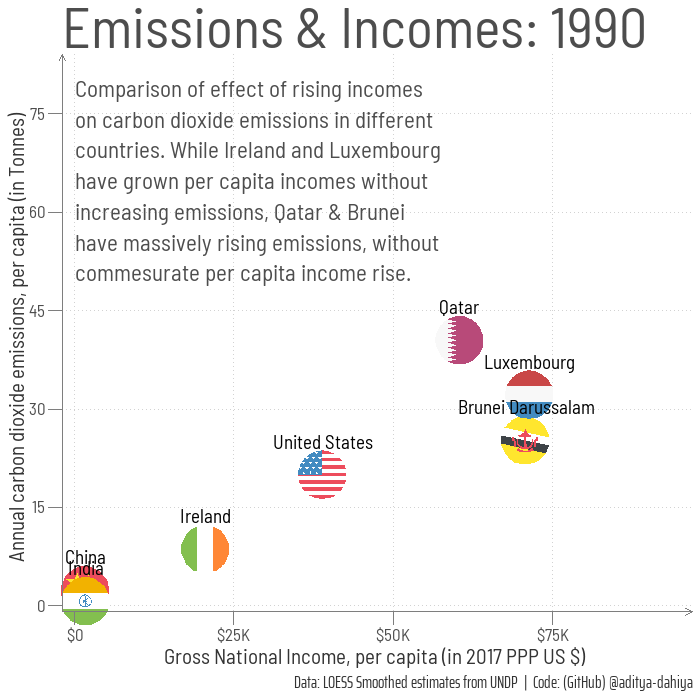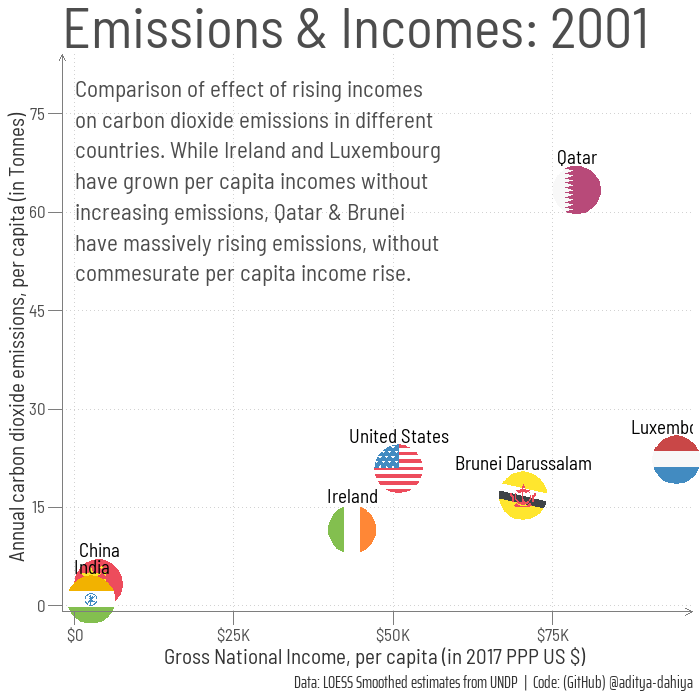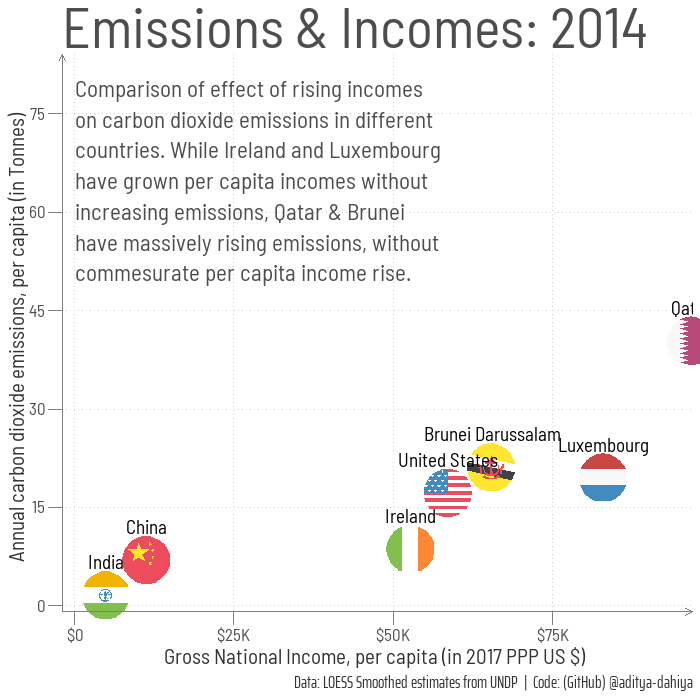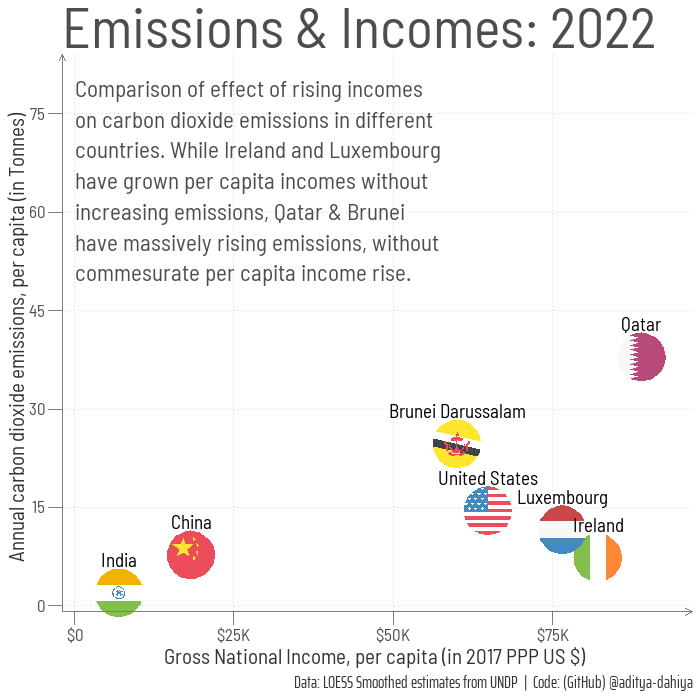
