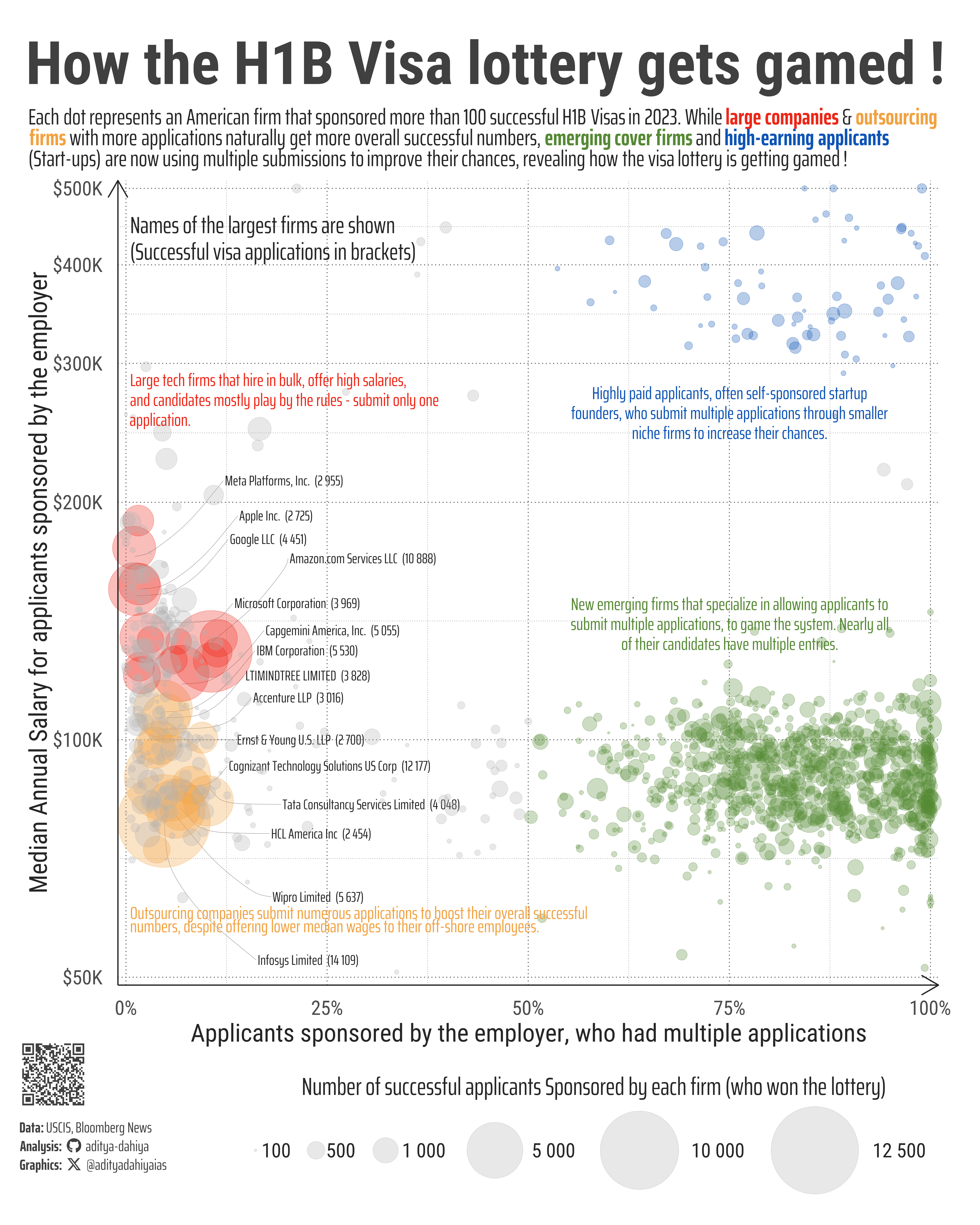
Unveiling how firms and applicants leverage multiple submissions and salaries to game the H1B visa lottery system.
