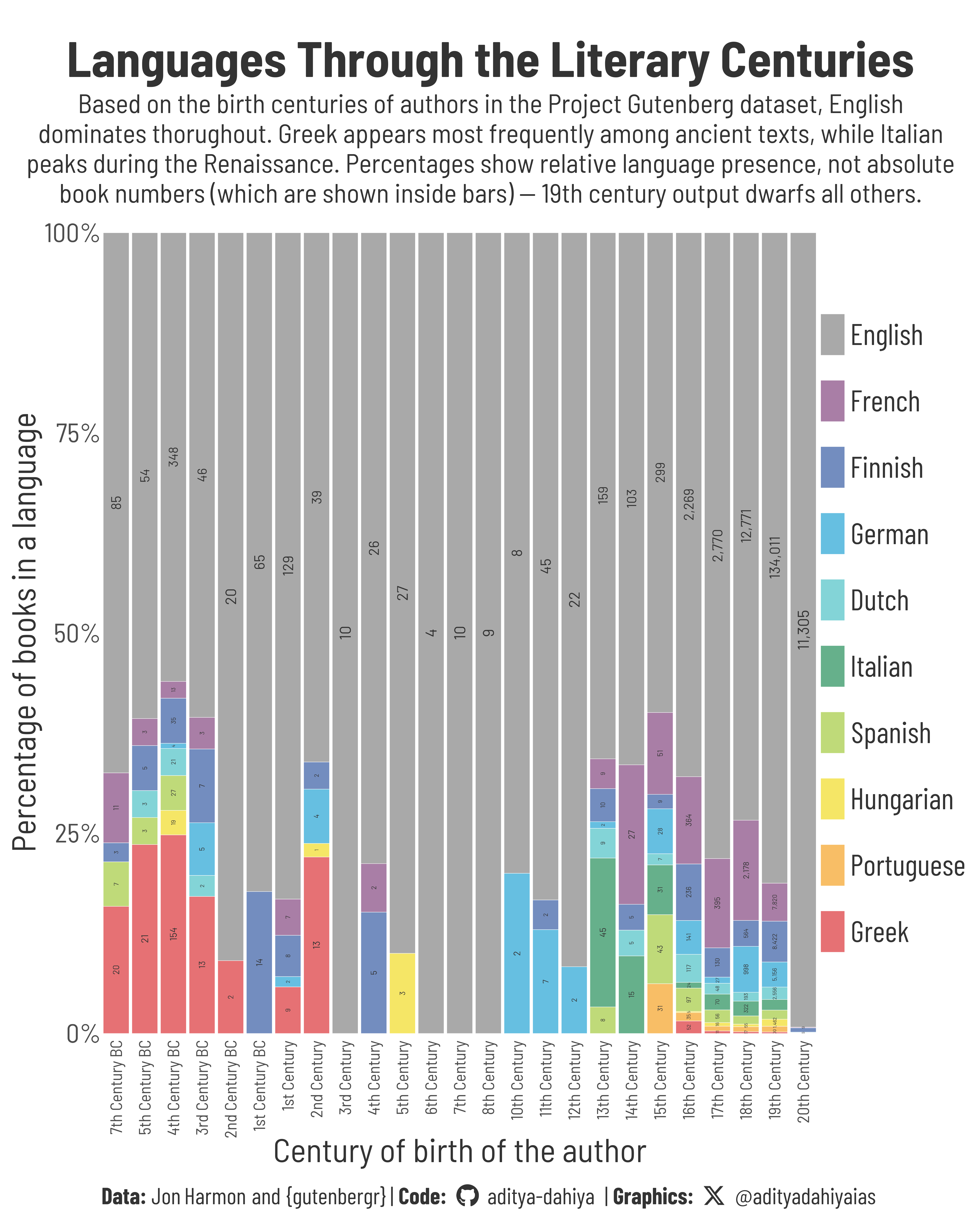
Figure 1: Books from Project Gutenberg are grouped by the authors’ birth centuries, with stacked bars showing the proportion of books in each of the ten most frequent languages. Percentages are within-century distributions. The absolute number of books is shown as text inside the bars.
How the Graphic Was Created
To explore historical language patterns in public domain books, I used data from Project Gutenberg via the {gutenbergr} R package, curated for the TidyTuesday project (2025-06-03) by Jon Harmon. The analysis focused on authors’ birth centuries and the languages in which their works appear in the Project Gutenberg collection.
Key Findings
English has consistently dominated the corpus, especially from the 18th century onward.
Greek emerges prominently among authors born between the 7th century BC and 2nd century AD, reflecting the enduring legacy of classical texts.
Italian saw a notable rise in the 13th and 14th centuries, likely due to the cultural flowering during the Italian Renaissance.
The graphic displays relative proportions of languages by century (not absolute counts). The actual number of books by authors born in the 19th century far exceeds those from all earlier periods combined.
Tools & Techniques
This visual was created in R using the ggplot2 ecosystem. The full pipeline included:
Font Awesome icons were embedded in the caption using the fontawesome R package
The final plot was saved using ggsave(), with careful control over typography, spacing, and layout.
Authors’ birth years were used to compute the century of birth, which was then plotted along the x-axis. Each bar represents the percentage distribution of books in different languages per century. For clarity, language codes (like en, el, it) were translated into full language names.
The visualization offers a compelling lens into the temporal geography of literature—revealing how languages like Greek and Italian peaked during classical and early Renaissance eras, while English has seen sustained growth over the centuries.
