# Standard Deviation of Principal Component Score VectorsprUSA$sdev
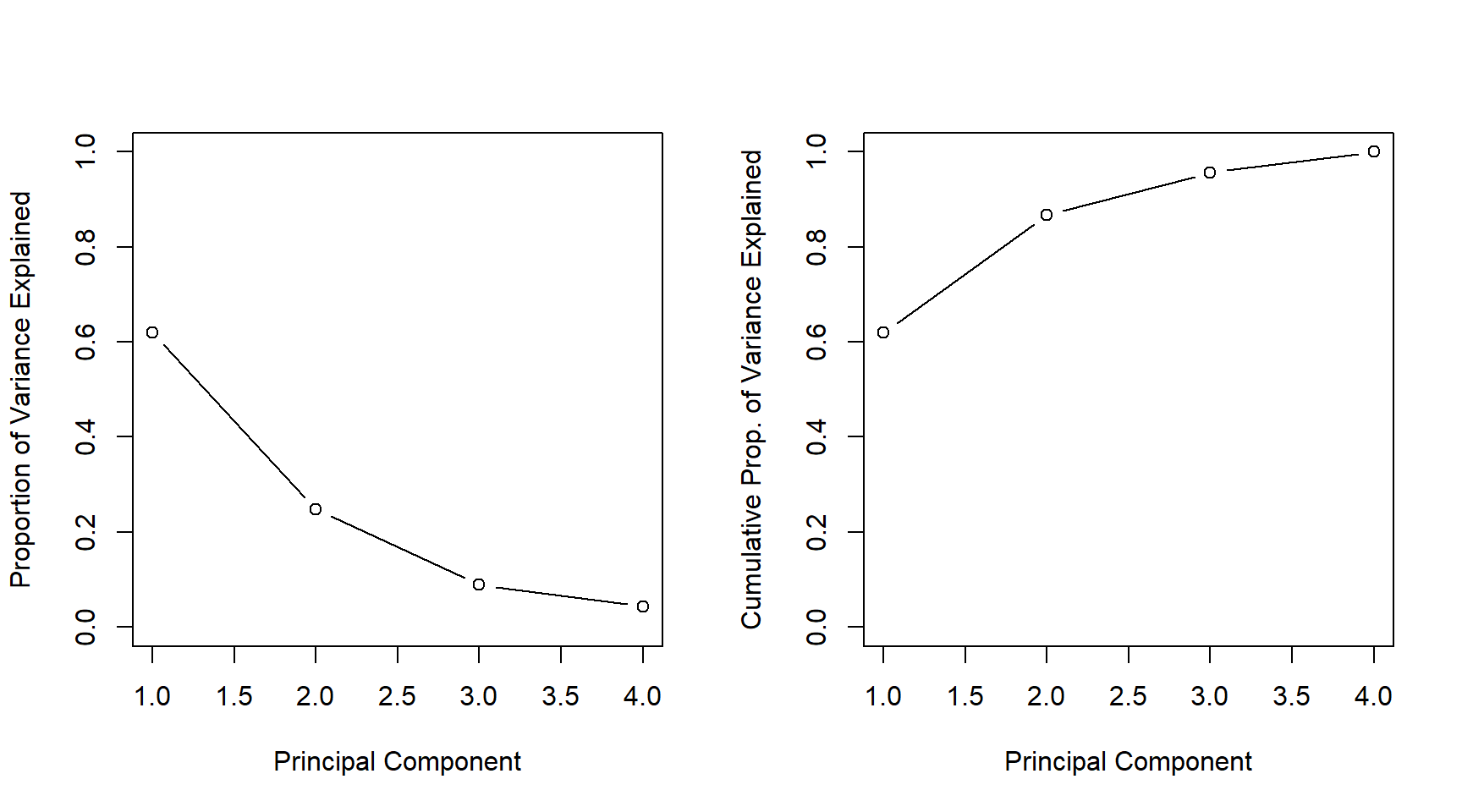
[1] 1.57 0.99 0.60 0.42
# Computing Proportion of variance explainedpr.var <- prUSA$sdev^2/sum(prUSA$sdev^2)pr.var
[1] 0.620 0.247 0.089 0.043
# Creating a Scree Plot and a Cumulative Variance Explained plotpar(mfrow =c(1, 2))plot(pr.var,type ="b", xlab ="Principal Component",ylab ="Proportion of Variance Explained", ylim =c(0, 1))plot(cumsum(pr.var),type ="b", xlab ="Principal Component",ylab ="Cumulative Prop. of Variance Explained", ylim =c(0, 1))
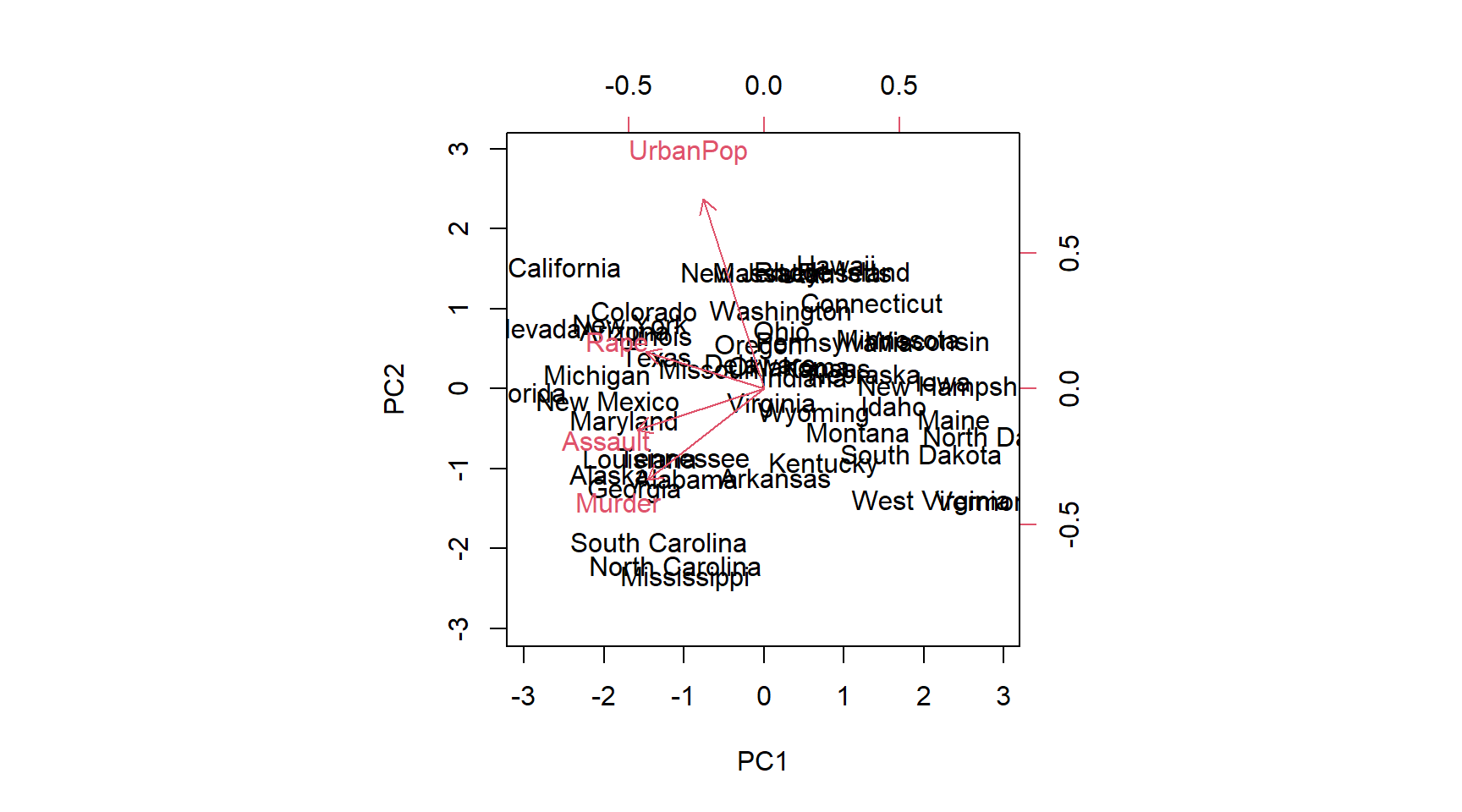
