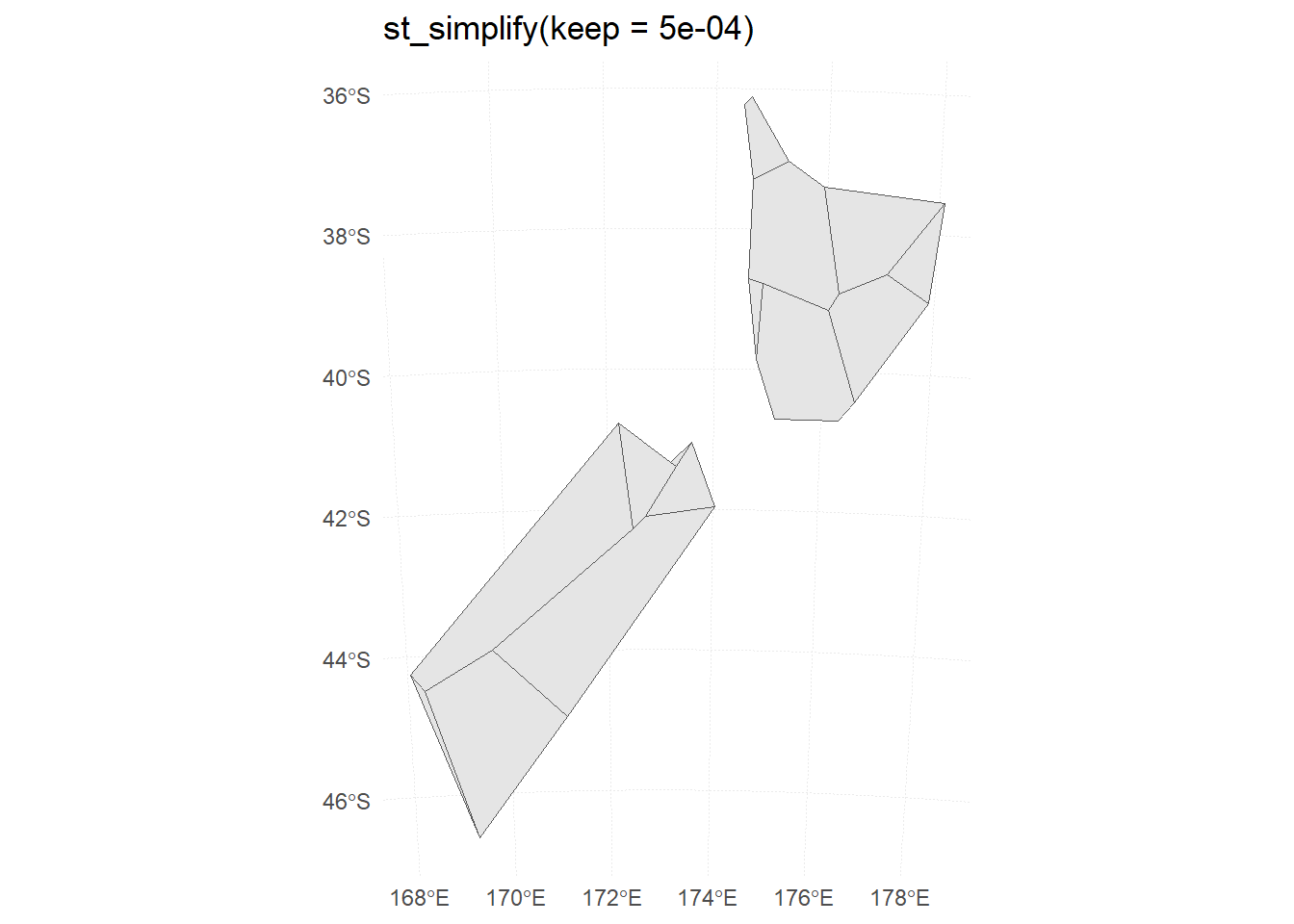
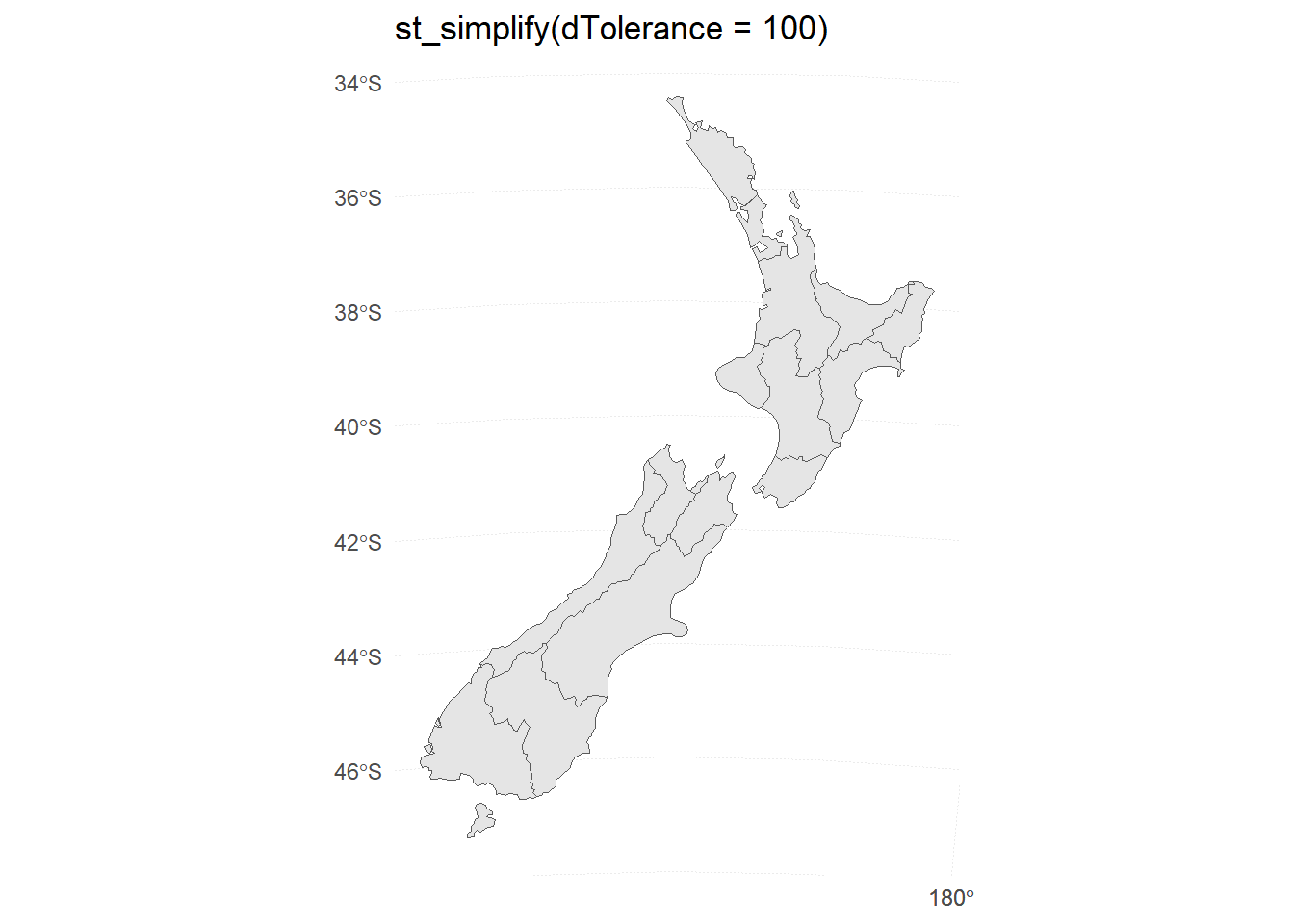
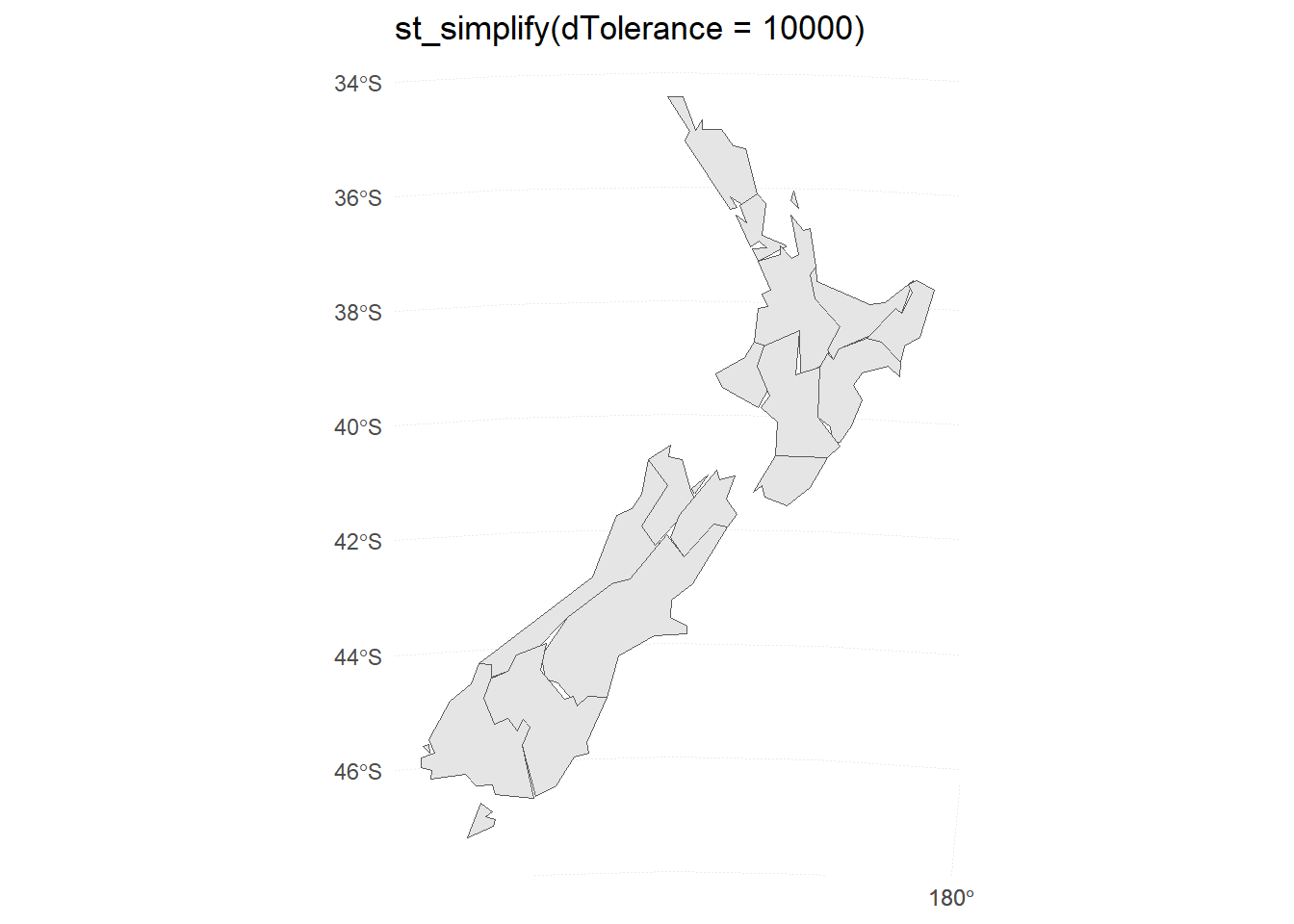
Generate and plot simplified versions of the nz dataset. Experiment with different values of keep (ranging from 0.5 to 0.00005) for ms_simplify() and dTolerance (from 100 to 100,000) st_simplify().