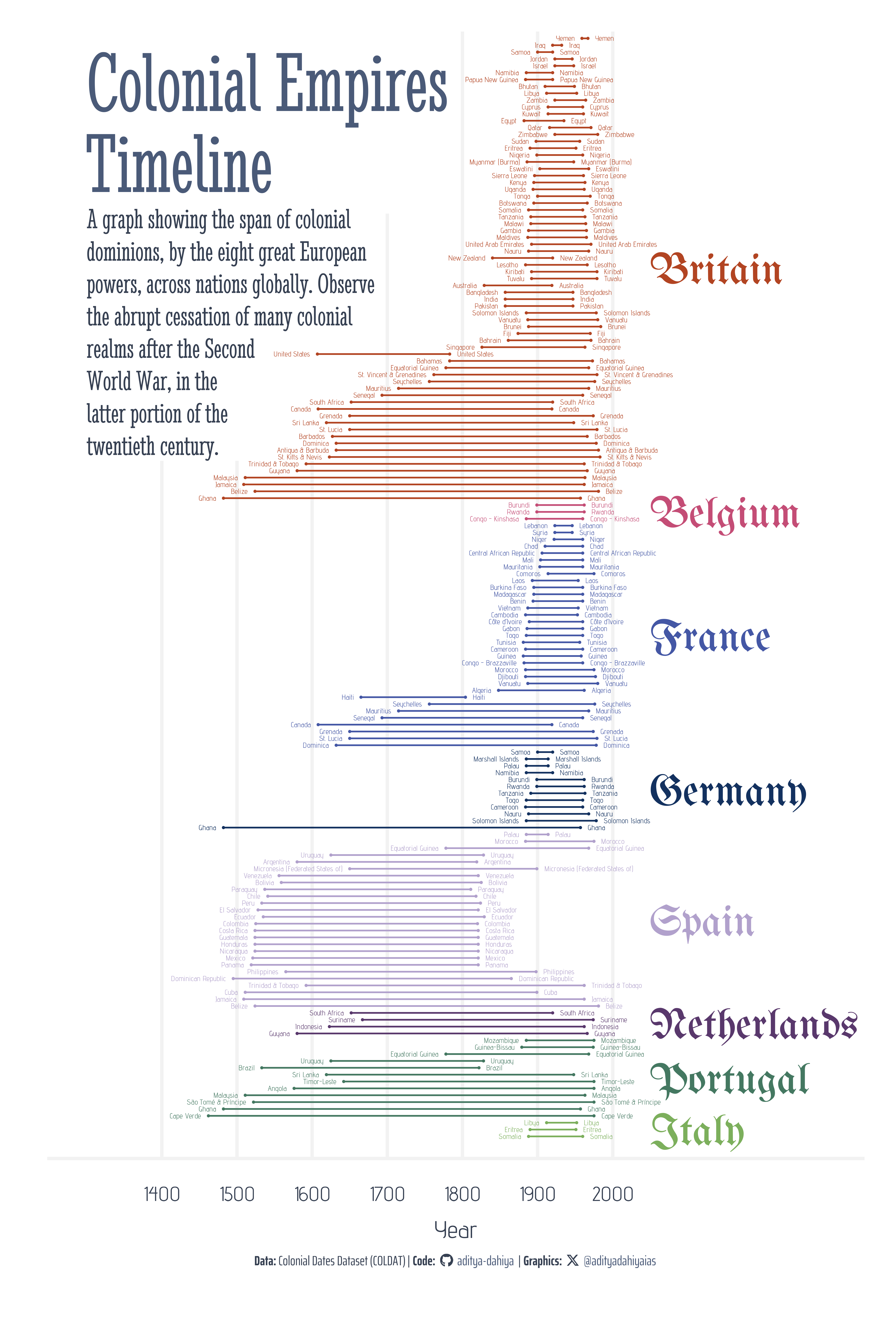
# =============================================================================#
# About the Dataset-------------------------------------------------------------
# =============================================================================#
# Credit: State of California, Department of Motor Vehicles
# https://www.dmv.ca.gov/portal/
# https://twitter.com/ca_dmv
# @CA_DMV
# To test or deploy self-driving cars on California's public roads, companies
# must obtain a permit from the state DMV's Autonomous Vehicles Program. As part
# of the permit requirements, these companies are obliged to submit yearly
# reports detailing the frequency of instances where their vehicles exited
# autonomous mode during tests. This includes cases resulting from technology
# failures or situations demanding manual intervention by the test driver/
# operator for safety reasons. These disengagement reports include information
# such as the company name, permit number, VIN, monthly mileage, and annual
# disengagements for each vehicle, even if there were none.
#
# Additionally, for each disengagement, the reports provide details such as the
# vehicle involved, date of occurrence, initiator of the disengagement (whether
# it was the vehicle itself, the test driver, remote operator, or passenger),
# type of location, and a brief summary of the event.
# Source: https://www.dmv.ca.gov/portal/vehicle-industry-services/autonomous-vehicles/disengagement-reports/
# DISENGAGEMENT REPORTS
# Autonomous vehicle makers participating in the Autonomous Vehicle Tester (AVT)
# Program and AVT Driverless Program must annually submit reports detailing the
# frequency of instances where their vehicles exited autonomous mode during
# testing. This encompasses occurrences triggered by technological malfunctions
# or scenarios necessitating manual intervention by the test driver/operator for
# safe operation.
# 2023 Disengagement Reports
# 2023 Autonomous Vehicle Disengagement Reports (CSV)
url1 <- "https://www.dmv.ca.gov/portal/file/2023-autonomous-vehicle-disengagement-reports-csv/"
# 2023 Autonomous Mileage Reports (CSV)
url2 <- "https://www.dmv.ca.gov/portal/file/2023-autonomous-mileage-reports-csv/"
# 2022-23 Autonomous Vehicle Disengagement Reports (CSV)(first-time filers)
# url3 <- "https://www.dmv.ca.gov/portal/file/2022-23-autonomous-vehicle-disengagement-reports-csvfirst-time-filers/"
# 2022-23 Autonomous Mileage Reports (CSV)(first-time filers)
# url4 <- "https://www.dmv.ca.gov/portal/file/2022-23-autonomous-mileage-reports-csvfirst-time-filers/"
# 2023 Autonomous Vehicle Disengagement Reports (CSV)(driverless)
# url5 <- "https://www.dmv.ca.gov/portal/file/2023-autonomous-vehicle-disengagement-reports-csvdriverless/"
