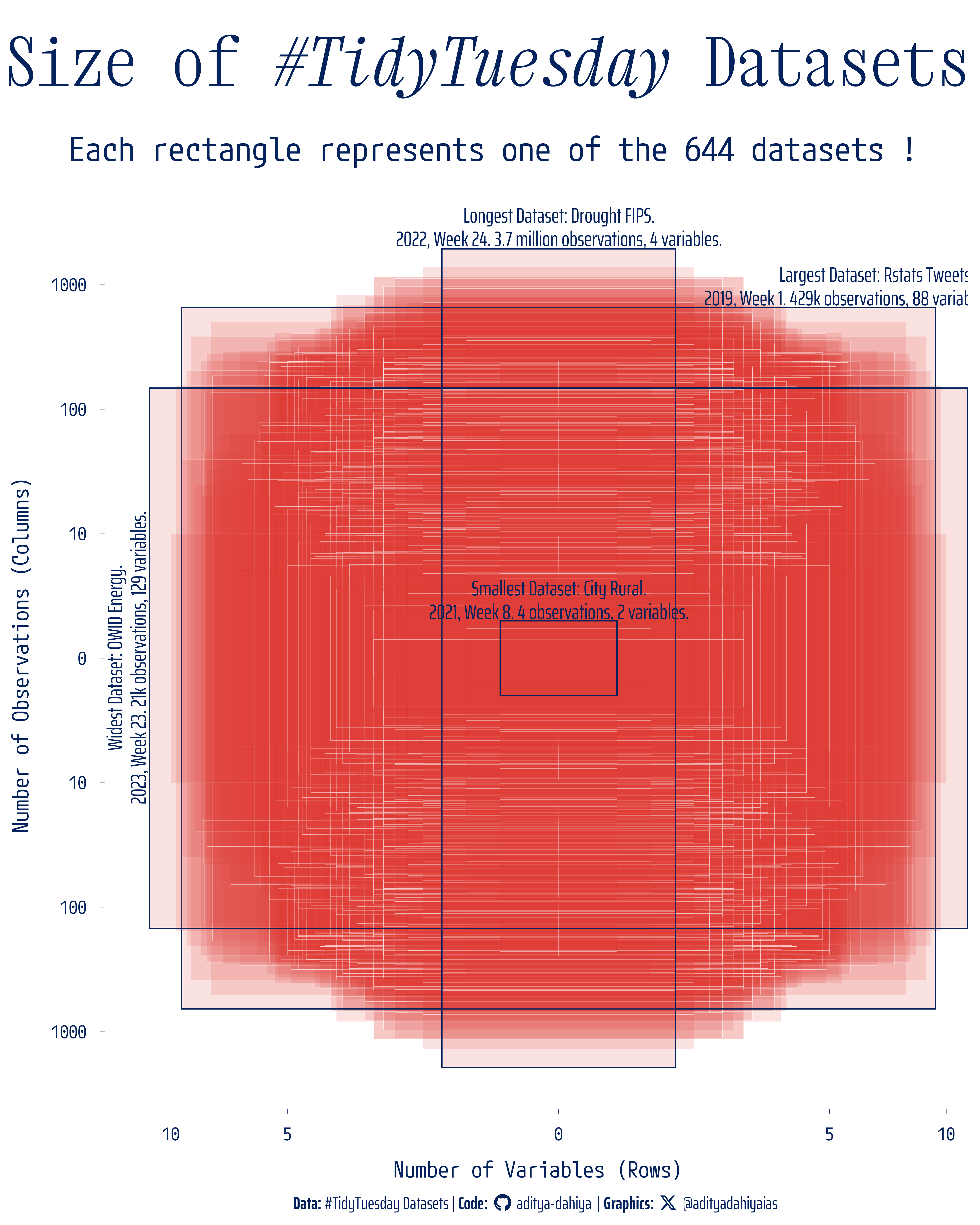
The figure shows 644 overlapping red rectangles - each represents a dataset. The axes are on log scales. Each rectangle shows size of a #TidyTuesday dataset. The largest, smallest, widest and longest datasets are labelled.
How I made this graphic?
Loading required libraries, data import & creating custom functions
Code
# Data Import and Wrangling Toolslibrary(tidyverse) # All things tidy# Final plot toolslibrary(scales) # Nice Scales for ggplot2library(fontawesome) # Icons display in ggplot2library(ggtext) # Markdown text support for ggplot2library(showtext) # Display fonts in ggplot2library(colorspace) # Lighten and Darken colourslibrary(patchwork) # Combining plots# Load datatt_datasets <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-07-02/tt_datasets.csv')# tt_summary <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-07-02/tt_summary.csv')# tt_urls <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-07-02/tt_urls.csv')# tt_variables <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2024/2024-07-02/tt_variables.csv')