Amazon’s Hidden Story: What Word Frequency Reveals About Its Journey
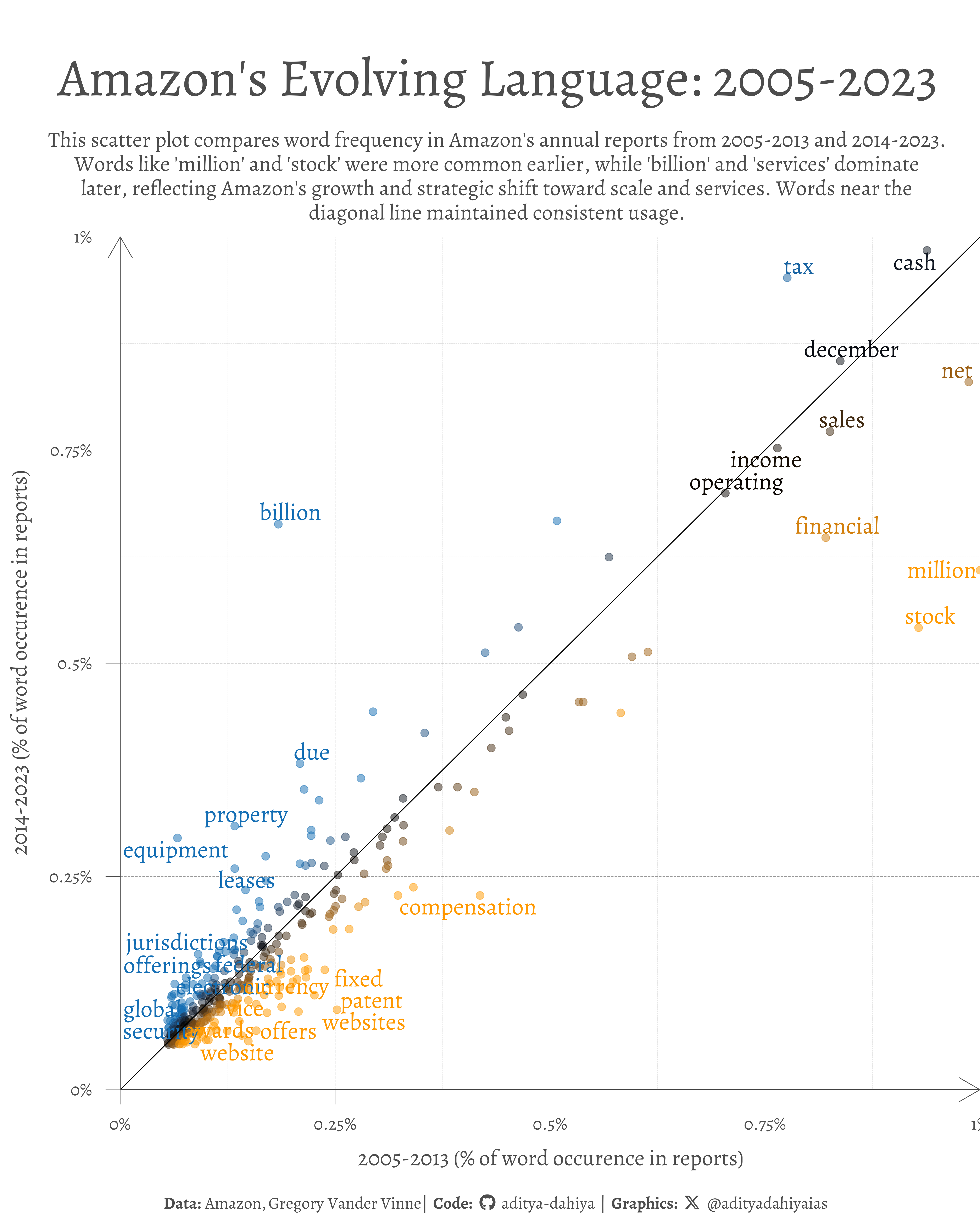
This scatter plot visualizes word frequency in Amazon’s annual reports, comparing two time periods. The x-axis represents the percentage of total words from 2005-2013, while the y-axis shows the same for 2014-2023. Each dot corresponds to a word, and the diagonal line indicates equal usage across both periods.