The plots for different levels of keep in ms_simplify() are shown in Figure 13.
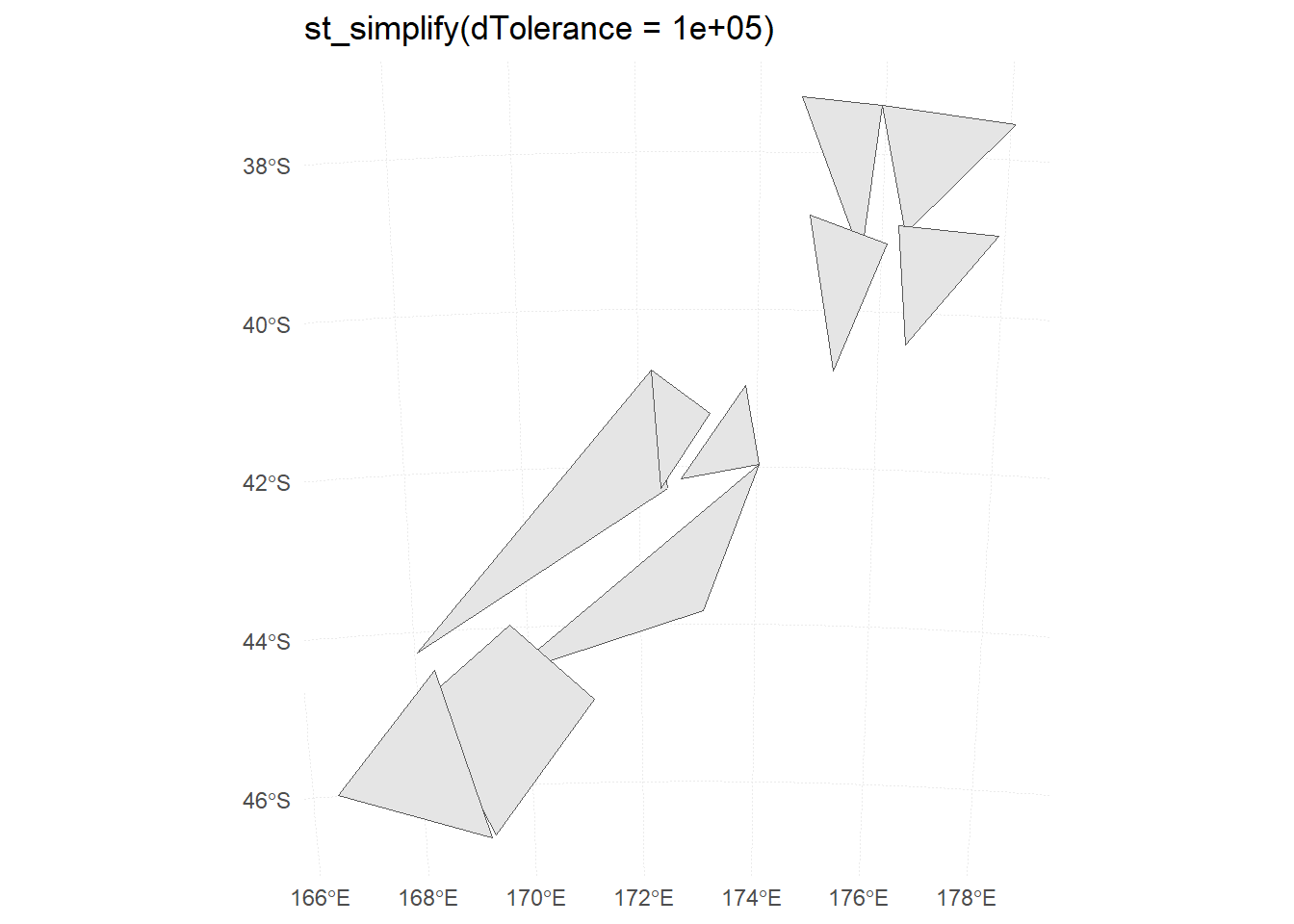
Figure 14: Different dTolerance levels in st_simplify()
At what value does the form of the result start to break down for each method, making New Zealand unrecognizable?
For the rmapshaper::ms_simplify() method, the result starts to break down at keep = 0.005 . For the sf::st_simplify() method, the result starts to break down around dTolerance = 10000 .
Advanced: What is different about the geometry type of the results from st_simplify() compared with the geometry type of ms_simplify()? What problems does this create and how can this be resolved?
The results from st_simplify() can be of multiple geometry types: MULTIPOLYGON or POLYGON, where as the results from ms_simplify() are always of a single geometry type: POLYGON.
Problems Created by st_simplify()
The invalid geometries produced by st_simplify() can lead to errors in subsequent spatial operations, such as overlays, spatial joins, or intersections.