Data Is Plural
Governance
Author
Aditya Dahiya
Published
October 2, 2024
A recent Bloomberg News investigation into the U.S. government’s annual H-1B lottery revealed that “thousands of companies gained an unfair advantage by securing extra lottery tickets.” To support these findings, Bloomberg obtained data on all H-1B lottery registrations, selections, and petitions for fiscal years 2021 through 2024 after filing a Freedom of Information Act (FOIA) lawsuit against the Department of Homeland Security. The dataset includes details such as each registration’s employer, the proposed beneficiary’s gender, nationality, and birth year. For registrations that led to visa petitions, additional information is provided, including the worksite, salary, job title, and the beneficiary’s field of study. The data can be accessed as part of their investigation, shared by reporter Eric Fan.
Figure 1: The scatterplot shows how different firms are using various strategies to navigate the H1B visa lottery. The red dots, representing large U.S. tech companies like Amazon and Google, offer high salaries and follow a straightforward approach, submitting only one application per candidate. On the other hand, the orange dots—Indian outsourcing firms such as Infosys and Wipro—submit many applications for lower-paying positions, relying on sheer volume to get a portion of their candidates selected. The green dots show newer firms that have emerged specifically to help applicants submit multiple entries, greatly increasing their chances. Lastly, the blue dots represent highly paid applicants, often start-up founders, who also use multiple applications but through smaller, niche companies to boost their odds.
Loading libraries & data
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(seecolor) # To print and view colourslibrary(patchwork) # Combining plotslibrary(httr) # Download fileslibrary(zip) # Handle ZIP fileslibrary(countrycode)# Get Data Dictionary used by Bloombergdictionary <- openxlsx::read.xlsx("https://github.com/BloombergGraphics/2024-h1b-immigration-data/raw/refs/heads/main/TRK_13139_I129_H1B_Registrations_FY21_FY24_FOIA_FIN.xlsx",sheet ="Data Dictionary",rows =1:57,cols =1:2) |> janitor::clean_names()# Single registrations data# Download the ZIP file from the URLurl <-"https://github.com/BloombergGraphics/2024-h1b-immigration-data/blob/main/TRK_13139_FY2024_single_reg.zip?raw=true"temp_zip <-tempfile(fileext =".zip")GET(url, write_disk(temp_zip, overwrite =TRUE))# Unzip the file to a temporary directorytemp_dir <-tempdir()unzip(temp_zip, exdir = temp_dir)# Read the CSV file into Rcsv_file <-file.path(temp_dir, "TRK_13139_FY2024_single_reg.csv")rawdf_single <-read_csv(csv_file) |> janitor::clean_names()# Multiple registrations dataurl1 <-"https://github.com/BloombergGraphics/2024-h1b-immigration-data/blob/main/TRK_13139_FY2024_multi_reg.zip?raw=true"temp_zip <-tempfile(fileext =".zip")GET(url1, write_disk(temp_zip, overwrite =TRUE))# Unzip the file to a temporary directorytemp_dir <-tempdir()unzip(temp_zip, exdir = temp_dir)# Read the CSV file into Rcsv_file <-file.path(temp_dir, "TRK_13139_FY2024_multi_reg.csv")rawdf_multi <-read_csv(csv_file) |> janitor::clean_names()# Clean up temporary filesunlink(temp_zip) # Delete the temporary zip file# Remove the temporary directory and its contents# unlink(temp_dir, recursive = TRUE) rm(csv_file, temp_dir, temp_zip, url, url1)print(object.size(rawdf_single), units ="Mb")print(object.size(rawdf_multi), units ="Mb")
Total number of applicants by the country and success rates.
