Visualizing common themes in Data: Using {ggplot2} and {packcircles} to Uncover Patterns
#TidyTuesday
{packcircles}
Author
Aditya Dahiya
Published
February 15, 2025
About the Data
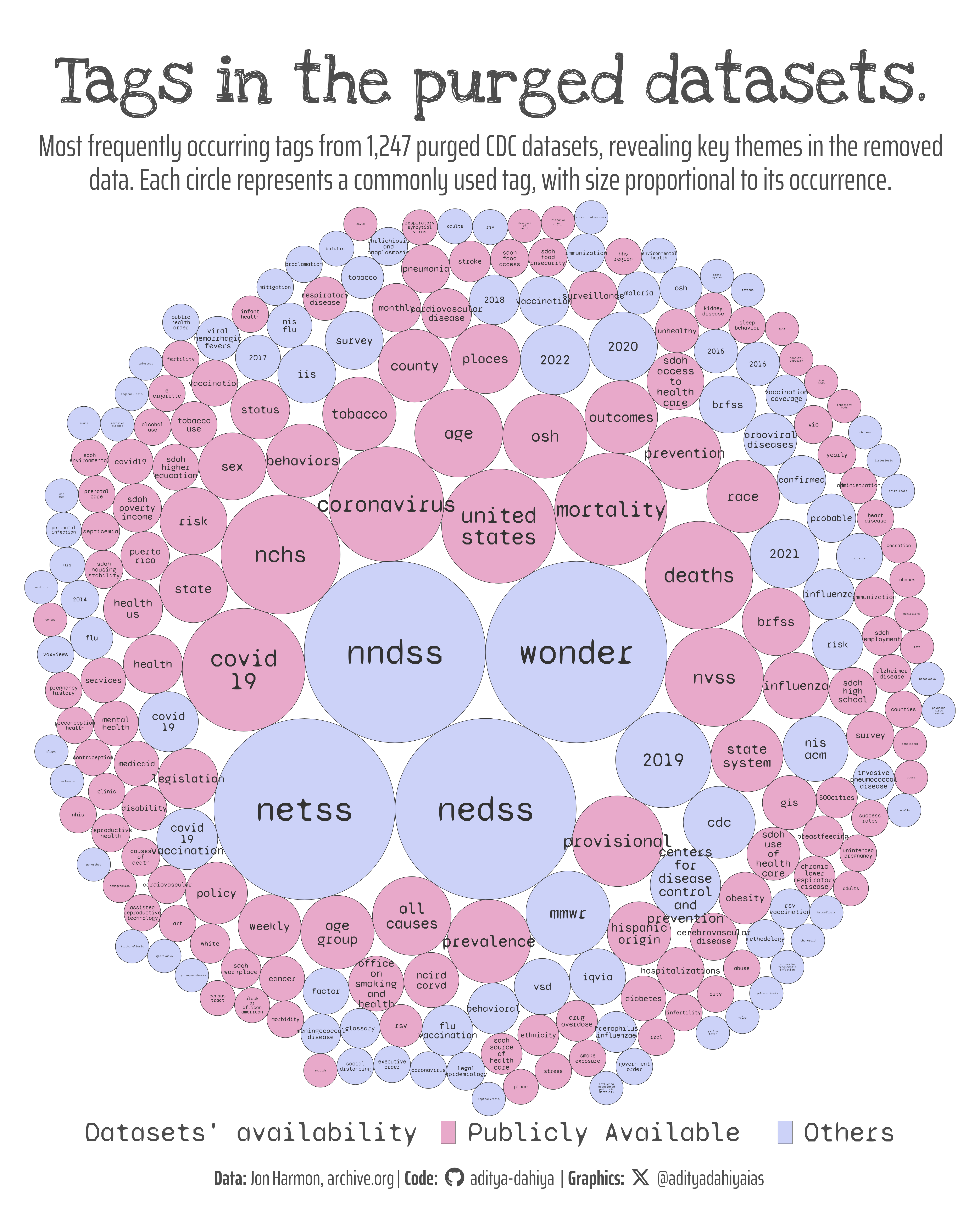
The CDC Datasets for this week’s TidyTuesday focus on publicly available health data. Efforts have been made to archive these datasets on archive.org to preserve critical health data. The dataset contains metadata on these archived resources, including bureau and program codes sourced from the OMB Circular A-11 and the Federal Program Inventory. Key variables include dataset URLs, contact information, program categories, access levels, and update frequency. The data can be accessed via the tidytuesdayR package or directly from GitHub.
Figure 1: A packcircles visualization of the most frequent tags from 1,247 purged CDC datasets, sized by occurrence and colored by public access status. Created using R with {ggplot2} for plotting and {packcircles} for circle packing.
How I made this graphic?
Loading required libraries
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(packcircles) # Pack-Circle Algorithm# Option 2: Read directly from GitHubcdc_datasets <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-02-11/cdc_datasets.csv')fpi_codes <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-02-11/fpi_codes.csv')omb_codes <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-02-11/omb_codes.csv')
Visualization Parameters
Code
# Font for titlesfont_add_google("Love Ya Like A Sister",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Syne Mono",family ="body_font") font_add_google("Syne Mono",family ="circle_font")showtext_auto()# A base Colourbg_col <-"white"seecolor::print_color(bg_col)# Colour for highlighted texttext_hil <-"grey30"seecolor::print_color(text_hil)# Colour for the texttext_col <-"grey20"seecolor::print_color(text_col)# Define Base Text Sizebts <-90# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** Jon Harmon, archive.org", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)# Add text to plot-------------------------------------------------plot_title <-"Patterns in Purged Data: Most Common Tags"plot_subtitle <-"Most frequently occurring tags from 1,247 purged CDC datasets, revealing key themes in the removed data. Each circle represents a commonly used tag, with size proportional to its occurrence."
library(packcircles)# Create the layout using circleProgressiveLayout()# This function returns a dataframe with a row for each bubble.# It includes the center coordinates (x and y) and the radius, which is proportional to the value.packing1 <-circleProgressiveLayout( df1$n,sizetype ="area")# A tibble of centres of the circles and our cleaned dataplotdf <-bind_cols( df1, packing1) |>mutate(id =row_number())# A tibble of the points on the circumference of the circlesplotdf_circles <-circleLayoutVertices( packing1,npoints =100 ) |>as_tibble() |>mutate(id =as.numeric(id)) |># Adding the other variablesleft_join( plotdf |>select(-x, -y), by =join_by(id == id) )# Check if everything worked.# visdat::vis_miss(plotdf_circles)
# Saving a thumbnaillibrary(magick)# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "tidy_cdc_datasets.png")) |>image_resize(geometry ="x400") |>image_write( here::here("data_vizs", "thumbnails", "tidy_cdc_datasets.png" ) )
Session Info
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(packcircles) # Pack-Circle Algorithmsessioninfo::session_info()$packages |>as_tibble() |>select(package, version = loadedversion, date, source) |>arrange(package) |> janitor::clean_names(case ="title" ) |> gt::gt() |> gt::opt_interactive(use_search =TRUE ) |> gtExtras::gt_theme_espn()
Table 1: R Packages and their versions used in the creation of this page and graphics