# Creating a biplotpar(mfrow =c(1, 1))biplot(prUSA, scale =0)
Lab 2: Clustering
In this part, we will use \(K\)-means clustering and Hierarchical Clustering.
10.5.1 K-Means Clustering
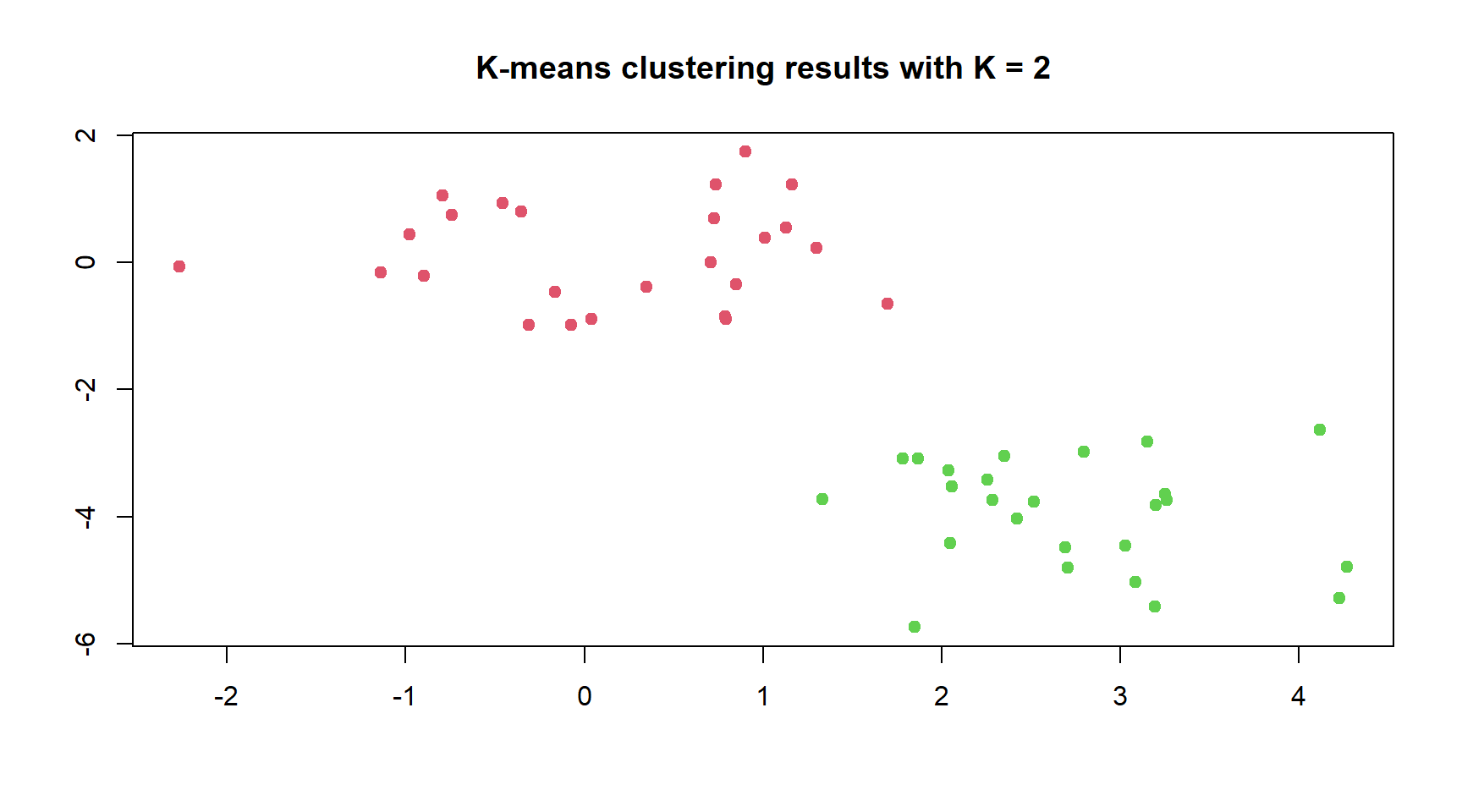
# Generate a simulated data set matrix (25 X 2) with two clustersset.seed(3)x <-matrix(rnorm(100), ncol =2)x[1:25, 1] <- x[1:25, 1] +3x[1:25, 2] <- x[1:25, 2] -4# Perform K Means Clustering with K = 2km2 <-kmeans(x = x, centers =2, nstart =20)km2
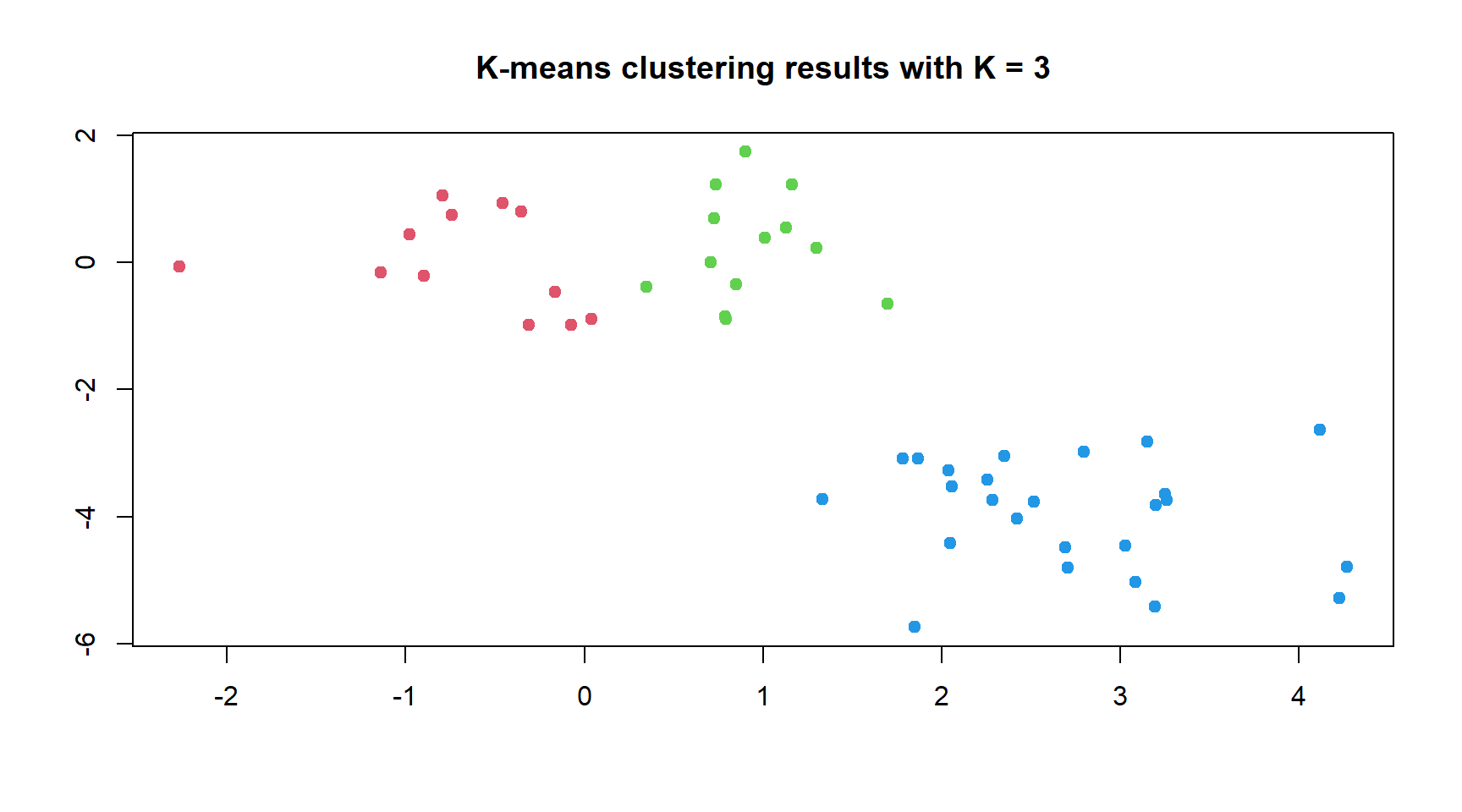