# 2023 Autonomous Mileage Reports (CSV)(driverless)
# url6 <- "https://www.dmv.ca.gov/portal/file/2023-autonomous-mileage-reports-csvdriverless/"
# =============================================================================#
# Library Load-in---------------------------------------------------------------
# =============================================================================#
# Data Wrangling Tools
library(tidyverse)
library(janitor)
# Final plot (ggplot2) tools
library(scales)
library(fontawesome)
library(ggtext)
library(showtext)
library(patchwork)
library(ggimage)
library(ggfittext)
library(colorspace)
# ==============================================================================#
# Data Load-in------------------------------------------------------------------
# ==============================================================================#
# {1} 2023 Autonomous Vehicle Disengagement Reports (CSV)
df1 <- read_csv(url1) |> remove_empty()
# {2} 2023 Autonomous Mileage Reports (CSV)
df2 <- read_csv(url2) |> remove_empty()
# ==============================================================================#
# Data Wrangling----------------------------------------------------------------
# ==============================================================================#
# {1} 2023 Autonomous Vehicle Disengagement Reports (CSV)
# Store full names of Variables
cn_df1 <- names(df1)
# short names
names(df1) <- c("manufacturer",
"permit_number",
"date",
"vin",
"driver_need",
"driver",
"disengagement_initiate",
"disengagement_location",
"description")
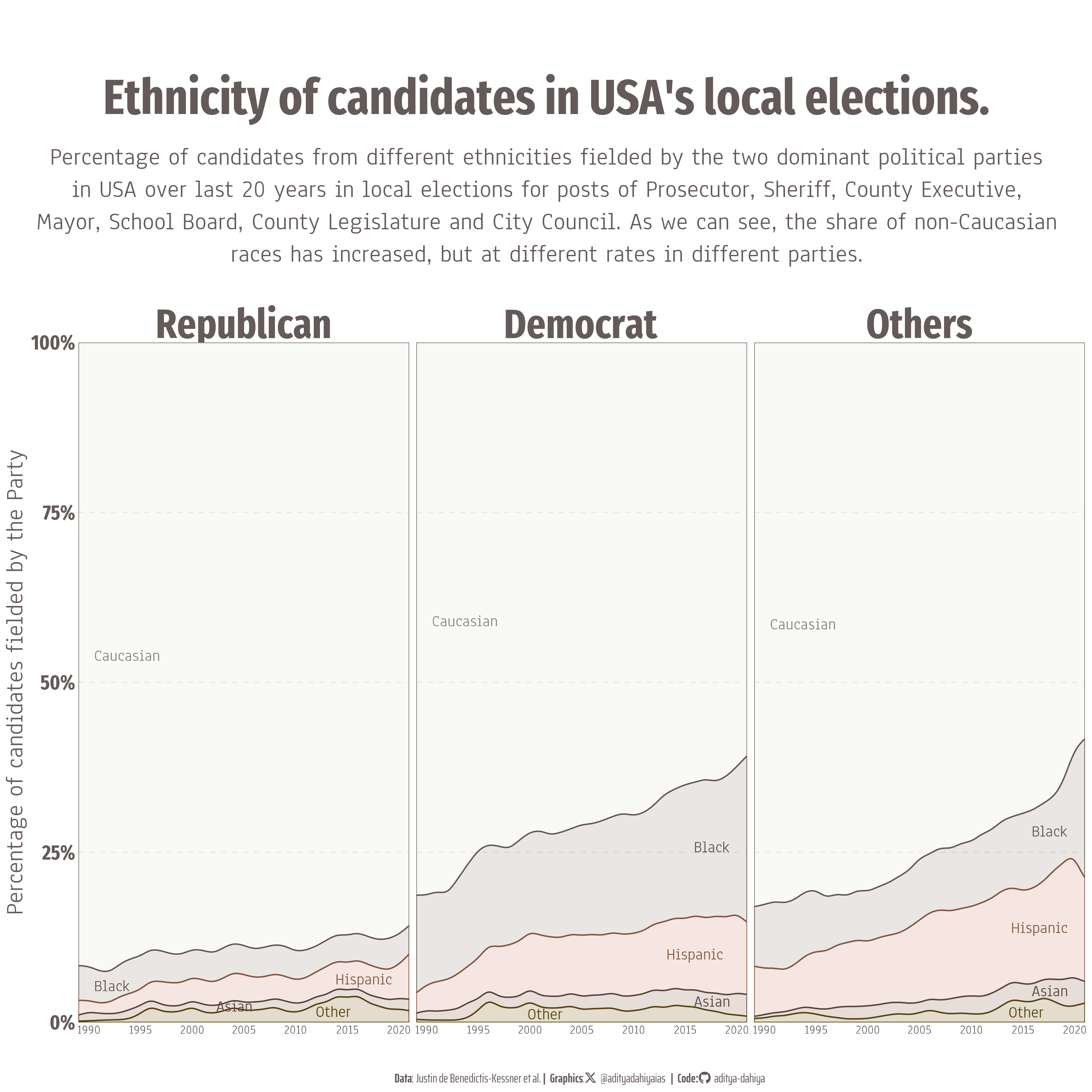
# Number of disengagements by AV vs. Test Driver for each manufacturer
plot1df1 <- df1 |>
mutate(disengagement_initiate = if_else(
str_detect(disengagement_initiate, "AV"),
"AV System",
"Test Driver")) |>
group_by(manufacturer) |>
count(disengagement_initiate) |>
# A minor nomenculature change to match data in all plots
mutate(manufacturer = if_else(
manufacturer == "Nissan North America",
"Nissan",
manufacturer
))
# Top 14 descriptions of reasons for disengagements
sum_desc <- df1 |>
mutate(
description = fct(description),
description = fct_lump_n(description, n = 13)
) |>
count(description, sort = TRUE) |>
pull(description)
# Number of disengagements by reason for each manufacturer
plot2df1 <- df1 |>
# A minor nomenculature change to match data in all plots
mutate(manufacturer = if_else(
manufacturer == "Nissan North America",
"Nissan",
manufacturer
)) |>
mutate(
short_description = case_when(
description == sum_desc[1] ~ "Wrongly predicted road user behavior",
description == sum_desc[2] ~ "Other Reasons",
description == sum_desc[3] ~ "Hardware issues",
description == sum_desc[4] ~ "Software issues",
