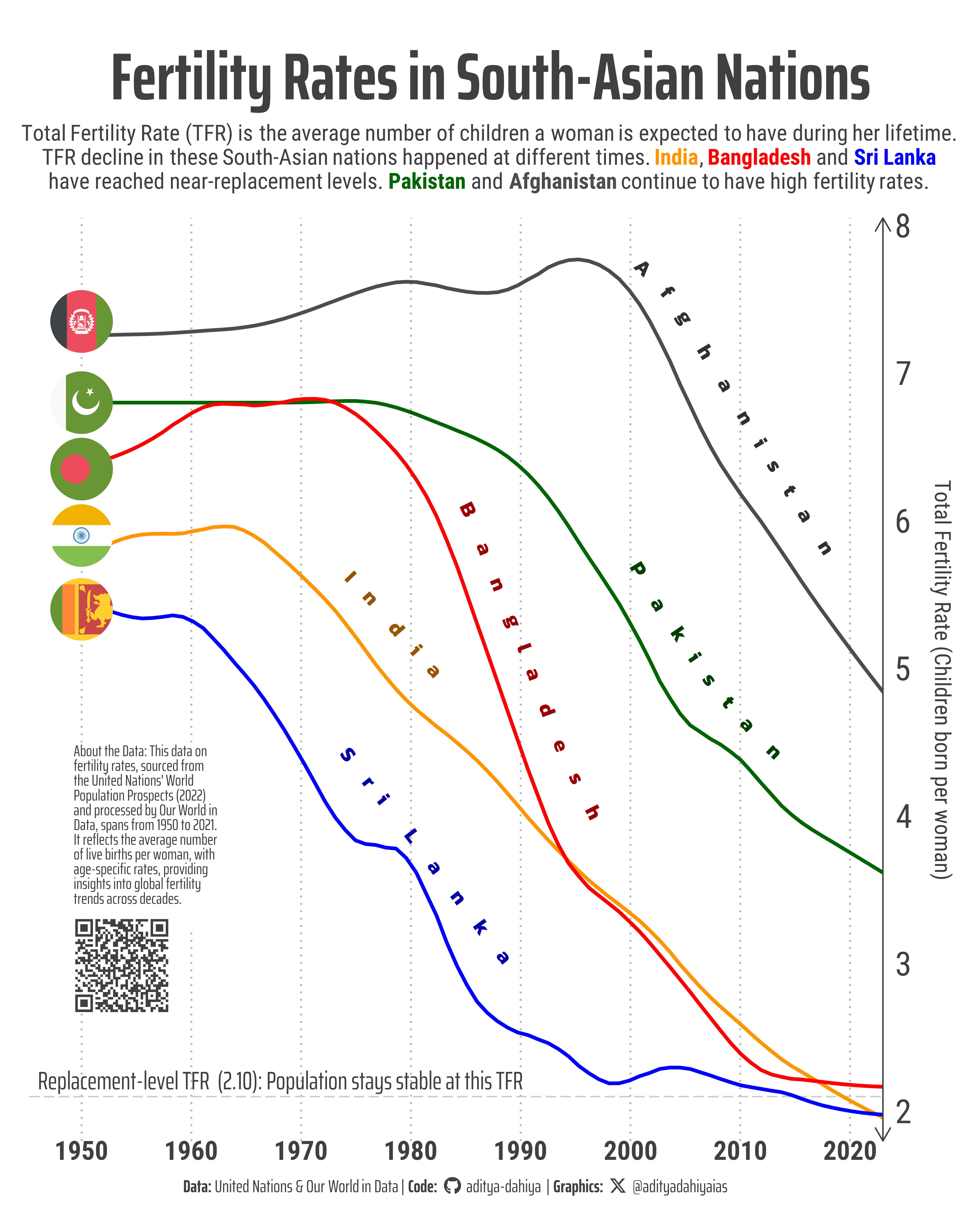
Comparing rates and timings of change of fertility amongst five South-Asian countries.
A4 Size Viz
Our World in Data
Public Health
{geomtextpath}
Author
Aditya Dahiya
Published
July 15, 2024
The data used in this graphic is sourced from the United Nations’ World Population Prospects(2022) and processed by Our World in Data. It encompasses the Total Fertility Rate (TFR) for the top 10 most populous countries from the 1950s to 2021. TFR is the average number of children a woman is expected to have during her lifetime.
This line graph shows that the TFR fell at different times in the five South-Asian Nations. Pakistan and Afghanistan continue to have high fertility rates. India, Bangladesh and Sri Lanka have achieved near-replacement levels of fertility. TFR in Sri Lanka and Bangladesh fell early and rapidly, while India’s TFR has declined slowly yet steadily.
Figure 1: A line graph on fertility rates from 1950 to 2021 in five South Asian Nations. Using geom_textline(), the names of the countries have been inserted along the lines.
How I made this graphic?