For example, functions like st_intersection() or st_union() may fail or produce incorrect results when operating on invalid geometries.
Resolution: Using st_cast() to convert all geometries into a single type.
# Number of features in New Zealand Datasetnrow(nz)
[1] 16
# New Zealand data after st_simplify(): some features are MULTIPLOYGON, and some are POLYGONnz |>st_simplify(dTolerance =1000) |>st_as_sfc()
Geometry set for 16 features
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: 1090144 ymin: 4748537 xmax: 2089533 ymax: 6191874
Projected CRS: NZGD2000 / New Zealand Transverse Mercator 2000
First 5 geometries:
# Resolution: cast them into any one type using st_cast()nz |>st_simplify(dTolerance =1000) |>st_as_sfc() |>st_cast("POLYGON")
Geometry set for 16 features
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 1090144 ymin: 4823273 xmax: 2089533 ymax: 6191874
Projected CRS: NZGD2000 / New Zealand Transverse Mercator 2000
First 5 geometries:
Geometry set for 14 features
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 1091224 ymin: 4830067 xmax: 2049387 ymax: 6001802
Projected CRS: NZGD2000 / New Zealand Transverse Mercator 2000
First 5 geometries:
E2.
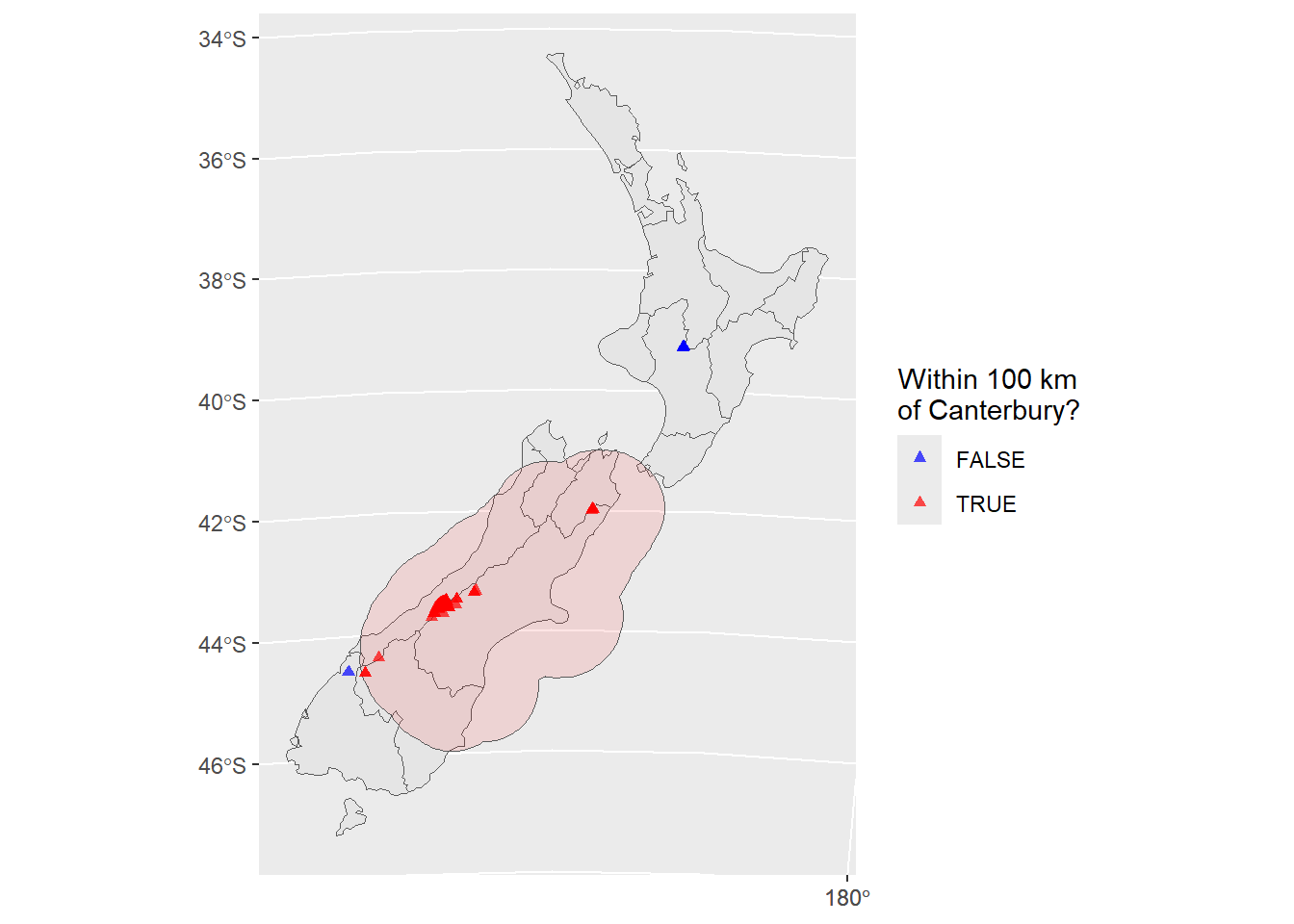
In the first exercise in Chapter Spatial Data Operations it was established that Canterbury region had 70 of the 101 highest points in New Zealand. Using st_buffer(), how many points in nz_height are within 100 km of Canterbury?
Out of the 101 heights, 95 of them fall within 100 km of the Canterbury region, as explained in the code below, and as shown in Figure 15
Most world maps have a north-up orientation. A world map with a south-up orientation could be created by a reflection (one of the affine transformations not mentioned in this chapter) of the world object’s geometry. Write code to do so. Hint: you can to use the rotation() function from this chapter for this transformation. Bonus: create an upside-down map of your country.