# =========================================# Understanding the meaning of variable "ben_multi_reg_ind"# Indicator of multiple registrations for beneficiary (a value of # 1 represents a registration for a beneficiary who has multiple # registrations with different employers)# rawdf_single |> # count(ben_multi_reg_ind)# # rawdf_multi |> # filter(!is.na(ben_multi_reg_ind))# ==========================================# Analysis Question# Are employer_name and FEIn matched 1-is-to-1: Answer: No. # So better to stick to employer_name.# rawdf_multi |> # count(employer_name, fein) |> # select(-n) |> # count(employer_name) |> # filter(n > 1)# =========================================# Combine multiple and single applications' datarawdf <-bind_rows( rawdf_multi, rawdf_single ) |>select( employer_name, state, status_type, first_decision, ben_multi_reg_ind,# For fuzzy matching to find duplicates# since we dont have person's ID number to distinguish uniquely country_of_birth, country_of_nationality, ben_year_of_birth,# Salary wage_amt, wage_unit )# =====================================# Check status_type vs. first decisions# They are similar in name, except that some selected persons will# ultimately have their visas rejected. So, for purposes of analysing# the lottery, we take the variable "status_type" only.rawdf |>count(status_type, first_decision)# Data from on percentage of applications of a sponsor organization # that are multiple entry applicationsdf4 <- rawdf |>count(employer_name, ben_multi_reg_ind, sort = T) |>mutate(ben_multi_reg_ind =case_when( ben_multi_reg_ind ==0~"single_entry", ben_multi_reg_ind ==1~"multiple_entry",.default ="others" ) ) |>pivot_wider(id_cols = employer_name,names_from = ben_multi_reg_ind,values_from = n ) |>replace_na(replace =list(single_entry =0,multiple_entry =0,others =0 ) ) |>mutate(total = single_entry + multiple_entry + others,perc_single = single_entry / total,perc_multiple = multiple_entry / total )# Percentage of applicants for each df5 <- rawdf |>count(employer_name, status_type, sort = T) |>mutate(status_type =str_to_lower(status_type)) |>filter(status_type %in%c("eligible", "selected")) |>pivot_wider(id_cols = employer_name,names_from = status_type,values_from = n ) |>replace_na(replace =list(eligible =0,selected =0 ) ) |>mutate(perc_selected = selected / (eligible + selected) )wages_units <-c("YEAR", "HOUR", "MONTH", "WEEK")df6 <- rawdf |>filter(wage_unit %in% wages_units) |>mutate(wage_amt =case_when( wage_unit =="YEAR"~ wage_amt, wage_unit =="HOUR"~ wage_amt *8760, wage_unit =="MONTH"~ wage_amt *12, wage_unit =="WEEK"~ wage_amt *52,.default =NA ) ) |>group_by(employer_name) |>summarise(wage =median(wage_amt, na.rm = T) )plotdf <- df4 |>left_join(df5) |>left_join(df6) |>mutate(cluster =case_when( ((wage >250000) & (perc_multiple >0.5)) ~"A", ((total >1000) & (perc_multiple <0.5) & (wage >110000)) ~"B1", ((total >1000) & (perc_multiple <0.5) & (wage <110000)) ~"B2", ((total >1000) & (perc_multiple <0.5)) ~"B1", ((perc_multiple >0.5) & (wage <200000)) ~"C",.default ="D" ) )# Do a k-means clustering to identify patters# Number of clusters in K-Mean Clustering# clus_nos = 10# set.seed(42)# k_out <- kmeans(# plotdf |> select(perc_multiple, wage) |> as.matrix(),# centers = clus_nos# )# plotdf1 <- plotdf |> # mutate(cluster = as_factor(k_out$cluster))# # plotdf1 |> # count(cluster, sort = T) |> # mutate(cluster_var = LETTERS[1:clus_nos])# The top n companies / visa sponsors to be labelledlabels_df <- plotdf |>slice_max(order_by = total, n =15)
Visualization Parameters
Code
