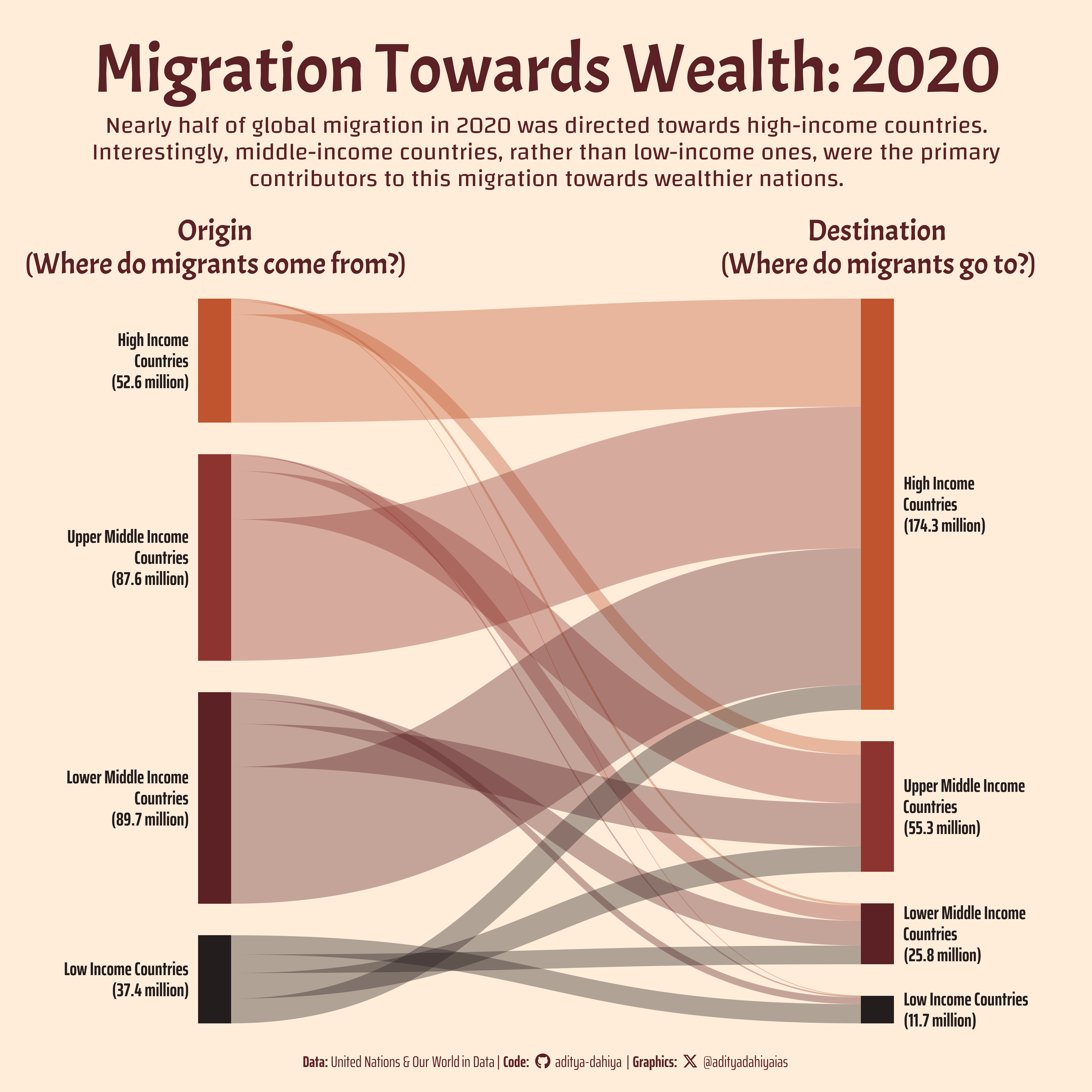
The Sankey diagram visualizes the migration flows in 2020, highlighting the near universal migration to wealthier countries, and almost none in the reverse direction.
Our World in Data
Public Health
{ggsankeyfier}
Author
Aditya Dahiya
Published
July 27, 2024
Migration: Internal and Inter-Continental Flows (2020)
The data for this Sankey diagram, depicting migration flows in 2020, is sourced from the United Nations Department of Economic and Social Affairs (UN DESA) and processed by Our World in Data. It includes comprehensive international migrant statistics, standardized and refined through several processing steps to ensure accuracy and clarity. The graphic highlights key findings, showing the near universal migration to High_income countries, especially from Middle-Income countries. For more details, visit the UN DESA International Migrant Stock page.