plot(x,col = (km3$cluster +1), pch =20, xlab ="", ylab ="", cex =1.5,main ="K-means clustering results with K = 3")
# Demonstrating the use of nstart argumentkm3_1 <-kmeans(x = x, centers =3, nstart =1)km3$tot.withinss
[1] 53
km3_1$tot.withinss
[1] 53
10.5.2 Hierarchical Clustering
# Creating a distance matrix with dist()options(digits =2)class(dist(x))
[1] "dist"
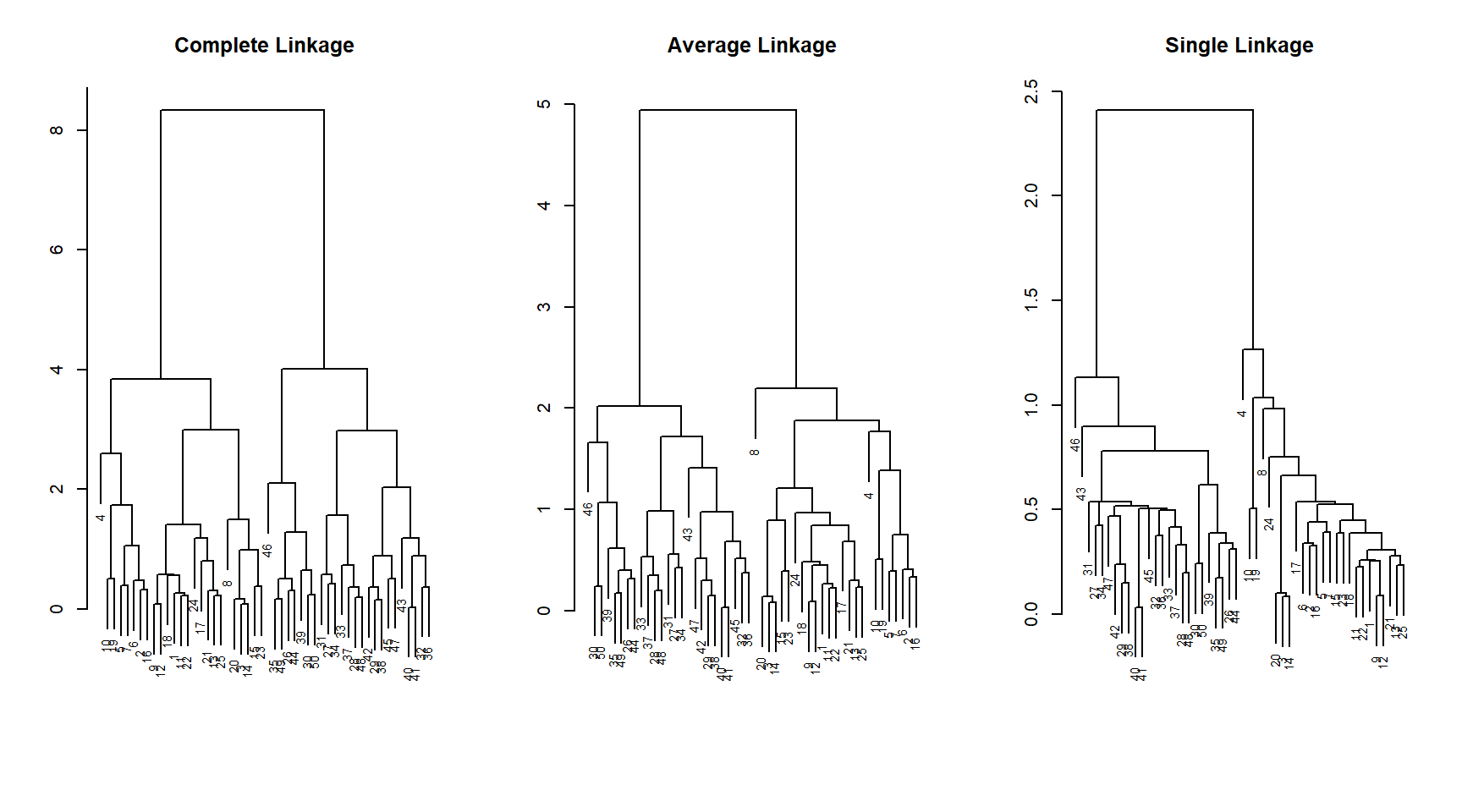
# Using hclust() to do hierarchical clustering in R on same data set# Three different linkage methodshc.complete <-hclust(d =dist(x), method ="complete")hc.average <-hclust(d =dist(x), method ="average")hc.single <-hclust(d =dist(x), method ="single")# Plotting the dendrograms from each linkage methodpar(mfrow =c(1, 3))plot(hc.complete,cex =0.7, xlab ="", ylab ="", sub ="",main ="Complete Linkage")plot(hc.average,cex =0.7, xlab ="", ylab ="", sub ="",main ="Average Linkage")plot(hc.single,cex =0.7, xlab ="", ylab ="", sub ="",main ="Single Linkage")
# Comparing clusters generated using cutree() functioncutree(tree = hc.complete, k =2)
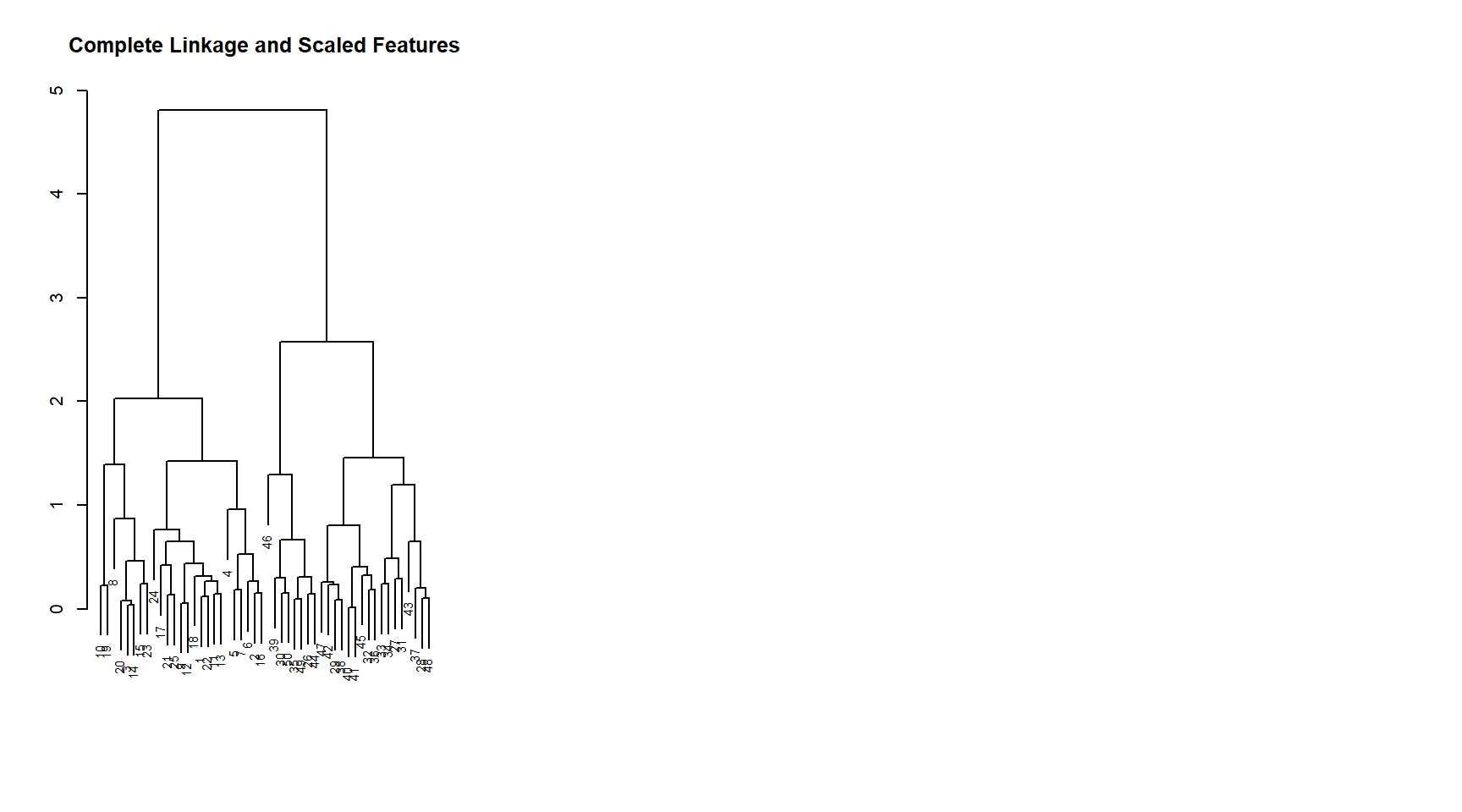
# Scaling variables before performing hierarchical clusteringxsc <-scale(x)plot(hclust(d =dist(xsc), method ="complete"),cex =0.7, xlab ="",ylab ="", sub ="", main ="Complete Linkage and Scaled Features")# Using correlation based distance# Simulated data set of 3 dimensions (with three clusters)x <-matrix(rnorm(90), ncol =3)x[1:10, ] <- x[1:10, ] -2x[20:30, ] <- x[20:30, ] +2# Euclidean distance based clustering (Partial success in both methods)kmeans(x = x, centers =3, nstart =20)$cluster
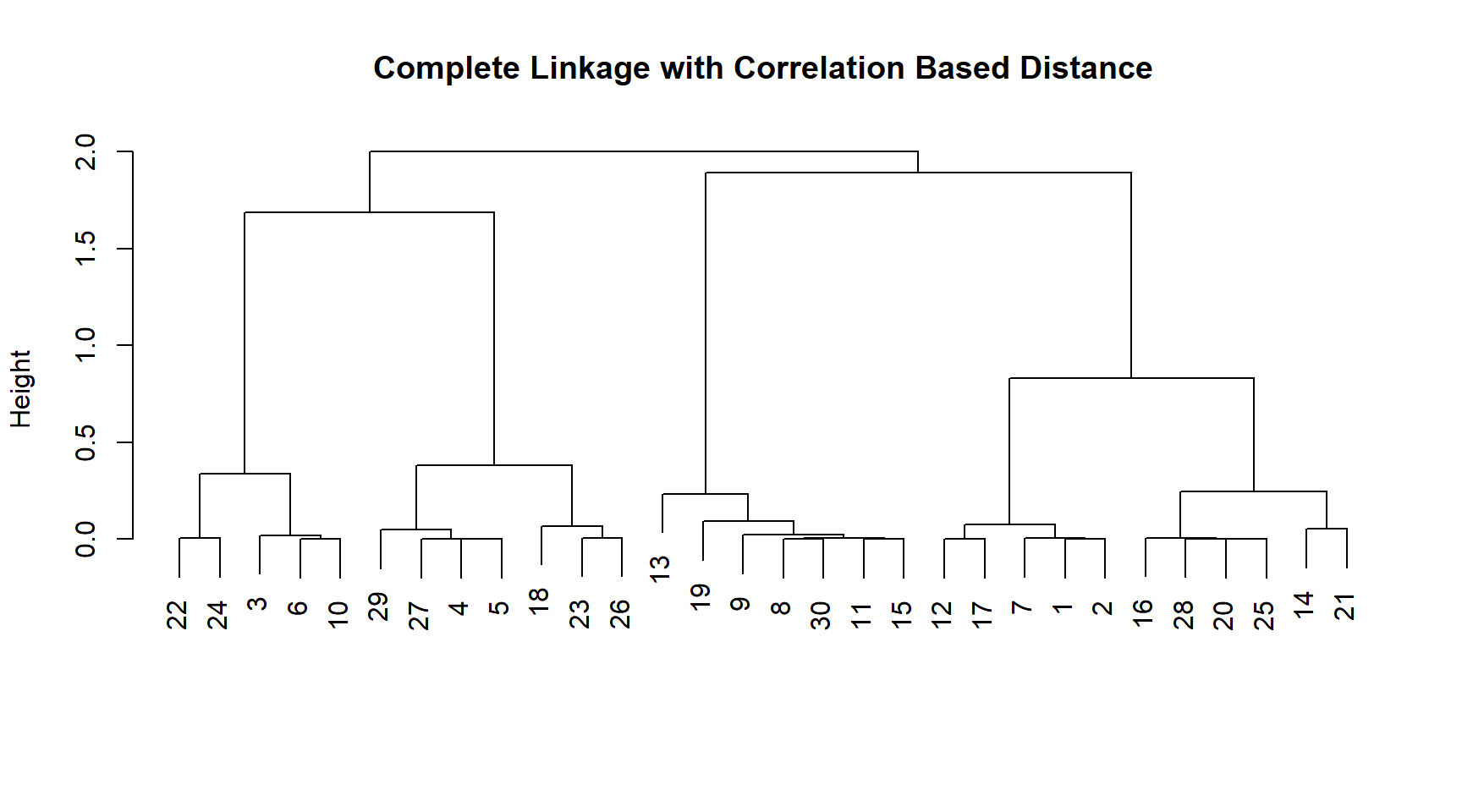
# Creating a matrix of correlation based distancedd <-as.dist(m =1-cor(t(x)))par(mfrow =c(1, 1))
plot(hclust(dd, method ="complete"),xlab ="", sub ="",main ="Complete Linkage with Correlation Based Distance")