View the graphic on GitHub or follow updates on X/Twitter. Data: {gutenbergr} • Code and Visualization: Aditya Dahiya
Loading required libraries
Code
pacman::p_load( tidyverse, # All things tidy scales, # Nice Scales for ggplot2 fontawesome, # Icons display in ggplot2 ggtext, # Markdown text support for ggplot2 showtext, # Display fonts in ggplot2 colorspace, # Lighten and Darken colours patchwork # Composing Plots)gutenberg_authors <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-06-03/gutenberg_authors.csv')gutenberg_languages <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-06-03/gutenberg_languages.csv')gutenberg_metadata <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-06-03/gutenberg_metadata.csv')gutenberg_subjects <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-06-03/gutenberg_subjects.csv')
Visualization Parameters
Code
# Font for titlesfont_add_google("Barlow",family ="title_font") # Font for the captionfont_add_google("Barlow Condensed",family ="caption_font") # Font for plot textfont_add_google("Barlow Semi Condensed",family ="body_font") showtext_auto()# A base Colourbg_col <-"white"seecolor::print_color(bg_col)# Colour for highlighted texttext_hil <-"grey20"seecolor::print_color(text_hil)# Colour for the texttext_col <-"grey20"seecolor::print_color(text_col)line_col <-"grey30"# Define Base Text Sizebts <-120# Caption stuff for the plotsysfonts::font_add(family ="Font Awesome 6 Brands",regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf"))github <-""github_username <-"aditya-dahiya"xtwitter <-""xtwitter_username <-"@adityadahiyaias"social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")plot_caption <-paste0("**Data:** Jon Harmon and {gutenbergr}", " | **Code:** ", social_caption_1, " | **Graphics:** ", social_caption_2 )rm(github, github_username, xtwitter, xtwitter_username, social_caption_1, social_caption_2)# Add text to plot-------------------------------------------------plot_subtitle <-str_wrap("Based on the birth centuries of authors in the Project Gutenberg dataset, English dominates thorughout. Greek appears most frequently among ancient texts, while Italian peaks during the Renaissance. Percentages show relative language presence, not absolute book numbers (which are shown inside bars) — 19th century output dwarfs all others.", 90)str_view(plot_subtitle)plot_title <-"Languages Through the Literary Centuries"
Exploratory Data Analysis and Wrangling
Code
pacman::p_load(summarytools)dfSummary(gutenberg_authors) |>view()dfSummary(gutenberg_languages) |>view()gutenberg_metadata |>dfSummary() |>view()gutenberg_subjects |>dfSummary() |>view()df1 <- gutenberg_metadata |>select(gutenberg_id, language) |>left_join( gutenberg_subjects |>select(gutenberg_id, subject),relationship ="many-to-many" ) |>drop_na()df1 |>count(language, subject, sort = T)df2 <- gutenberg_metadata |>select(gutenberg_id, gutenberg_author_id, language) |>left_join( gutenberg_subjects |>select(gutenberg_id, subject),relationship ="many-to-many" ) |>left_join( gutenberg_authors |>select(gutenberg_author_id, author, birthdate, deathdate) ) |>filter(!is.na(birthdate) &!is.na(deathdate)) |>mutate(century = (birthdate%/%100) +1 ) |>separate_longer_delim(language, "/") |>mutate(language =fct(language),language =fct_lump_n(language, n =10) ) |># Code assist by Claude Sonnet 4mutate(# Convert language codes to full nameslanguage =case_when( language =="en"~"English", language =="de"~"German", language =="fr"~"French", language =="it"~"Italian", language =="es"~"Spanish", language =="pt"~"Portuguese", language =="nl"~"Dutch", language =="fi"~"Finnish", language =="el"~"Greek", language =="hu"~"Hungarian",TRUE~"Others"# Default case for any other values ),# Convert century numbers to formatted stringscentury =case_when( century <0~paste0(abs(century), case_when(abs(century) %%10==1&abs(century) %%100!=11~"st",abs(century) %%10==2&abs(century) %%100!=12~"nd",abs(century) %%10==3&abs(century) %%100!=13~"rd",TRUE~"th" ), " Century BC"), century >0~paste0(century, case_when( century %%10==1& century %%100!=11~"st", century %%10==2& century %%100!=12~"nd", century %%10==3& century %%100!=13~"rd",TRUE~"th" ), " Century"),TRUE~"Unknown" ) ) |># Create ordered factor for century from oldest to newestmutate(century =factor( century, levels =c(paste0(7:1, c("th", "th", "th", "th", "rd", "nd", "st"), " Century BC"),paste0(1:20, c("st", "nd", "rd", rep("th", 17)), " Century" ) ),ordered =TRUE) ) |>filter(language !="Others")language_levels <- df2 |>count(language, sort = T) |>pull(language)plotdf <- df2 |>filter(!is.na(century)) |>count(century, language) |>group_by(century) |>mutate(perc = n /sum(n),language =fct(language, levels = language_levels) )
# Saving a thumbnaillibrary(magick)# Saving a thumbnail for the webpageimage_read(here::here("data_vizs", "tidy_project_gutenberg.png")) |>image_resize(geometry ="x400") |>image_write( here::here("data_vizs", "thumbnails", "tidy_project_gutenberg.png" ) )
Session Info
Code
pacman::p_load( tidyverse, # All things tidy scales, # Nice Scales for ggplot2 fontawesome, # Icons display in ggplot2 ggtext, # Markdown text support for ggplot2 showtext, # Display fonts in ggplot2 colorspace, # Lighten and Darken colours patchwork # Composing Plots)sessioninfo::session_info()$packages |>as_tibble() |> dplyr::select(package, version = loadedversion, date, source) |> dplyr::arrange(package) |> janitor::clean_names(case ="title" ) |> gt::gt() |> gt::opt_interactive(use_search =TRUE ) |> gtExtras::gt_theme_espn()
Table 1: R Packages and their versions used in the creation of this page and graphics