The multiplication of an sfc object with custom function rotation(180) can be used to create a world map with south-up orientation, as shown in Figure 16 (b)
Code
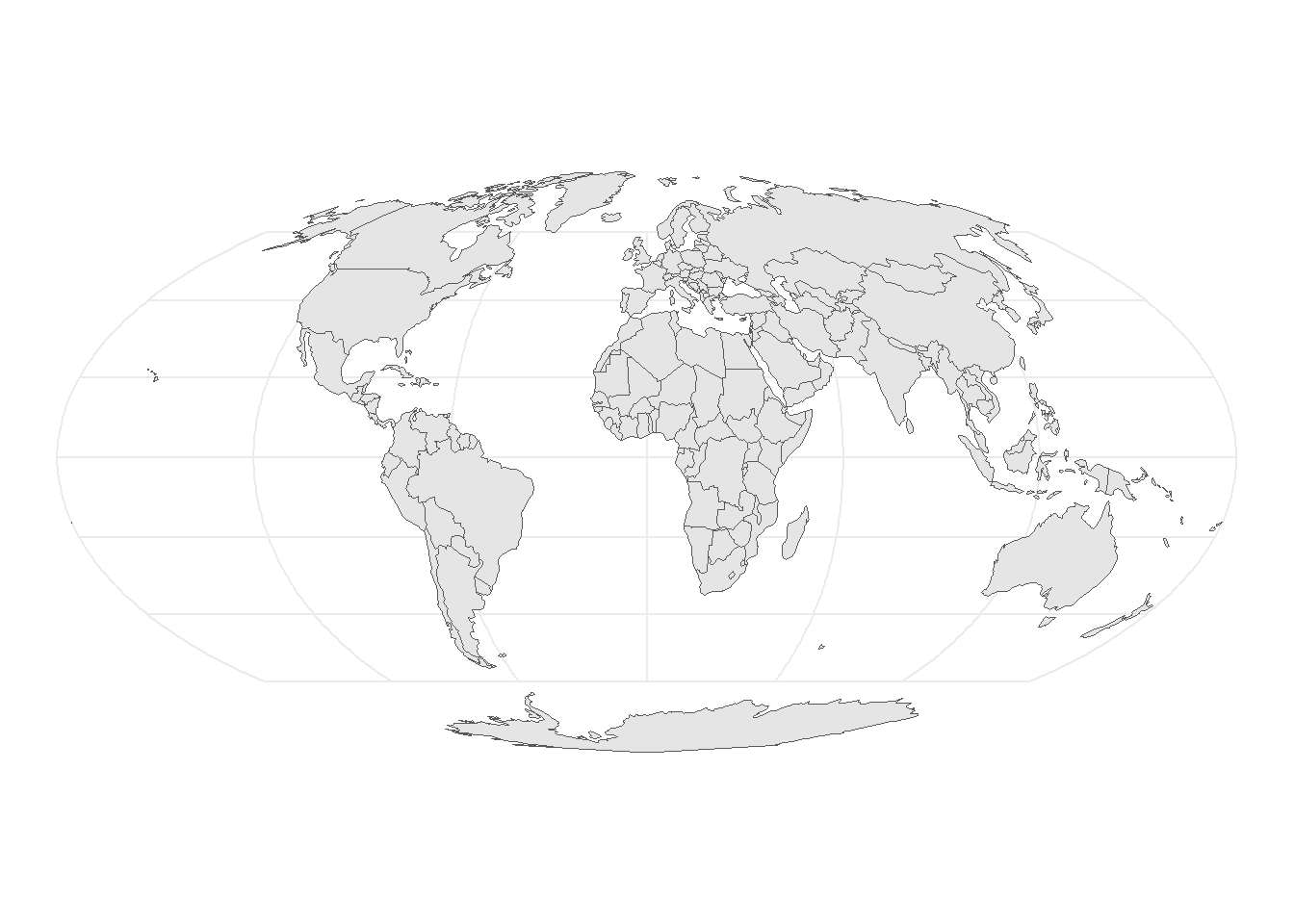
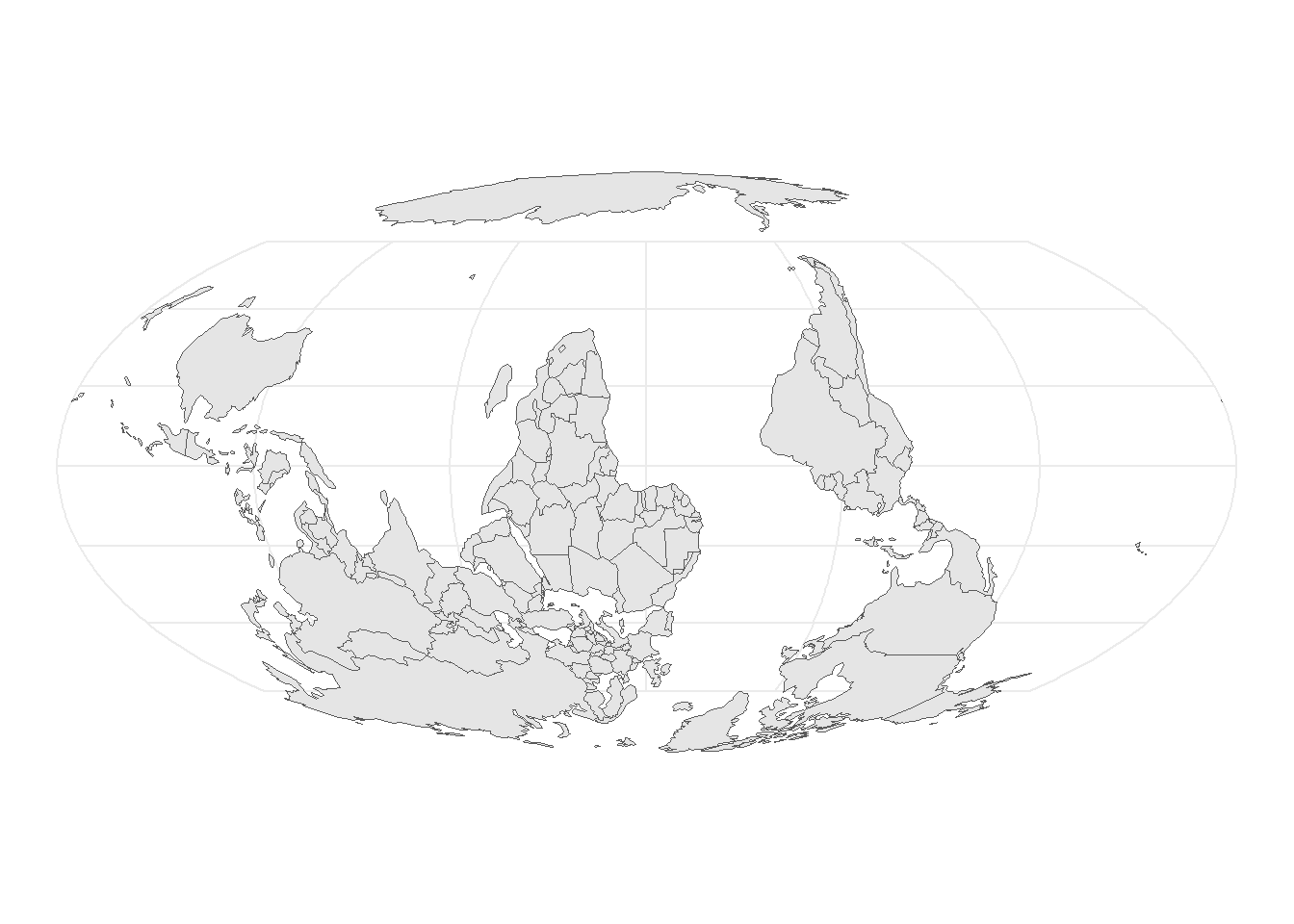
# Use the rotation function from the textbookrotation <-function(a){ r = a * pi /180#degrees to