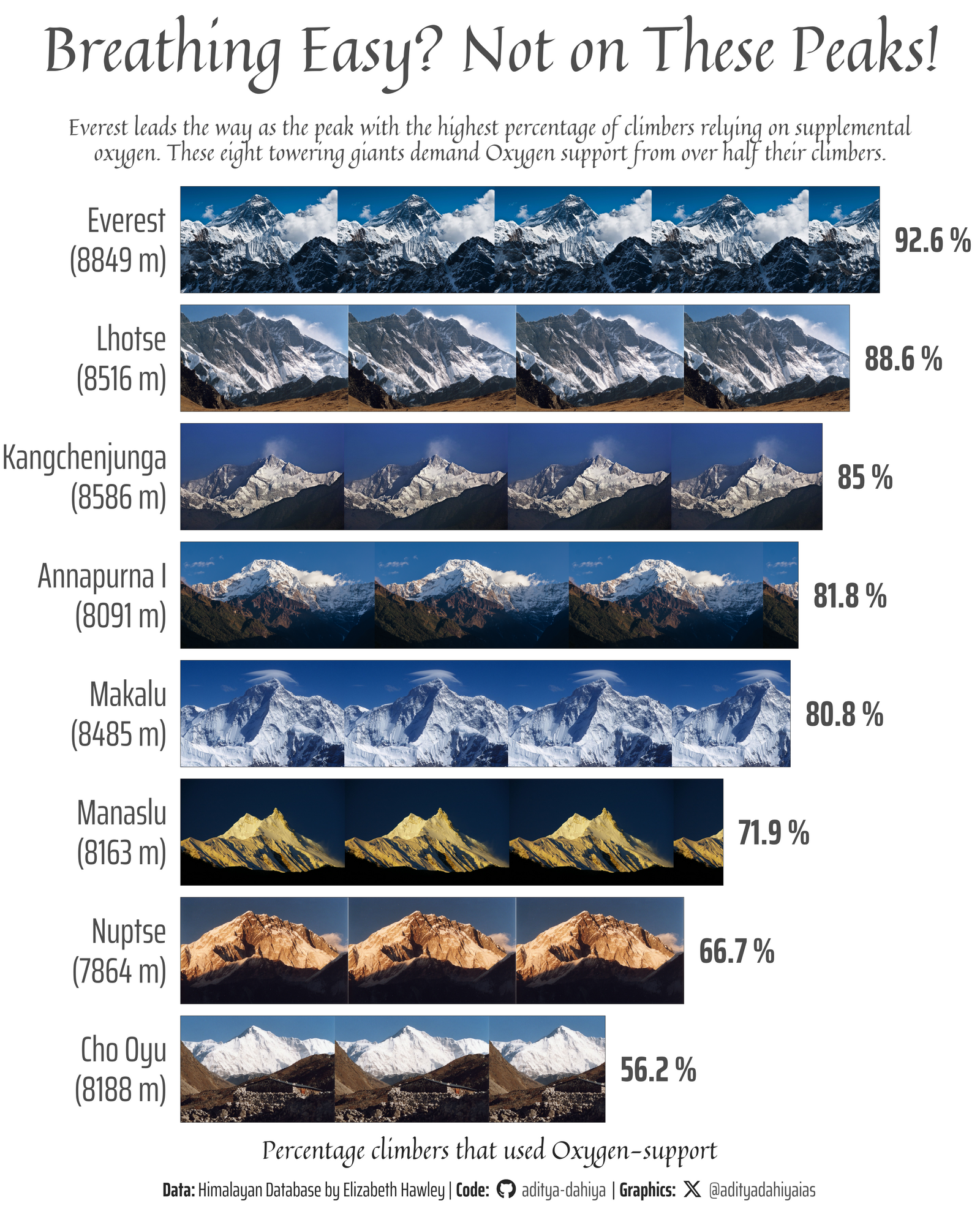
The Essential Role of Oxygen in Conquering Himalayan Giants: A closer look at the peaks where over half of climbers relied on supplemental oxygen to reach the summit.
#TidyTuesday
{ggpattern}
{magick}
Images
Author
Aditya Dahiya
Published
January 25, 2025
About the Data
The Himalayan Dataset is a rich repository documenting mountaineering expeditions in the Nepal Himalaya, sourced from the Himalayan Database. This database originates from the pioneering work of Elizabeth Hawley, a journalist who meticulously chronicled climbing history through records gathered from books, journals, and direct correspondence with climbers. Initially released as a CD-ROM booklet in 2004 by the American Alpine Club, it became an essential tool for the mountaineering community. The project was further institutionalized in 2017 by The Himalayan Database, a non-profit organization that launched Version 2, making the dataset freely available for download here.