This graphic visualizes global migration flows for the year 2020 using data sourced from the United Nations Department of Economic and Social Affairs (UN DESA) and processed by Our World in Data. It highlights migration patterns in countries of different income groups through a Sankey Diagram.
How I made this graphic?
Getting the data
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidylibrary(owidR) # Get data from Our World in R# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text supportlibrary(showtext) # Display fonts in ggplot2library(colorspace) # To lighten and darken colourslibrary(patchwork) # Combining plotslibrary(ggsankeyfier) # Sankey Diagrams with ggplot2# Getting the data# search1 <- owid_search("migrant")# rawdf <- owid("migrant-stock-total")url1 <-"https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/undesa_pd_2020_ims_stock_by_sex_destination_and_origin.xlsx"rawdf2 <- openxlsx::read.xlsx(xlsxFile = url1,sheet ="Table 2",startRow =10,colNames =TRUE)
Visualization Parameters
Code
# Font for titlesfont_add_google("Acme",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Changa",family ="body_font") showtext_auto()# Base Text Sizebts <-80# Colour Palettemypal <- paletteer::paletteer_d("MoMAColors::Alkalay1")text_hil <- mypal[2]text_col <- mypal[1]bg_col <-lighten(mypal[5], 0.8)seecolor::print_color(bg_col)plot_title <-"Migration Towards Wealth: 2020"plot_subtitle <-str_wrap( glue::glue("Nearly half of global migration in 2020 was directed towards high-income countries. Interestingly, middle-income countries, rather than low-income ones, were the primary contributors to this migration towards wealthier nations." ),90 )str_view(plot_subtitle)# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** United Nations & Our World in Data | ","**Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)
Data Wrangling
Code
income_levels <-c("Low Income Countries","Lower Middle Income Countries",# "Middle Income Countries","Upper Middle Income Countries","High Income Countries")income1 <- rawdf2 |># Remove minor duplication of "Australia.And.New.Zealand"select(-12) |> janitor::clean_names() |>as_tibble() |>rename(origin = region_development_group_of_destination) |>mutate(origin =str_squish(origin)) |>select(-c(x1, x3, x4)) |>filter(str_detect(origin, "income")) |>select(-world) |>pivot_longer(cols =-origin,names_to ="destination",values_to ="value" ) |>filter(str_detect(destination, "income")) |>mutate(origin = snakecase::to_title_case(origin),destination = snakecase::to_title_case(destination) ) |>rename(from = destination, to = origin) |>filter( (to !="Middle Income Countries")& (from !="Middle Income Countries") ) |>pivot_longer(cols =c(from, to),names_to ="connector_var",values_to ="node_var" ) |>relocate(node_var, connector_var, value) |>mutate(node_var =fct(node_var, levels = income_levels),x_var =case_when( connector_var =="from"~1, connector_var =="to"~2,.default =NA ) )income2 <- income1 |>group_by(connector_var, node_var, x_var) |>summarise(total =sum(value)) |>mutate(total =paste0(round(total/1e6, 1), " million")) |>ungroup() |>right_join(income1)# geo_regions <- rawdf2 |> # # Remove minor duplication of "Australia.And.New.Zealand"# select(-12) |> # as_tibble() |> # slice(3:10) |> # pull(`Region,.development.group.of.destination`) |> # str_squish()# # geo_regions |> snakecase::to_title_case()# # level_geo_regions <- c(# "Sub Saharan Africa",# "Northern Africa and Western Asia", # "Central and Southern Asia", # "Eastern and South Eastern Asia", # "Oceania Excluding Australia and New Zealand",# "Australia and New Zealand", # "Latin America and the Caribbean", # "Europe and Northern America"# )# # geo1 <- rawdf2 |> # # Remove minor duplication of "Australia.And.New.Zealand"# select(-49) |> # janitor::clean_names() |> # as_tibble() |> # slice(3:10) |> # select(2, 6:13) |> # rename(origin = region_development_group_of_destination) |> # mutate(origin = snakecase::to_title_case(str_squish(origin))) |> # pivot_longer(# cols = -origin,# names_to = "destination",# values_to = "value"# ) |> # mutate(destination = snakecase::to_title_case(destination)) |> # rename(from = destination, to = origin) |> # filter(# (to != "Middle Income Countries")# &# (from != "Middle Income Countries")# ) |> # pivot_longer(# cols = c(from, to),# names_to = "connector_var",# values_to = "node_var"# ) |> # relocate(node_var, connector_var, value) |># mutate(# node_var = fct(node_var, levels = level_geo_regions),# x_var = case_when(# connector_var == "from" ~ 1,# connector_var == "to" ~ 2,# .default = NA# )# )