description == sum_desc[5] ~ "Vehicle too close to road boundary",
description == sum_desc[6] ~ "Onboard map errors",
description == sum_desc[7] ~ "Unexpected braking",
description == sum_desc[8] ~ "Undesirable lane placement",
description == sum_desc[9] ~ "Too close to preceding vehicle",
description == sum_desc[10] ~ "Lane violation",
description == sum_desc[11] ~ "Motion plan error",
description == sum_desc[12] ~ "Unwanted maneuver by vehicle",
description == sum_desc[13] ~ "Lane violation",
description == "Prediction discrepancy. Adjacent vehicle made illegal maneuver from left turn only lane." ~ "Other vehicles' fault",
description == "Prediction discrepancy. Late and illegal cut-in from other vehicle from adjacent lane." ~ "Illegal cut by others",
description == "Prediction discrepancy. Late cut-in from other vehicle from adjacent lane." ~ "Late cut by others",
str_detect(description, "Planning Logic") ~ "Incorrect Planning Logic",
str_detect(description, "Object Perception") ~ "Incorrect Object Perception",
str_detect(description, "The lead vehicle stopped for stop sign was falsely identified") ~ "Incorrect Object Perception",
str_detect(description, "While traveling on a narrow road, an incoming vehicle approached") ~ "Other vehicles' fault",
str_detect(description, "The AV system exited autonomous mode due to hardware irregularity.") ~ "Hardware issues",
str_detect(description, "Manual disengagement as the AV had hardware irregularity. The HMI") ~ "Hardware issues",
str_detect(description, "Manual disengagement after a scooter made contact with the AV.") ~ "Other vehicles' fault",
str_detect(description, "Disengage for a perception discrepancy for which a component of the vehicle's perception system") ~ "Perception Error",
str_detect(description, "Disengage for a software discrepancy for which our vehicle's diagnostics received") ~ "Software issues",
.default = "Other Reasons"
)
) |>
group_by(manufacturer) |>
count(short_description, sort = TRUE) |>
rename(snag = n)
# {2} 2023 Autonomous Mileage Reports (CSV)
# Store full names of variables
cn_df2 <- names(df2)
# cleaner names
df2 <- df2 |> clean_names()
# Tibble of Brands, total mileage and disengagements
plotdf2 <- df2 |>
select(-c(vin_number, annual_total,permit_number)) |>
pivot_longer(
cols = -c(manufacturer, annual_total_of_disengagements),
names_to = "month",
values_to = "miles"
) |>
group_by(manufacturer) |>
summarise(total_miles = sum(miles, na.rm = TRUE),
total_disengagements = sum(annual_total_of_disengagements)) |>
arrange(desc(total_miles)) |>
mutate(diseng_p_100m = 100 * total_disengagements / total_miles ) |>
# Adding logos of manufacturers for the plot
mutate(logo_url = c(
"https://upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Waymo_logo.svg/1200px-Waymo_logo.svg.png",
