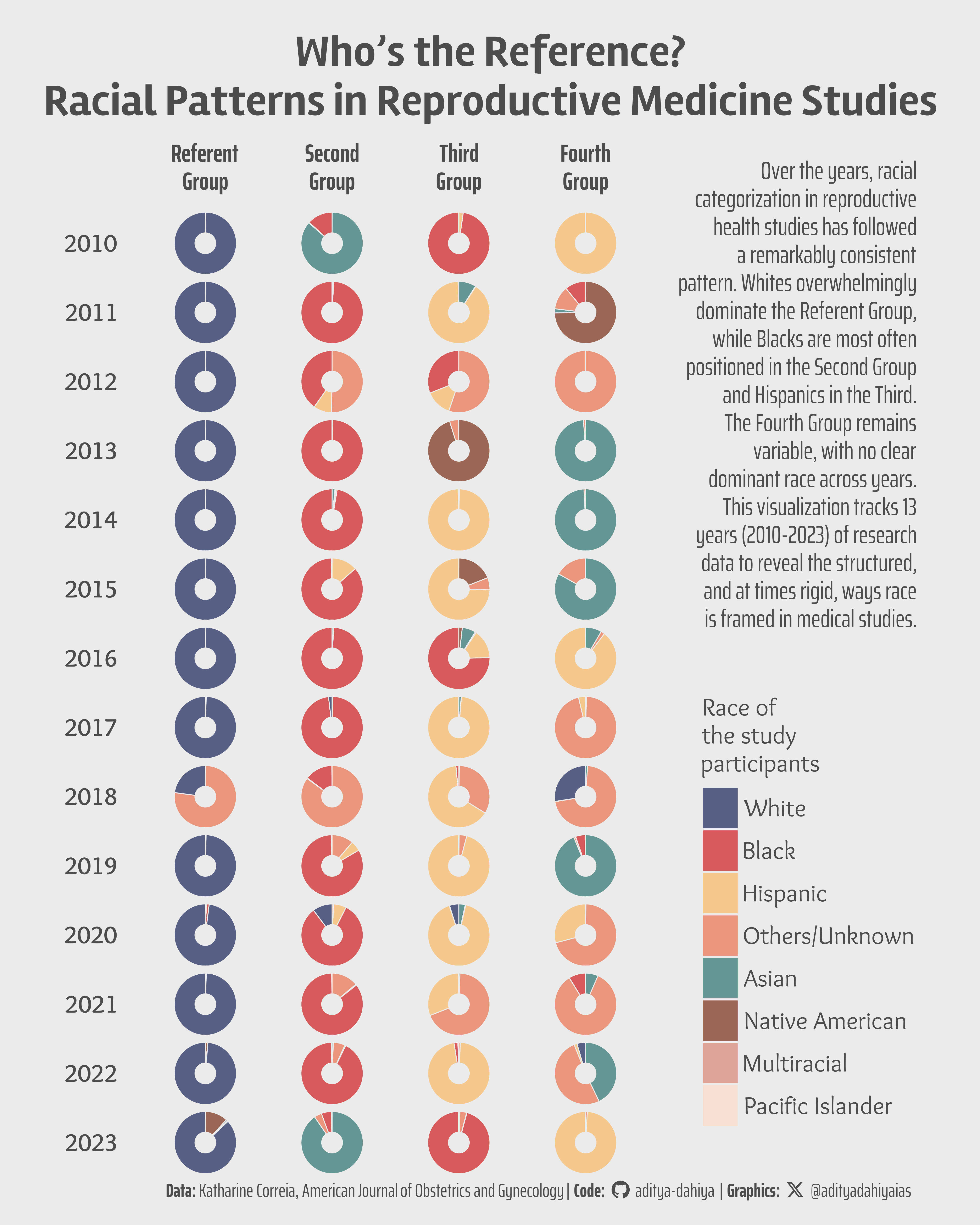
Over the years, racial categorization in reproductive health studies has followed a remarkably consistent pattern. Whites overwhelmingly dominate the Referent Group, while Blacks are most often positioned in the Second Group and Hispanics in the Third. The Fourth Group remains variable, with no clear dominant race across years. This visualization tracks 13 years (2010-2023) of research data to reveal the structured, and at times rigid, ways race is framed in medical studies.
#TidyTuesday
Donut Chart
Author
Aditya Dahiya
Published
March 1, 2025
About the Data
This dataset compiles information from academic literature on racial and ethnic disparities in reproductive medicine, focusing on studies published in the eight highest-impact peer-reviewed Ob/Gyn journals from January 2010 to June 2023. The data were collected for a review article, Racial and ethnic disparities in reproductive medicine in the United States, published in the American Journal of Obstetrics and Gynecology. This dataset provides insights into how racial and ethnic disparities are framed, measured, and discussed in the literature, enabling researchers to explore variations in sample sizes, study types, and health outcomes. A companion interactive website accompanies the dataset, offering dynamic exploration tools.
This dataset has also inspired creative awareness projects, including data art by students.
Figure 1: Each facet in this grid represents a year from 2010 to 2023, with four horizontally arranged groups—Referent Group, Second Group, Third Group, and Fourth Group—reflecting how racial categories are structured in research studies. Within each facet, the donut charts show the racial composition of each group, with different colors representing distinct racial categories. The size of each segment corresponds to the proportion of individuals from that racial category in a given group. This visualization highlights how race has been classified over time in reproductive health research.
How I made this graphic?
Loading required libraries
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colours# Getting dataarticle_dat <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-02-25/article_dat.csv')model_dat <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-02-25/model_dat.csv')
Visualization Parameters
Code
# Font for titlesfont_add_google("Rambla",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Overlock",family ="body_font") showtext_auto()# A base Colourbg_col <-"grey92"seecolor::print_color(bg_col)# Colour for highlighted texttext_hil <-"grey30"seecolor::print_color(text_hil)# Colour for the texttext_col <-"grey30"seecolor::print_color(text_col)# Define Base Text Sizebts <-90# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** Katharine Correia, American Journal of Obstetrics and Gynecology", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)# Add text to plot-------------------------------------------------plot_title <-"Who’s the Reference?\nRacial Patterns in Reproductive Medicine Studies"plot_subtitle <-str_wrap("Over the years, racial categorization in reproductive health studies has followed a remarkably consistent pattern. Whites overwhelmingly dominate the Referent Group, while Blacks are most often positioned in the Second Group and Hispanics in the Third. The Fourth Group remains variable, with no clear dominant race across years. This visualization tracks 13 years (2010-2023) of research data to reveal the structured, and at times rigid, ways race is framed in medical studies.", 30)str_view(plot_subtitle)
# Saving a thumbnaillibrary(magick)# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "tidy_acad_lit_med.png")) |>image_resize(geometry ="x400") |>image_write( here::here("data_vizs", "thumbnails", "tidy_acad_lit_med.png" ) )
Session Info
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourssessioninfo::session_info()$packages |>as_tibble() |>select(package, version = loadedversion, date, source) |>arrange(package) |> janitor::clean_names(case ="title" ) |> gt::gt() |> gt::opt_interactive(use_search =TRUE ) |> gtExtras::gt_theme_espn()
Table 1: R Packages and their versions used in the creation of this page and graphics