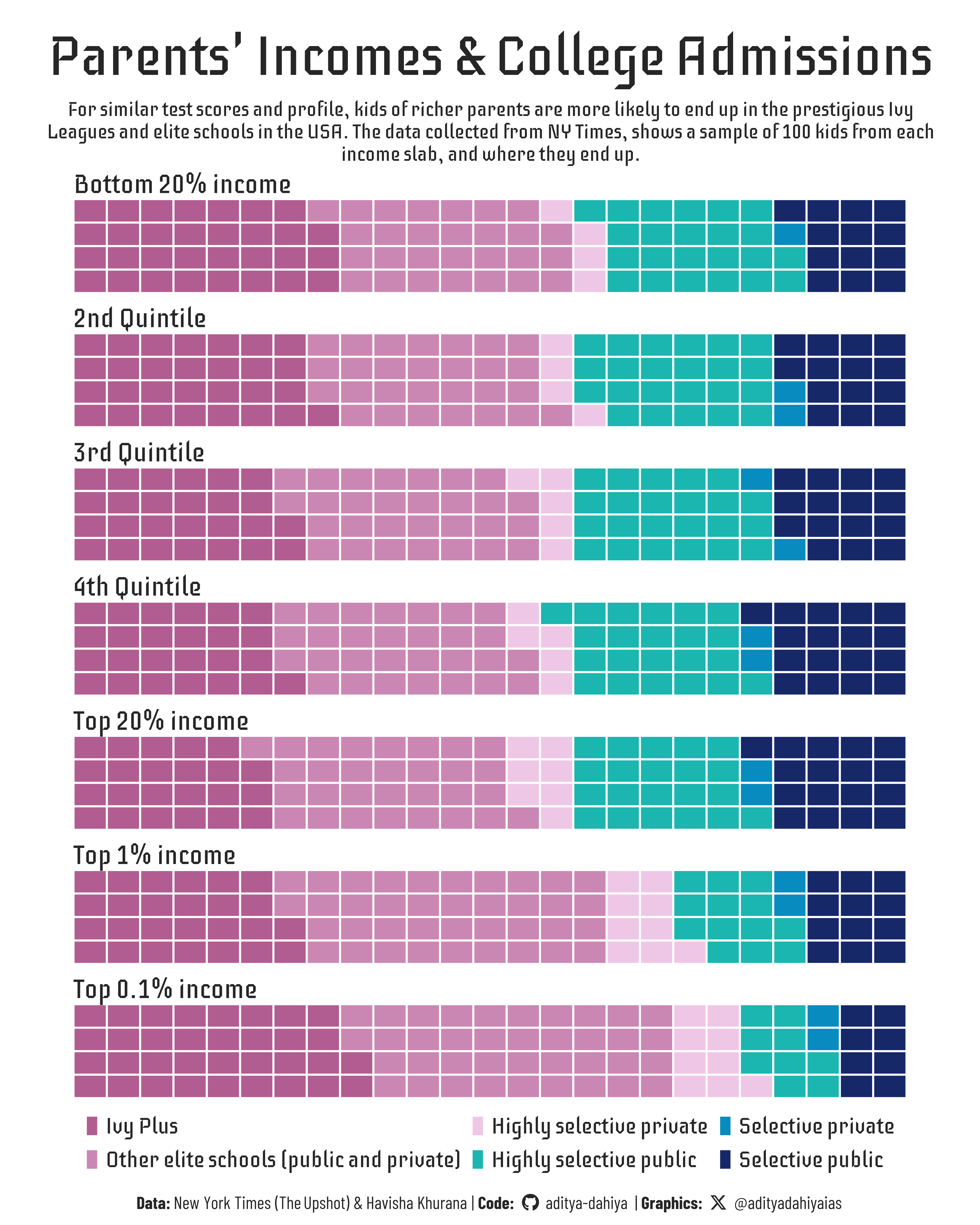
US Data exploring economic diversity and student outcomes.
#TidyTuesday
{waffle}
Author
Aditya Dahiya
Published
September 10, 2024
Figure 1: A waffle chart on what percentage of students by each income group (by parents’ income) get selected in different Colleges of U.S.A., for otherwise similar scores and profiles.
How I made this graphic?
Loading libraries & data
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(seecolor) # To print and view colourslibrary(patchwork) # Combining plotslibrary(waffle) # Waffle Charts in Rcollege_admissions <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-09-10/college_admissions.csv')
# Font for titlesfont_add_google("Sofia",family ="title_font") # Font for the captionfont_add_google("Barlow Condensed",family ="caption_font") # Font for plot textfont_add_google("Iceberg",family ="body_font") showtext_auto()bg_col <-"white"mypal <- paletteer::paletteer_d("beyonce::X39")mypal1 <- paletteer::paletteer_d("LaCroixColoR::Lemon")text_col <-"grey15"text_hil <-"grey15"bts <-80# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_title <-"Parents' Incomes & College Admissions"plot_subtitle <-str_wrap("For similar test scores and profile, kids of richer parents are more likely to end up in the prestigious Ivy Leagues and elite schools in the USA. The data collected from NY Times, shows a sample of 100 kids from each income slab, and where they end up.", 110)# plot_subtitle <- glue::glue("................")plot_subtitle |>str_view()plot_caption <-paste0("**Data:** New York Times (The Upshot) & Havisha Khurana", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)