"https://upload.wikimedia.org/wikipedia/commons/5/5d/Zoox_logo_2021.png",
"https://upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Cruise_logo.svg/2560px-Cruise_logo.svg.png",
"https://1000logos.net/wp-content/uploads/2016/10/Apple-Logo.png",
"https://seekvectorlogo.com/wp-content/uploads/2023/03/nuro-inc-vector-logo.png",
"https://media.designrush.com/inspiration_images/136995/conversions/_1524250340_590_Mercedes-Benz-Logo-Wordmark-mobile.jpg",
"https://mms.businesswire.com/media/20231108625285/en/1938556/23/ghost_combination_black_new.jpg",
"https://d1.awsstatic.com/customer-references-case-studies-logos/Customer-References-600x400-logos/600X400_WeRide_logo.8637603e647959947cbd83eded476566dd45ef46.png",
"https://cdn.cookielaw.org/logos/8c60fe9e-585e-46b1-8f92-eba17239401e/d3e43cda-e0a4-42f2-9c04-0e1900c3f68f/808c47fb-8484-44eb-b369-d90d6bb4733e/motional_logo_stack_colorrev_rgb_black.png",
"https://www.apollo.auto/abolo/images/logo.png",
"https://mma.prnewswire.com/media/777482/ai_motive_landscape_logo_Logo.jpg",
"https://s3-us-west-2.amazonaws.com/cbi-image-service-prd/original/fc97e73f-33bd-414e-a9ef-e4504451e4c0.png",
"https://upload.wikimedia.org/wikipedia/commons/8/8c/Nissan_logo.png",
"https://global.toyota/pages/news/images/2023/04/11/0800/20230411_02_01.png",
"https://s28.q4cdn.com/896456191/files/images/didi-logo.png",
"https://logos-world.net/wp-content/uploads/2022/11/Qualcomm-Emblem.png",
"https://upload.wikimedia.org/wikipedia/commons/thumb/1/16/Bosch-logo.svg/2560px-Bosch-logo.svg.png",
"https://ces.vporoom.com/Imagry/image/imagry-logo-with-short-tagline.gif",
"https://d1io3yog0oux5.cloudfront.net/_e08a077351e2c1b3b2e6179a6ccad2db/aurora/logo.png",
"https://gatik.ai/wp-content/uploads/gatik-logo.png",
"https://upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Valeo_Logo.svg/1200px-Valeo_Logo.svg.png"
))
# Change levels of Manufacturer to have a common order in all plots
manufacturer_levels <- c(plotdf2$manufacturer, "Valeo")
plotdf2 <- plotdf2 |>
mutate(manufacturer = fct(manufacturer, levels = manufacturer_levels)) |>
mutate(manufacturer = fct_rev(manufacturer))
plot1df1 <- plot1df1 |>
mutate(manufacturer = fct(manufacturer, levels = manufacturer_levels)) |>
mutate(manufacturer = fct_rev(manufacturer))
plot2df1 <- plot2df1 |>
mutate(manufacturer = fct(manufacturer, levels = manufacturer_levels)) |>
mutate(manufacturer = fct_rev(manufacturer))
# Top n manufacturers by number of miles driven
top_manufacturers <- plotdf2 |>
slice_max(order_by = total_miles, n = 11) |>
pull(manufacturer)
# Common Manufacturers
common_manufacturers <- plot1df1 |>
inner_join(plot2df1, relationship = "many-to-many") |>
inner_join(plotdf2) |>
distinct(manufacturer) |>
pull(manufacturer) |>
as.character()