Lab 3: NCI60 Data Example
PCA on NCI60 data
In this lab, we use th NCI60 cancer cell line micro-array data from the ISLR package. We will perform K-Means Clustering and Hierarchical Clustering on the data set.
# Loading data set and storing it locallylibrary(ISLR)library(tidyverse)names(NCI60)
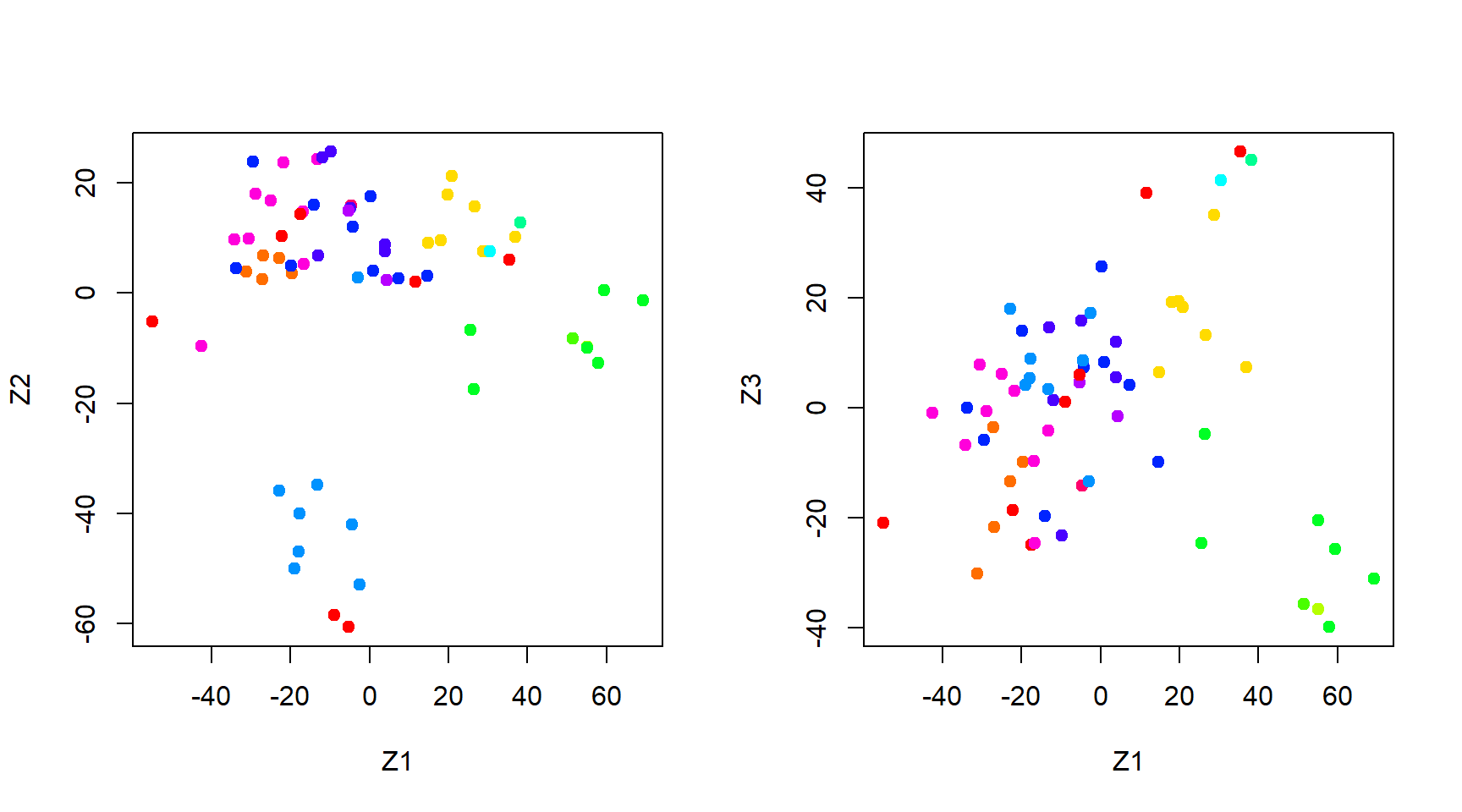
# Performing PCA on the NCI60 data setprnci <-prcomp(x = nci.data, scale =TRUE)# Plotting the data on first two principal components# creating a customized function to color the