This dataset provides comprehensive insights into Himalayan peaks, expeditions, and climbers, detailing variables such as geographic data, success rates, climbing routes, and the use of supplemental oxygen. This curated dataset is made available by Nicolas Foss, Ed.D., MS.
Figure 1: This horizontal bar chart displays the percentage of climbers who used supplemental oxygen while climbing eight Himalayan peaks where oxygen usage exceeded 50%. The x-axis represents the percentage of climbers using oxygen, while each bar corresponds to a specific peak, arranged from highest to lowest percentage. Mountain images within the bars visually represent each peak.
How I made this graphic?
Loading required libraries, data import & creating custom functions.
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(ggpattern) # Image patterns in ggplot2 geomslibrary(magick) # Handling imageslibrary(httr) # Downloading images from Googleexped_tidy <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-01-21/exped_tidy.csv') |> janitor::clean_names()peaks_tidy <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-01-21/peaks_tidy.csv') |> janitor::clean_names()
Visualization Parameters
Code
# Font for titlesfont_add_google("Eagle Lake",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Quintessential",family ="body_font") showtext_auto()# A base Colourbg_col <-"white"seecolor::print_color(bg_col)# Colour for highlighted texttext_hil <-"grey30"seecolor::print_color(text_hil)# Colour for the texttext_col <-"grey15"seecolor::print_color(text_col)# Define Base Text Sizebts <-90# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** Himalayan Database by Elizabeth Hawley", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)# Add text to plot-------------------------------------------------plot_title <-"Breathing Easy? Not on These Peaks!"plot_subtitle <-"Everest leads the way as the peak with the highest percentage of climbers relying on supplemental oxygen. These eight towering giants demand Oxygen support from over half their climbers."
# Get a custom google search engine and API key# Tutorial: https://developers.google.com/custom-search/v1/overview# Tutorial 2: https://programmablesearchengine.google.com/# From:https://developers.google.com/custom-search/v1/overview# google_api_key <- "LOAD YOUR GOOGLE API KEY HERE"# From: https://programmablesearchengine.google.com/controlpanel/all# my_cx <- "GET YOUR CUSTOM SEARCH ENGINE ID HERE"plotdf# Load necessary packageslibrary(httr)library(magick)# Define function to download and save movie posterdownload_icons <-function(i) { api_key <- google_api_key cx <- my_cx# Build the API request URL url <-paste0("https://www.googleapis.com/customsearch/v1?q=", URLencode(paste0(plotdf$pkname[i], " mountain photo HD")), "&cx=", cx, "&searchType=image&key=", api_key)# Make the request response <-GET(url) result <-content(response, "parsed")# Get the URL of the first image result image_url <- result$items[[1]]$link im <- magick::image_read(image_url) |>image_resize("x3000")# set background as whiteimage_write(image = im,path = here::here("data_vizs",paste0("temp_himalayas_", i,".png")),format ="png" )}for (i in1:8) {download_icons(i)}
Reduce filesize and Savings the thumbnail for the webpage
Code
# Saving a thumbnaillibrary(magick)# Reducing Image Size - its 15 Mb plusimage_read(here::here("data_vizs", "tidy_himalayan_mountains.png")) |>image_resize(geometry ="x2000") |>image_write( here::here("data_vizs", "tidy_himalayan_mountains.png" ) )# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "tidy_himalayan_mountains.png")) |>image_resize(geometry ="x400") |>image_write( here::here("data_vizs", "thumbnails", "tidy_himalayan_mountains.png" ) )# Clean Up: Do no harm and leave the world an untouched place!# Remove temporary image filesunlink(paste0("data_vizs/temp_himalayas_", 1:8, ".png"))
Session Info
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(ggpattern) # Image patterns in ggplot2 geomslibrary(magick) # Handling imageslibrary(httr) # Downloading images from Googlesessioninfo::session_info()$packages |>as_tibble() |>select(package, version = loadedversion, date, source) |>arrange(package) |> janitor::clean_names(case ="title" ) |> gt::gt() |> gt::opt_interactive(use_search =TRUE ) |> gtExtras::gt_theme_espn()
Table 1: R Packages and their versions used in the creation of this page and graphics