# Font for titlesfont_add_google("Roboto Condensed",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Roboto Condensed",family ="body_font") showtext_auto()bg_col <-"white"text_col <-"grey15"text_hil <-"grey25"# mypal <- paletteer::paletteer_d("ltc::trio1")mypal <- paletteer::paletteer_d("suffrager::CarolMan")mypal <- mypal[c(4, 1, 2, 3)]bts <-90# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_title <-"How the H1B Visa lottery gets gamed !"plot_subtitle <- glue::glue("Each dot represents an American firm that sponsored more than 100 successful H1B Visas in 2023. While <b style='color:{mypal[2]}'>large companies</b> & <b style='color:{mypal[3]}'>outsourcing<br>firms</b> with more applications naturally get more overall successful numbers, <b style='color:{mypal[4]}'>emerging cover firms</b> and <b style='color:{mypal[1]}'>high-earning applicants</b><br>(Start-ups) are now using multiple submissions to improve their chances, revealing how the visa lottery is getting gamed !")plot_caption <-paste0("**Data:** USCIS, Bloomberg News", "<br>**Analysis:** ", social_caption_1, "<br>**Graphics:** ", social_caption_2 )annotation_1 <-"Highly paid applicants, often self-sponsored startup founders, who submit multiple applications through smaller niche firms to increase their chances."annotation_2 <-"Large tech firms that hire in bulk, offer high salaries, and candidates mostly play by the rules - submit only one application."annotation_3 <-"Outsourcing companies submit numerous applications to boost their overall successful numbers, despite offering lower median wages to their off-shore employees."annotation_4 <-"New emerging firms that specialize in allowing applicants to submit multiple applications, to game the system. Nearly all of their candidates have multiple entries."rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)
The static plot
Code
# The actual plotg <- plotdf |># Keep only companies with more than 100 visa applicationsfilter(total >=100) |># Start Plotggplot(mapping =aes(x = perc_multiple,y = wage,size = total,colour = cluster ) ) +# Label the biggest / important employers ggrepel::geom_text_repel(data = labels_df,mapping =aes(label =paste0( employer_name," (", number(total), ")" ) ),size = bts /5,family ="caption_font",colour = text_col,lineheight =0.3,hjust =0,min.segment.length =unit(2, "mm"),direction ="y",force =20,segment.size =0.1,segment.curvature =-0.1,force_pull =1,nudge_x =0.15 ) +# The points for each company / applicant firmgeom_point(alpha =0.3,position =position_jitter(height =0.02,width =0 ) ) +# Add Text-Annotationsannotate(geom ="text",label =str_wrap(annotation_1, 60),lineheight =0.3,family ="caption_font",colour = mypal[1],x =0.75, y =280000,hjust =0.5,vjust =1,size = bts /4 ) +annotate(geom ="text",label =str_wrap(annotation_2, 60),lineheight =0.3,family ="caption_font",colour = mypal[2],x =0.005, y =250000,hjust =0,vjust =0,size = bts /4 ) +annotate(geom ="text",label =str_wrap(annotation_3,90),lineheight =0.2,family ="caption_font",colour = mypal[3],x =0.005, y =57000,hjust =0,vjust =0,size = bts /4 ) +annotate(geom ="text",label =str_wrap(annotation_4, 60),lineheight =0.3,family ="caption_font",colour = mypal[4],x =0.75, y =130000,hjust =0.5,vjust =0,size = bts /4 ) +annotate(geom ="text",label ="Names of the largest firms are shown\n(Successful visa applications in brackets)",lineheight =0.3,family ="caption_font",colour = text_col,x =0.005, y =460000,hjust =0,vjust =1,size = bts /3 ) +# Scales and Coordinatesscale_x_continuous(labels =label_percent(),expand =expansion(0.01) ) +scale_y_continuous(oob = scales::squish,trans ="log10",limits =c(50000, 500000),breaks =c(5e4, 1e5, 2e5, 3e5, 4e5, 5e5),labels =c("$50K", "$100K", "$200K", "$300K", "$400K", "$500K"),expand =expansion(0.01) ) +scale_size_continuous(range =c(1, 50),breaks =c(100, 500, 1000,5000, 10000, 12500),labels =number(c(100, 500, 1000,5000, 10000, 12500) ) ) +scale_colour_manual(values =c(mypal, "grey70") ) +guides(colour ="none",size =guide_legend(direction ="horizontal",override.aes =list(colour ="grey70" ),nrow =1 ) ) +coord_cartesian(clip ="off") +# Labels and Themeslabs(title = plot_title,subtitle =str_wrap(plot_subtitle, 135),caption = plot_caption,x ="Applicants sponsored by the employer, who had multiple applications",y ="Median Annual Salary for applicants sponsored by the employer",size ="Number of successful applicants Sponsored by each firm (who won the lottery)" ) +theme_minimal(base_family ="body_font",base_size = bts ) +theme(# Overall Plotpanel.grid.minor =element_line(linetype =3,linewidth =0.3,colour ="grey50" ),panel.grid.major =element_line(linetype =3,linewidth =0.5,colour ="grey30" ),text =element_text(margin =margin(0,0,0,0, "mm"),colour = text_col,lineheight =0.3 ),plot.title.position ="plot",plot.margin =margin(5,15,5,10, "mm"),# Axesaxis.line =element_line(colour = text_col,linewidth =0.7,arrow =arrow(length =unit(8, "mm")) ),axis.ticks =element_blank(),axis.ticks.length =unit(0, "mm"),axis.text =element_text(margin =margin(0,0,0,0, "mm") ),axis.title.x =element_text(margin =margin(2,0,0,0, "mm") ),axis.title.y =element_text(margin =margin(0,0,0,0, "mm") ),# Labelsplot.title =element_text(family ="title_font",margin =margin(10,0,3,0, "mm"),size =2.4* bts,hjust =0.5,colour = text_hil,face ="bold" ),plot.subtitle =element_textbox(margin =margin(2,0,4,0, "mm"),hjust =0.5,size =0.9* bts,family ="caption_font" ),plot.caption =element_textbox(family ="caption_font",hjust =0,margin =margin(-35,0,-5,-40, "mm"),size =0.6* bts,colour = text_hil,lineheight =0.4 ),# Legendlegend.position ="bottom",legend.title.position ="top",legend.title =element_text(margin =margin(0,0,-2,0, "mm"),hjust =0.5,family ="caption_font" ),legend.text =element_text(margin =margin(0,5,0,0, "mm") ),legend.margin =margin(-20,0,0,0, "mm"),legend.key.spacing =unit(0, "mm"),legend.box.margin =margin(0,0,0,0, "mm"),legend.location ="plot",legend.justification =1 )ggsave(filename = here::here("data_vizs", "dip_h1b_visas.png"),plot = g,width =400, # Best Twitter Aspect Ratio = 5:4height =500, units ="mm",bg ="white")
Add a QR code
Code
# QR Code for the ploturl_graphics <-paste0("https://aditya-dahiya.github.io/projects_presentations/projects/",# The file name of the current .qmd file"dip_h1b_visas",".qmd")# remotes::install_github('coolbutuseless/ggqr')# library(ggqr)plot_qr <-ggplot(data =NULL, aes(x =0, y =0, label = url_graphics) ) + ggqr::geom_qr(colour = text_hil, fill = bg_col,size =1 ) +# labs(caption = "Full Analysis here") +coord_fixed() +theme_void() +theme(plot.background =element_rect(fill ="transparent", colour ="transparent" ) )g_full <- g +inset_element(p = plot_qr,left =0, right =0.1,top =0.17, bottom =0.07,align_to ="full",clip =FALSE ) +plot_annotation(theme =theme(plot.background =element_rect(fill ="transparent", colour ="transparent" ),panel.background =element_rect(fill ="transparent", colour ="transparent" ) ) )ggsave(filename = here::here("data_vizs", "dip_h1b_visas.png"),plot = g_full,width =400, # Best Twitter Aspect Ratio = 5:4height =500, units ="mm",bg ="white")
Savings the graphics
Code
ggsave(filename = here::here("data_vizs", "dip_h1b_visas.png"),plot = g,width =210*2, # Best Twitter Aspect Ratio = 5:4height =297*2, units ="mm",bg ="white")library(magick)# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "dip_h1b_visas.png")) |>image_resize(geometry ="400") |>image_write( here::here("data_vizs", "thumbnails", "dip_h1b_visas.png" ) )