radiansmatrix(c(cos(r), sin(r), -sin(r), cos(r)), nrow =2, ncol =2)} data("world")world_up <- world |>st_geometry()world_rotate <- (world_up *rotation(180)) |>st_set_crs(st_crs(world_up))ggplot() +geom_sf(data = world_up) +coord_sf(crs ="ESRI:54009") +theme_minimal()ggplot() +geom_sf(data = world_rotate) +coord_sf(crs ="ESRI:54009") +theme_minimal()
(a) World map upright
(b) World map upside-down
Figure 16: Using a custom rotation() and multiplying the sfc object with rotation(180)
E5.
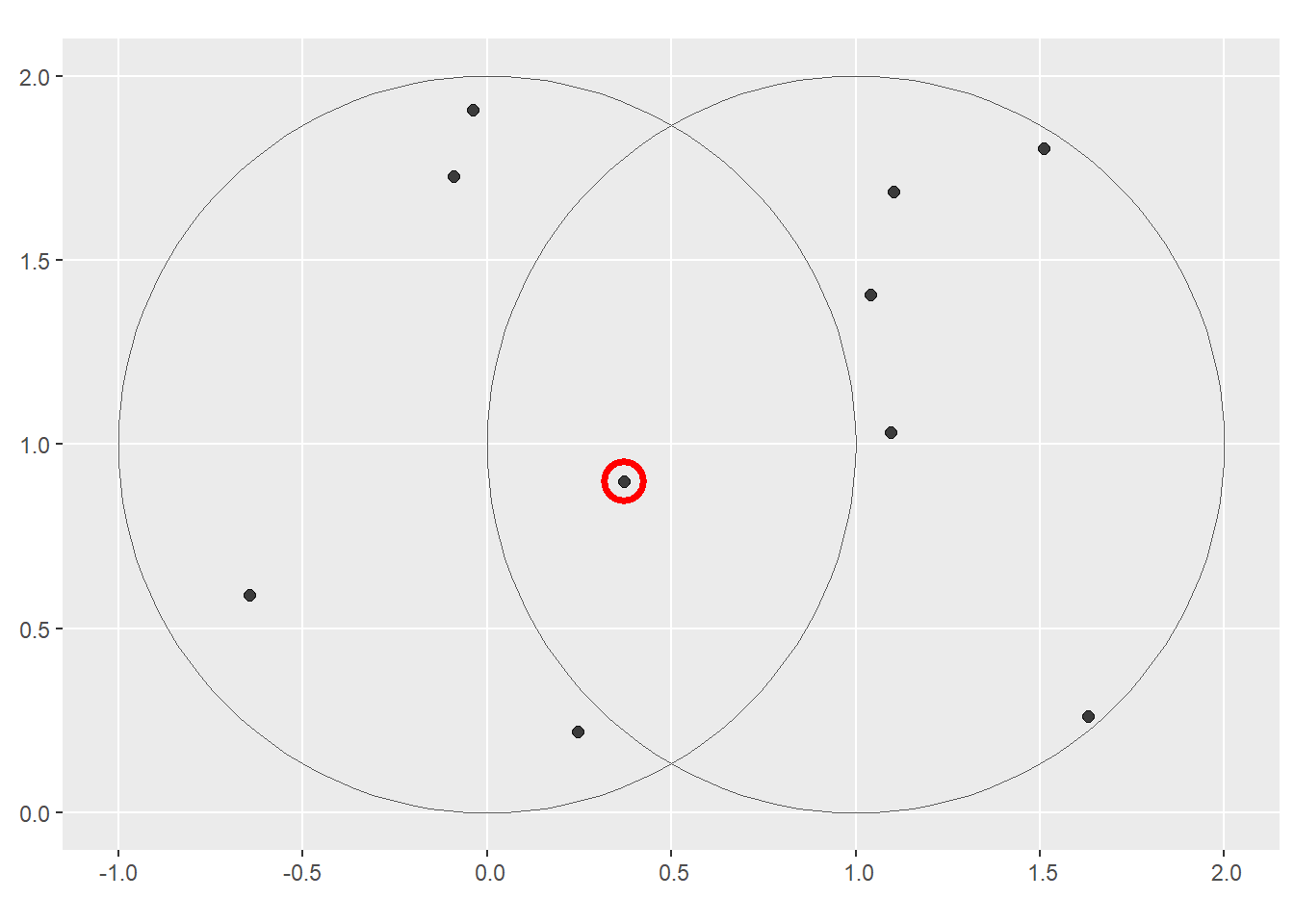
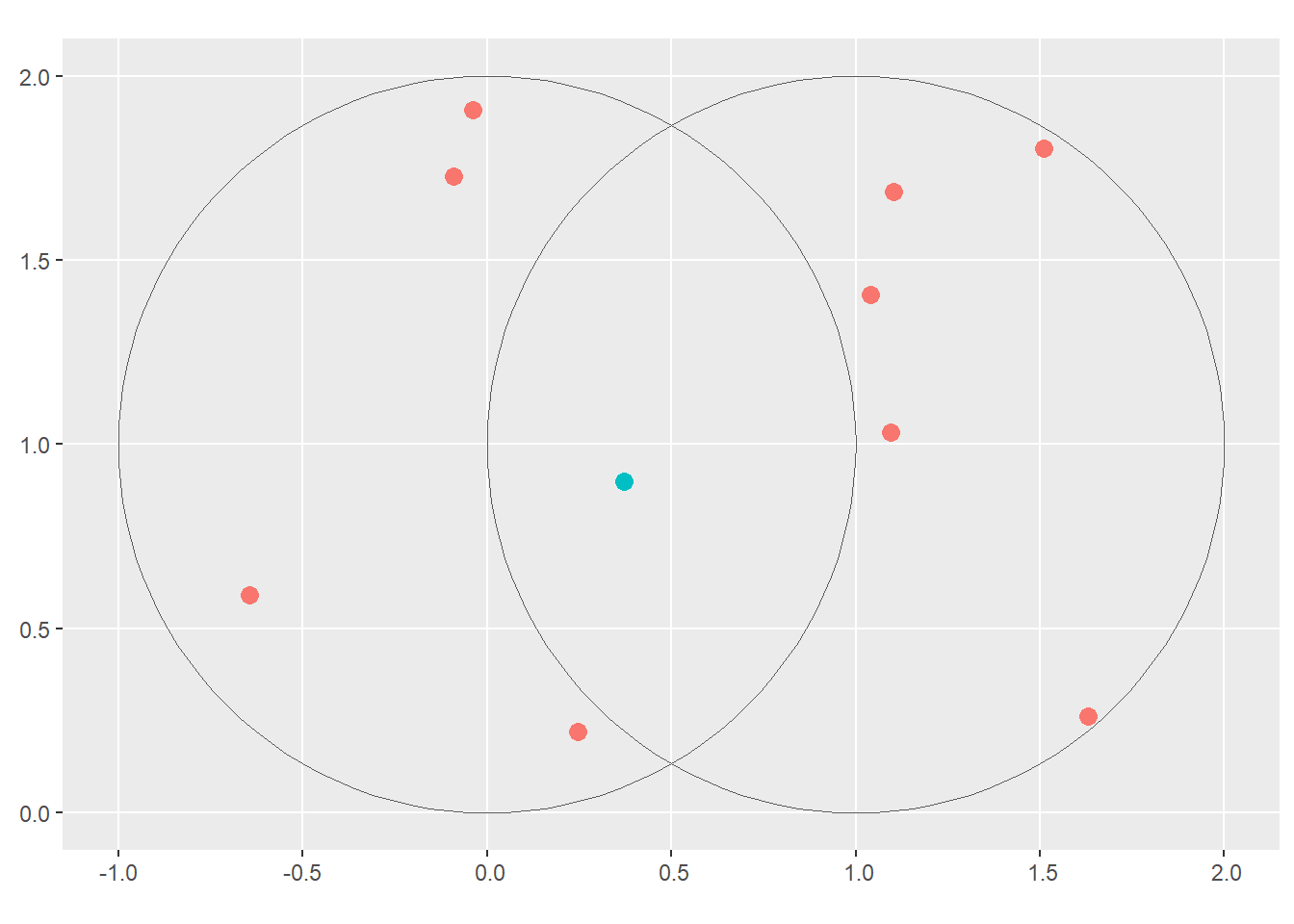
Run the code in Section 5.2.6. With reference to the objects created in that section, subset the point in p that is contained within xandy.