Getting the data
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidylibrary(owidR) # Get data from Our World in R# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text supportlibrary(showtext) # Display fonts in ggplot2library(colorspace) # To lighten and darken colourslibrary(patchwork) # Combining plots# ggbump package for Bump-Charts and Sigmoid lines# install.packages("ggbump")library(geomtextpath) # Text on the path # Data on fertility rates# search1 <- owidR::owid_search("fertility")df1 <-owid("children-per-woman")
Visualization Parameters
Code
# Font for titlesfont_add_google("News Cycle",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Roboto Condensed",family ="body_font") # Font for Country Namesfont_add_google("Kanit",family ="cn_font")showtext_auto()# Colour Palette# mypal1 <- paletteer::paletteer_d("waRhol::marilyn_orange_62")mypal2 <- paletteer::paletteer_d("MoMAColors::ustwo")# mypal3 <- c("#FF7F00FF", "#577F3FFF", "#D2848DFF", # "#D7433BFF", "#677E8EFF", "#5FA1F7FF")mypal3 <-c("#ff9500", "darkgreen", "grey30", "blue", "red")# mypal3 <- mypal1[c(2, 5, 1, 4, 6)]# Background Colourbg_col <-"white"text_col <-"grey10"text_hil <-"grey25"# Base Text Sizebts <-80plot_title <-"Fertility Rates in South-Asian Nations"plot_subtitle <- glue::glue("Total Fertility Rate (TFR) is the average number of children a woman is expected to have during her lifetime.<br>TFR decline in these South-Asian nations happened at different times. <b style='color:{mypal3[1]}'>India</b>, <b style='color:{mypal3[5]}'>Bangladesh</b> and <b style='color:{mypal3[4]}'>Sri Lanka</b><br>have reached near-replacement levels. <b style='color:{mypal3[2]}'>Pakistan</b> and <b style='color:{mypal3[3]}'>Afghanistan</b> continue to have high fertility rates.")data_annotation <-"About the Data: This data on fertility rates, sourced from the United Nations' World Population Prospects (2022) and processed by Our World in Data, spans from 1950 to 2021. It reflects the average number of live births per woman, with age-specific rates, providing insights into global fertility trends across decades."# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** United Nations & Our World in Data | ","**Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)
Data Wrangling
Code
# A clean tibble for the fertility levels in each yeardf2 <- df1 |>as_tibble() |> janitor::clean_names() |>rename(fertility = fertility_rate_sex_all_age_all_variant_estimates) |>filter(!is.na(code)) |>filter(entity !="World") |>select(-countries_continents) |>filter(!str_detect(code, "OWID"))# A clean tibble of populations for each coutnry in each yearpopdf1 <- popdf |>as_tibble() |> janitor::clean_names() |>filter(!is.na(code)) |>filter(entity !="World") |>mutate(population =ifelse(is.na(population_sex_all_age_all_variant_estimates), population_sex_all_age_all_variant_medium, population_sex_all_age_all_variant_estimates ) ) |>select(-c(population_sex_all_age_all_variant_estimates, population_sex_all_age_all_variant_medium))# Tibble for names of continents and ISO-2 country codes# to be used for flagsdf_continents <- rnaturalearth::ne_countries() |>as_tibble() |> janitor::clean_names() |>select(iso_a3, iso_a2, continent) |>rename(code = iso_a3) |>mutate(country =str_to_lower(iso_a2), .keep ="unused")x_axis_labels <-c("1950s", "1960s", "1970s", "1980s", "1990s", "2000s", "2010s", "2021")# A tibble to use for final computation and country selectiondf3 <- df2 |>left_join(popdf1) |>left_join(df_continents) |>drop_na() |>filter(year >=1951& year <=2020) |>mutate(year =cut( year, breaks =seq(1950, 2020, 10), labels =1:7 ) ) |>group_by(continent, entity, country, year) |>summarise(fertility =weighted.mean(fertility, w = population, na.rm = T),population =mean(population, na.rm = T) ) |>mutate(year =as.numeric(year)) |>ungroup() |>bind_rows( df2 |>left_join(popdf1) |>left_join(df_continents) |>drop_na() |>filter(year ==2021) |>mutate(year =8) ) |>select(-code)# Countries to displaysel_cons <- df3 |>group_by(year) |>slice_max(population, n =10) |>pull(entity) |>unique()# Levels of countries for colour scaleslevels_sel_cons <- df3 |>filter(entity %in% sel_cons) |>filter(year ==1) |>arrange(desc(fertility)) |>pull(entity)# Tibble for final plotting with ggplot2df4 <- df3 |>filter(entity %in% sel_cons) |>group_by(year) |>arrange(desc(fertility)) |>mutate(top_rank =row_number()) |>ungroup() |>mutate(entity =fct(entity, levels = levels_sel_cons))# Adding dummy data to extend bump lines along x-axisdf4 <- df4 |>bind_rows(df4 |>filter(year ==1) |>mutate(year =0.5)) |>bind_rows(df4 |>filter(year ==8) |>mutate(year =8.5))labels_df <-tribble(~entity, ~description,"India", "India's fertility rate has declined gradually since 1960s.","Pakistan", "Pakistan's fertility rate started declining late, and continues to be high to the present day.","Bangladesh", "Bangladesh's rapid drop in 1980s.","Afghanistan", "Afghanistan's wars, poor literacy levels and healthcare have led to persistently high fertility rate.","Sri Lanka", "Sri Lanka witnessed rapid declines starting in 1960, and stabilized by 2000.")df_hjusts <-tibble(country =c("af", "bd", "in", "pk", "lk"),hjust_var =c(0.8, 0.5, 0.3, 0.8, 0.4))df_flags <-tibble(country =c("af", "bd", "in", "pk", "lk"),y_var =c(7.35, 6.35, 5.9, 6.8, 5.4))plotdf <- df2 |>filter(entity %in%c("India", "Pakistan","Afghanistan", "Sri Lanka","Bangladesh" ) ) |>left_join(popdf1) |>group_by(entity) |>mutate(size_var = population /min(population) ) |>left_join(labels_df) |>ungroup() |>mutate(entity =fct( entity, levels =c("India", "Pakistan","Afghanistan", "Sri Lanka","Bangladesh" ) ) ) |>left_join( df4 |>select(entity, country) |>distinct() ) |>mutate(country =case_when( entity =="Afghanistan"~"af", entity =="Sri Lanka"~"lk",.default = country ) ) |># Adding dataframe for horizontal justifications of labelsleft_join(df_hjusts) |># Adding dataframe for flags locationleft_join(df_flags)