observation spointsCols <-function(vec) { cols <-rainbow(length(unique(vec)))return(cols[as.numeric(as.factor(vec))])}par(mfrow =c(1, 2))plot(prnci$x[, 1:2],col =Cols(nci.labs),pch =19, xlab ="Z1", ylab ="Z2")plot(prnci$x[, c(1, 3)],col =Cols(nci.labs),pch =19, xlab ="Z1", ylab ="Z3")
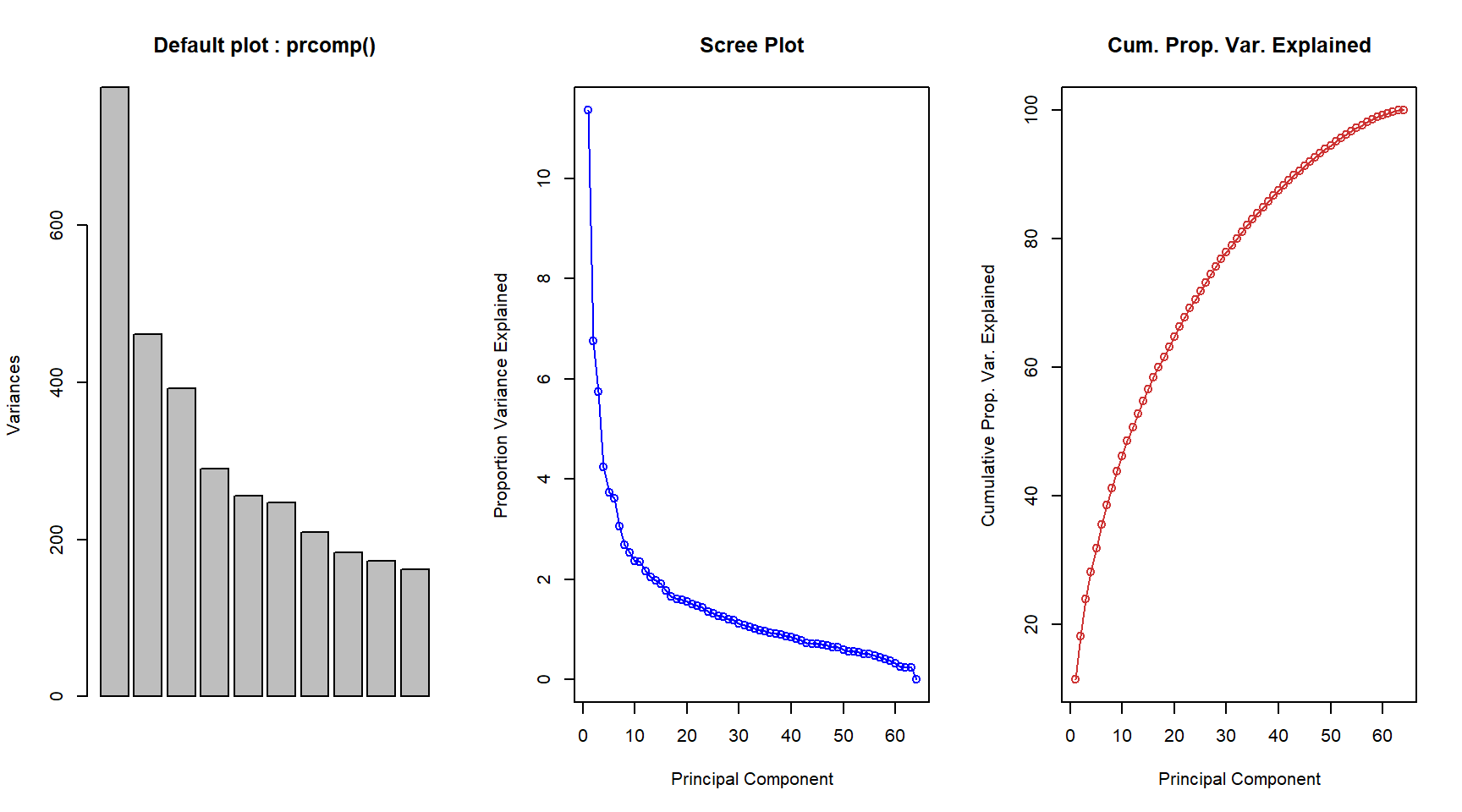
# Plotting the Scree Plot and Proportion of Variance Explainedpar(mfrow =c(1, 3))plot(prnci, main ="Default plot : prcomp()")pve <-100* (prnci$sdev^2) /sum(prnci$sdev^2)plot(pve,xlab ="Principal Component", ylab ="Proportion Variance Explained",main ="Scree Plot", col ="blue", type ="o")plot(cumsum(pve),xlab ="Principal Component", ylab ="Cumulative Prop. Var. Explained",main ="Cum. Prop. Var. Explained", col ="brown3", type ="o")
# Examining summary of a prcomp() objectsummary(prnci)$importance[1:3, 1:7]
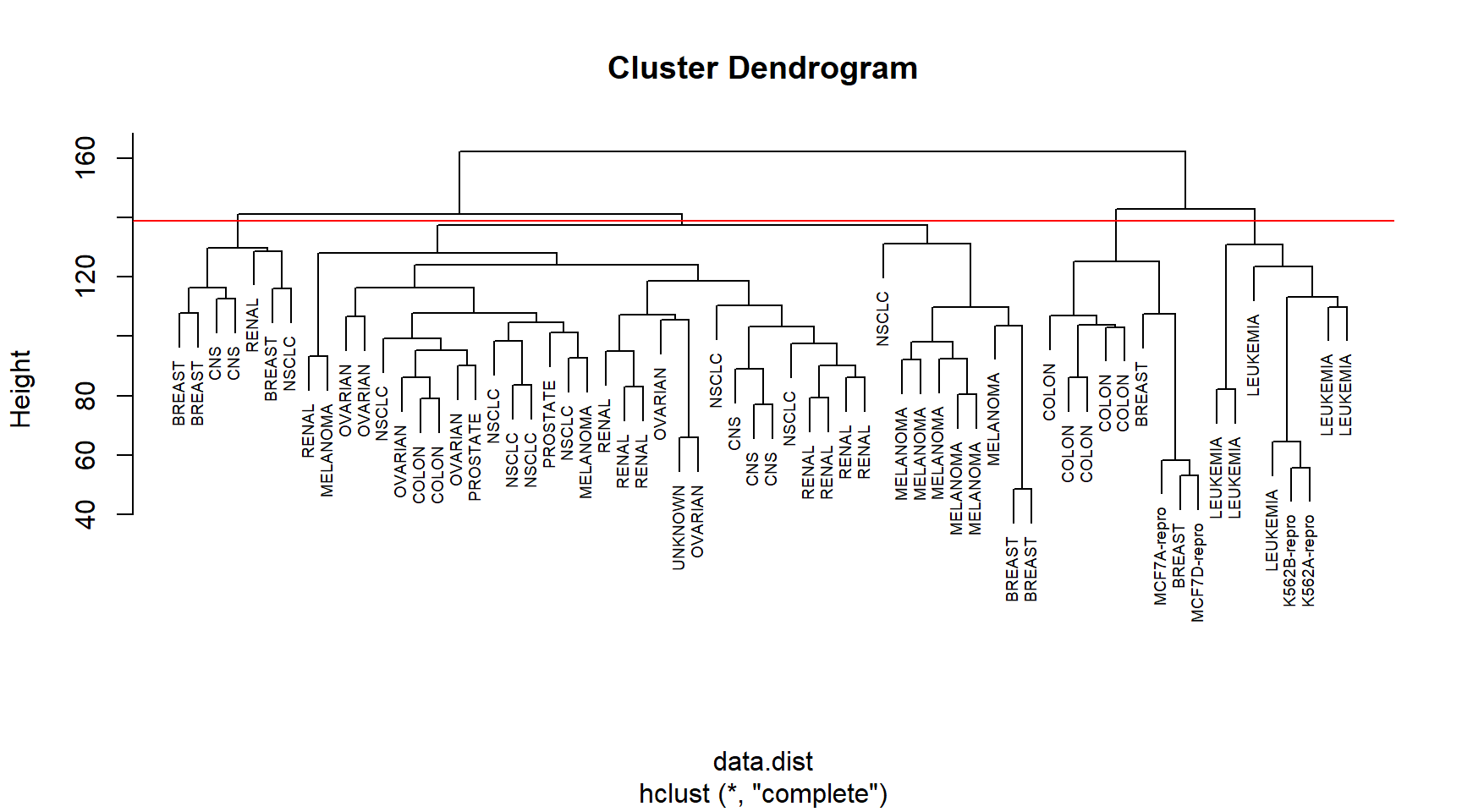
# Performing Hierarchical and K-Means clustering only on first 5 principal componentshc.pr.nci <-hclust(dist(scale(prnci$x[, 1:5])))hc.pr.clusters <-cutree(hc.pr.nci, 4)km.pr.clusters <-kmeans(prnci$x[, 1:5], centers =4, nstart =20)$clustertable(km.pr.clusters, hc.pr.clusters)