# Create the two pointsb <-st_sfc(st_point(c(0, 1)), st_point(c(1, 1))) # Create circles around those pointsb <-st_buffer(b, dist =1)# Name x and y -- the two circlesx = b[1]y = b[2]x_and_y =st_intersection(x, y)# Bounding box of x and ybb =st_bbox(st_union(x, y))# Covert bounding box into a polygonbox =st_as_sfc(bb)set.seed(2024)p =st_sample(x = box, size =10)
Using base subsetting operators. Answer is shown in Figure 17
Calculate the length of the boundary lines of US states in meters. Which state has the longest border and which has the shortest? Hint: The st_length function computes the length of a LINESTRING or MULTILINESTRING geometry.
The longest border is of Texas (4,959.8 km) and the shortest border is of District of Columbia (60.2 km). The complete list is at Table 3 .
Table 3: The border length of the different states in USA
E7.
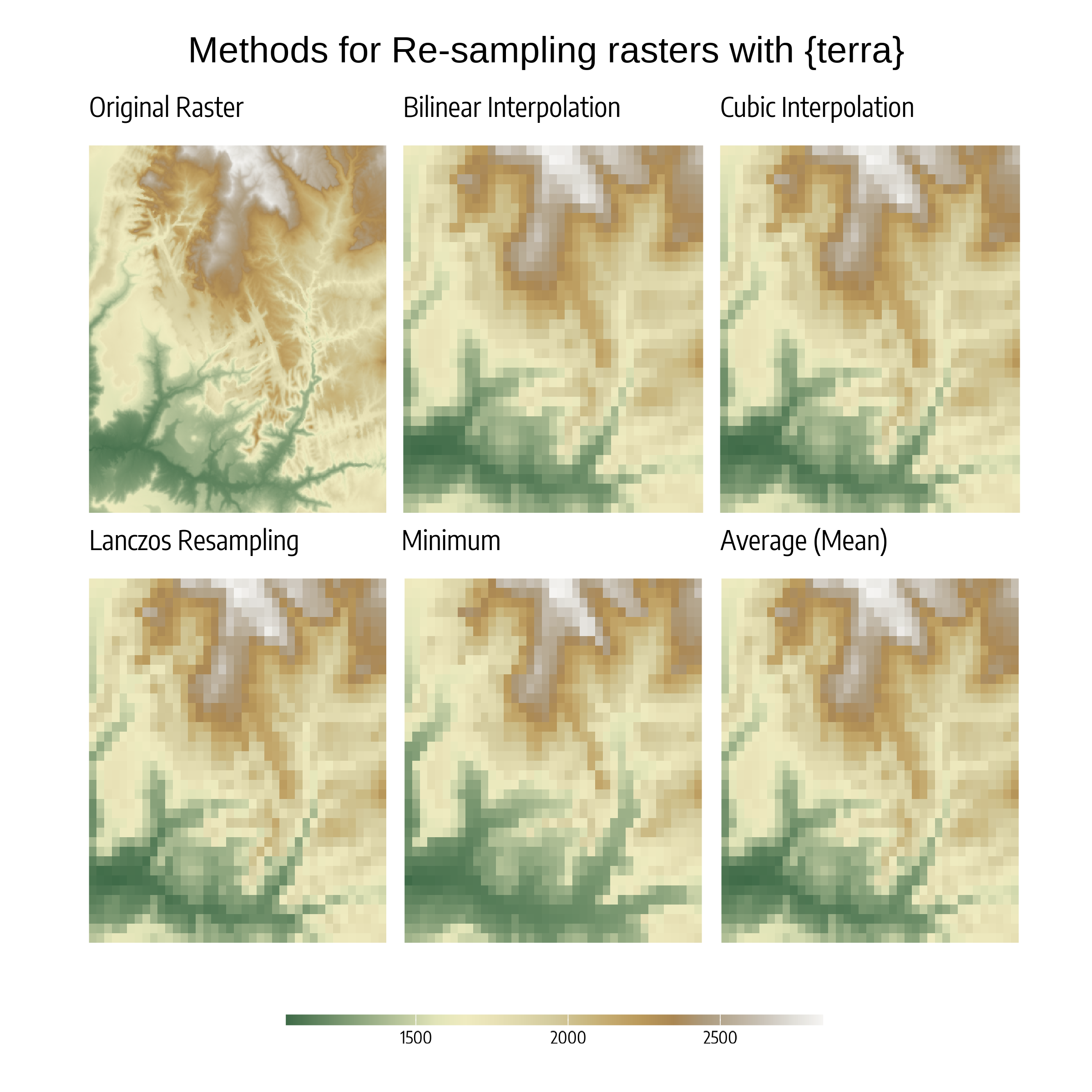
Read the srtm.tif file into R (srtm = rast(system.file("raster/srtm.tif", package = "spDataLarge"))). This raster has a resolution of 0.00083 * 0.00083 degrees. Change its resolution to 0.01 * 0.01 degrees using all of the methods available in the terra package. Visualize the results. Can you notice any differences between the results of these re-sampling methods?
The different methods of resampling rasters and their demonstration is in Figure 19
Figure 20: Using terra::aggregate() to make resolution of 0.01
References
Loecher, Markus, and Karl Ropkins. 2015. “RgoogleMapsandloa: UnleashingRGraphics Power on Map Tiles.”Journal of Statistical Software 63 (4). https://doi.org/10.18637/jss.v063.i04.