This dataset invites exploration of trends like word usage over time, sentiment shifts, and word co-occurrences.
This scatter plot illustrates the evolution of language in Amazon’s annual reports, comparing word frequency between 2005-2013 (x-axis) and 2014-2023 (y-axis). Each point represents a word, with a 45-degree line marking equal usage across both periods. In 2005-2013, terms like “million” and “stock” were prevalent, emphasizing financial metrics. By 2014-2023, “billion” and “services” rose, reflecting growth in scale and services. Deviations from the line reveal shifts in Amazon’s strategic focus.
Figure 1: The graphic displays a scatter plot of word usage in Amazon’s annual reports. The x-axis plots the frequency of words from 2005-2013, and the y-axis plots the frequency from 2014-2023. A 45-degree diagonal line marks where words have consistent frequency between the two eras.
How I made this graphic?
Loading required libraries
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(tidytext) # Text Analysis for Rlibrary(ggrepel) # Text Labels non-overlappinglibrary(paletteer) # colour Palettesreport_words_clean <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-03-25/report_words_clean.csv')
Visualization Parameters
Code
# Font for titlesfont_add_google("Alegreya",family ="title_font") # Font for the captionfont_add_google("Stint Ultra Condensed",family ="caption_font") # Font for plot textfont_add_google("Alegreya",family ="Josefin Slab") showtext_auto()mypal <-c("#ff9900", "#146eb4", "#000000")# cols4all::c4a_gui()# A base Colourbg_col <-"white"seecolor::print_color(bg_col)# Colour for highlighted texttext_hil <-"grey30"seecolor::print_color(text_hil)# Colour for the texttext_col <-"grey30"seecolor::print_color(text_col)line_col <-"grey30"# Define Base Text Sizebts <-120# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** Amazon, Gregory Vander Vinne", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)# Add text to plot-------------------------------------------------plot_title <-"Amazon's Evolving Language: 2005-2023"plot_subtitle <-"This scatter plot compares word frequency in Amazon's annual reports from 2005-2013 and 2014-2023. Words like 'million' and 'stock' were more common earlier, while 'billion' and 'services' dominate later, reflecting Amazon's growth and strategic shift toward scale and services. Words near the diagonal line maintained consistent usage."
Exploratory Data Analysis and Wrangling
Code
report_words_clean |>anti_join(stop_words)# Number of words per yearreport_words_clean |>count(year) |>ggplot(aes(year, n)) +geom_point() +geom_line()df1 <- report_words_clean |>count(year) |>mutate(grp_var =case_when( year %in%2005:2013~"2005-13", year %in%2014:2023~"2014-23" ) ) |>count(grp_var, wt = n, name ="total")df2 <- report_words_clean |># create a grouping variablemutate(grp_var =case_when( year %in%2005:2013~"2005-13", year %in%2014:2023~"2014-23" ) ) |># Count wordsgroup_by(grp_var) |>count(word) |># keep most frequent wordsslice_max(order_by = n, n =400) |>ungroup() |>left_join(df1) |>mutate(perc =100* n / total ) |>select(-n, -total) |>pivot_wider(id_cols = word,names_from = grp_var,values_from = perc ) |>drop_na() |>mutate(ratio =`2014-23`/`2005-13` ) |>arrange(desc(ratio))break_labels <-seq(0, 1.25, 0.25)
# Saving a thumbnaillibrary(magick)# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "tidy_amazon_text.png")) |>image_resize(geometry ="x400") |>image_write( here::here("data_vizs", "thumbnails", "tidy_amazon_text.png" ) )
Session Info
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(tidytext) # Text Analysis for Rlibrary(ggrepel) # Text Labels non-overlappinglibrary(paletteer) # colour Palettessessioninfo::session_info()$packages |>as_tibble() |>select(package, version = loadedversion, date, source) |>arrange(package) |> janitor::clean_names(case ="title" ) |> gt::gt() |> gt::opt_interactive(use_search =TRUE ) |> gtExtras::gt_theme_espn()
Table 1: R Packages and their versions used in the creation of this page and graphics