# =============================================================================#
# Options & Visualization Parameters--------------------------------------------
# =============================================================================#
# Load fonts
font_add_google("Fredericka the Great",
family = "title_font"
) # Font for titles
font_add_google("Saira Extra Condensed",
family = "caption_font"
) # Font for the caption
font_add_google("Fira Sans Extra Condensed",
family = "body_font"
) # Font for plot text
showtext_auto()
# Define colours
bg_col <- "white" # Background Colour
text_col <- "#04225CFF" # Colour for the text
text_hil <- "#309D96FF" # Colour for higlighted text
# Define Text Size
ts <- unit(30, units = "cm") # Text Size
# Caption stuff
sysfonts::font_add(
family = "Font Awesome 6 Brands",
regular = here::here("docs", "Font Awesome 6 Brands-Regular-400.otf")
)
github <- ""
github_username <- "aditya-dahiya"
xtwitter <- ""
xtwitter_username <- "@adityadahiyaias"
social_caption_1 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{github};</span> <span style='color: {text_hil}'>{github_username} </span>")
social_caption_2 <- glue::glue("<span style='font-family:\"Font Awesome 6 Brands\";'>{xtwitter};</span> <span style='color: {text_hil}'>{xtwitter_username}</span>")
# Add text to plot--------------------------------------------------------------
plot_title <- "Behind the Wheel of Tomorrow:\nCalifornia's Autonomous Vehicles Testing Data"
plot_caption <- paste0("**Data:** State of California, Department of Motor Vehicles", " | ", " **Code:** ", social_caption_1, " | ", " **Graphics:** ", social_caption_2)
subtitle_text <- "An analysis of Autonomous Vehicles’ (AV) Testing Data (released by the State of California's Department of Motor Vehicles) reveals the performance of various AV Manufacturers. The number of total miles driven, disengagement rates (per 100 miles driven), and common reasons for autonomous mode exits (termed “disengagements”) indicate dominance & error-free tech of Google’s Waymo, and error-prone nature of Apple’s AV."
plot_subtitle <- str_wrap(subtitle_text, width = 115)
# ==============================================================================#
# Data Visualization------------------------------------------------------------
# ==============================================================================#
tempdf2 <- plotdf2 |>
filter(manufacturer %in% common_manufacturers) |>
filter(manufacturer %in% top_manufacturers)
g1 <- tempdf2 |>
ggplot(
mapping = aes(
x = total_miles,
y = manufacturer
)
) +
geom_col(
fill = text_col,
color = "black",
alpha = 0.5
) +
geom_text(
aes(
label = comma(total_miles),
colour = (total_miles > 1e6)
),
family = "body_font",
size = 1.8 * ts,
