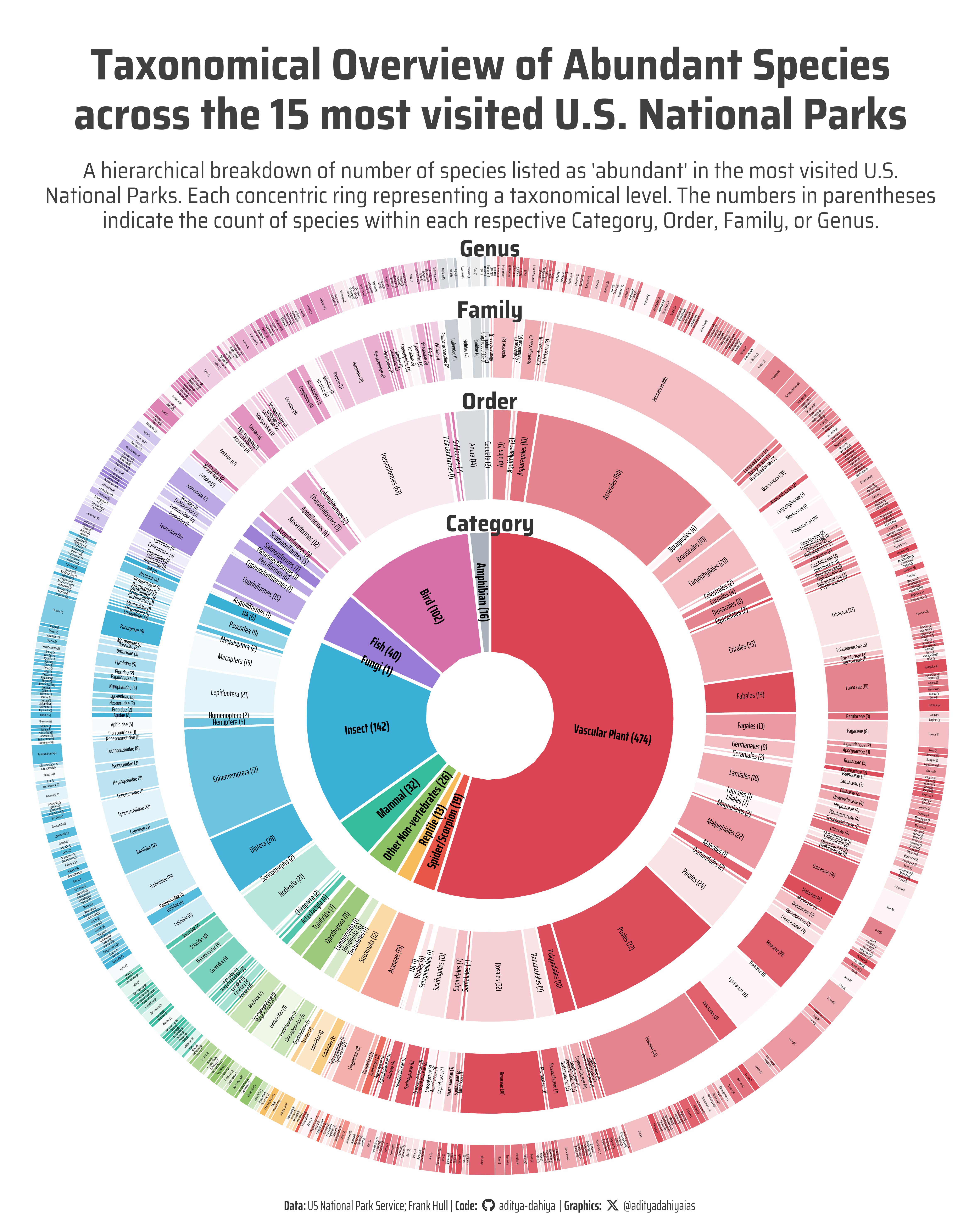
A hierarchical breakdown of number of species listed as ‘abundant’ in the most visited U.S. National Parks. Each concentric ring representing a taxonomical level. The numbers in parentheses indicate the count of species within each respective Category, Order, Family, or Genus.
#TidyTuesday
Donut Chart
Hierarchical Data
Author
Aditya Dahiya
Published
October 8, 2024
This week, we’re diving into species data from the most visited National Parks in the USA, focusing on the top 15 parks. The dataset comes from NPSpecies, a biodiversity database managed by the National Park Service (NPS), which lists species found in National Parks. Each species listed in NPSpecies ideally has credible evidence, such as observations or reports, to confirm its presence. For more technical details on the dataset, including column definitions and field tags, refer to the NPSpecies User Guide. The full dataset, curated by Frank Hull, is also available on GitHub for further exploration.
Figure 1: This hierarchical donut chart visualizes the taxonomical structure of species classified as ‘abundant’ in the 15 most visited U.S. National Parks. The innermost ring represents the broader taxonomical Category, followed by rings for Order, Family, and Genus as we move outward. Each label includes the number of species in parentheses, illustrating how many species belong to that specific Category, Order, Family, or Genus. The chart highlights the diversity and taxonomical distribution of abundant species in these protected natural areas.
How I made this graphic?
Loading libraries & data
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(patchwork) # Combining plots# Option 2: Read data directly from GitHubnps_species_data <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-10-08/most_visited_nps_species_data.csv') |> janitor::clean_names()
# Font for titlesfont_add_google("Saira Semi Condensed",family ="title_font") # Font for the captionfont_add_google("Saira Extra Condensed",family ="caption_font") # Font for plot textfont_add_google("Saira Extra Condensed",family ="body_font") showtext_auto()bg_col ="white"text_col <-"grey20"text_hil <-"grey20"mypal <- paletteer::paletteer_d("ggsci::flattastic_flatui",direction =-1)mypal <- mypal[c(2, 4:12)]mypalbts <-20# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_title <-"Taxonomical Overview of Abundant Species\nacross the 15 most visited U.S. National Parks"plot_subtitle <-str_wrap("A hierarchical breakdown of number of species listed as 'abundant' in the most visited U.S. National Parks. Each concentric ring representing a taxonomical level. The numbers in parentheses indicate the count of species within each respective Category, Order, Family, or Genus.", 98)str_view(plot_subtitle)plot_caption <-paste0("**Data:** US National Park Service; Frank Hull", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)