hjust = if_else(tempdf2$total_miles > 1e6,
1.1, -0.1)
) +
geom_image(
aes(
x = -1.7e6,
image = logo_url
),
by = "height",
hjust = 1
) +
scale_colour_manual(values = c(text_col, "white")) +
scale_x_continuous(
expand = expansion(c(0.45, 0.2)),
breaks = c(1e5, 1e6, 2e6, 3e6),
labels = label_number(
scale_cut = cut_short_scale()
)
) +
labs(
subtitle = "Total AV miles driven by Manufacturer's\nAutonomous Vehicles (2023))",
y = NULL, x = NULL
) +
theme_minimal() +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
panel.grid = element_blank(),
panel.grid.major.x = element_line(
linetype = 2,
colour = text_hil,
linewidth = 1
),
axis.text.x = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(0, 0, 0, 0,
unit = "cm"),
lineheight = 0.35
),
plot.subtitle = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.25
),
legend.position = "none"
)
g2 <- tempdf2 |>
ggplot(
mapping = aes(
x = diseng_p_100m,
y = manufacturer
)
) +
geom_col(
fill = text_hil,
colour = "black",
alpha = 0.5
) +
geom_text(
aes(
label = round(diseng_p_100m, 2),
colour = (diseng_p_100m > 35)
),
family = "body_font",
size = 1.8 * ts,
hjust = if_else(tempdf2$diseng_p_100m > 35,
1.1, -0.1)
) +
scale_colour_manual(values = c(text_hil, "white")) +
scale_x_continuous(
expand = expansion(c(0, 0.2)),
breaks = c(0, 25, 50),
labels = c(0, 25, 50)
) +
labs(
subtitle = "Errors \n(per 100 miles)",
y = NULL, x = NULL
) +
theme_minimal() +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
panel.grid = element_blank(),
panel.grid.major.x = element_line(
linetype = 2,
colour = text_hil,
linewidth = 1
),
axis.text.x = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(0, 0, 0, 0,
unit = "cm"),
lineheight = 0.35
),
plot.subtitle = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.25
),
legend.position = "none"
)
# Colours for third plot
g3col <- c("#43B48DFF", "#F5773AFF")
g3 <- plot1df1 |>
left_join(plotdf2) |>
mutate(n = n / total_miles) |>
filter(manufacturer %in% common_manufacturers) |>
filter(manufacturer %in% top_manufacturers) |>
ggplot(
mapping = aes(
y = manufacturer,
x = n,
fill = disengagement_initiate,
label = disengagement_initiate,
colour = disengagement_initiate
)
) +
geom_col(
position = "fill",
col = "white"
) +
geom_bar_text(
position = "fill",
hjust = 0.5,
vjust = 0.5,
reflow = TRUE,
place = "center",
min.size = 1,
grow = TRUE,
padding.y = unit(25, "mm"),
lineheight = 0.25
) +
scale_x_continuous(
breaks = c(0, 1),
labels = label_percent()
) +
scale_fill_manual(values = g3col |> lighten(0.7)) +
scale_colour_manual(values = g3col |> darken(0.5)) +
labs(
subtitle = "Who stopped\nthe AV?",
x = NULL, y = NULL
) +
theme_minimal() +
theme(
legend.position = "none",
panel.grid = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_blank(),
plot.subtitle = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.25
)
)
g4 <- plot2df1 |>
left_join(plotdf2) |>
mutate(snag_p_100m = snag / total_miles) |>
mutate(snag_fill = snag_p_100m / sum(snag_p_100m)) |>
filter(manufacturer %in% common_manufacturers) |>
filter(manufacturer %in% top_manufacturers) |>
ggplot(
mapping = aes(
y = manufacturer,
x = snag_p_100m,
fill = short_description,
label = short_description,
color = short_description
)
) +
geom_col(
position = "fill",
colour = "darkgrey"
) +
geom_bar_text(
position = "fill",
hjust = 0.5,
vjust = 0.5,
reflow = TRUE,
place = "center",
min.size = 1,
lineheight = 0.25,
grow = TRUE,
padding.x = unit(15, "mm"),
padding.y = unit(15, "mm")
) +
paletteer::scale_fill_paletteer_d("palettesForR::Lights",
direction = -1) +
scale_color_manual(
values = paletteer::paletteer_d("palettesForR::Lights",
direction = -1) |> darken(0.4)
) +
scale_x_continuous(
breaks = c(0, 0.5, 1),
labels = label_percent()
) +
labs(
subtitle = "Reasons for AV\ndisengagement",
x = NULL, y = NULL
) +
theme_void() +
theme(
legend.position = "none",
panel.grid = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_text(
colour = text_col,
hjust = 0,
family = "body_font",
size = 4 * ts,
margin = margin(0,0,0,0)
),
plot.subtitle = element_text(
hjust = 0.5,
size = 4 * ts,
family = "body_font",
colour = text_col,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.25
)
)
# Composing the plots
plot_design = "AAABCDDD"
g <- g1 + g2 + g3 + g4 +
plot_layout(design = plot_design)
g_final <- g +
plot_annotation(
title = plot_title,
subtitle = plot_subtitle,
caption = plot_caption,
theme = theme(
plot.subtitle = element_text(
hjust = 0.5,
size = 4.8 * ts,
family = "body_font",
colour = text_col,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.3
)
)
) &
theme(
plot.caption = element_textbox(
family = "caption_font",
hjust = 0.5,
colour = text_hil,
size = 4 * ts,
margin = margin(1, 0, 2, 0,
unit = "cm"
)
),
plot.title = element_text(
hjust = 0.5,
size = 10 * ts,
family = "title_font",
face = "bold",
colour = text_hil,
margin = margin(2, 0, 0, 0,
unit = "cm"
),
lineheight = 0.35
),
plot.background = element_rect(
fill = "transparent",
color = "transparent",
linewidth = 0
),
plot.margin = margin(0, 0, 0, 0),
legend.background = element_rect(
fill = "transparent",
color = "transparent"
),
panel.background = element_rect(
fill = "transparent",
colour = "transparent"
)
)
# =============================================================================#
# Image Saving-----------------------------------------------------------------
# =============================================================================#
ggsave(
filename = here::here("docs", "dip_self_driving_cars.png"),
plot = g_final,
width = 75,
height = 90,
units = "cm",
bg = bg_col
)