# Loading libraries and data setlibrary(tree)library(ISLR)library(tidyverse)data("Carseats")options(digits =2)# Creating a binary variable for Sales; removing Sales variable from data setCarseats <- Carseats %>%mutate(SalesHigh =as.factor(ifelse(Sales >8, yes ="Yes", no ="No"))) %>%select(-Sales)# Fitting a classification tree model to the data set for predicting SalesHightree.carseats <-tree(SalesHigh ~ ., data = Carseats)# Displaying Summary fo Classification Treesummary(tree.carseats)
Classification tree:
tree(formula = SalesHigh ~ ., data = Carseats)
Variables actually used in tree construction:
[1] "ShelveLoc" "Price" "Income" "CompPrice" "Population"
[6] "Advertising" "Age" "US"
Number of terminal nodes: 27
Residual mean deviance: 0.46 = 171 / 373
Misclassification error rate: 0.09 = 36 / 400
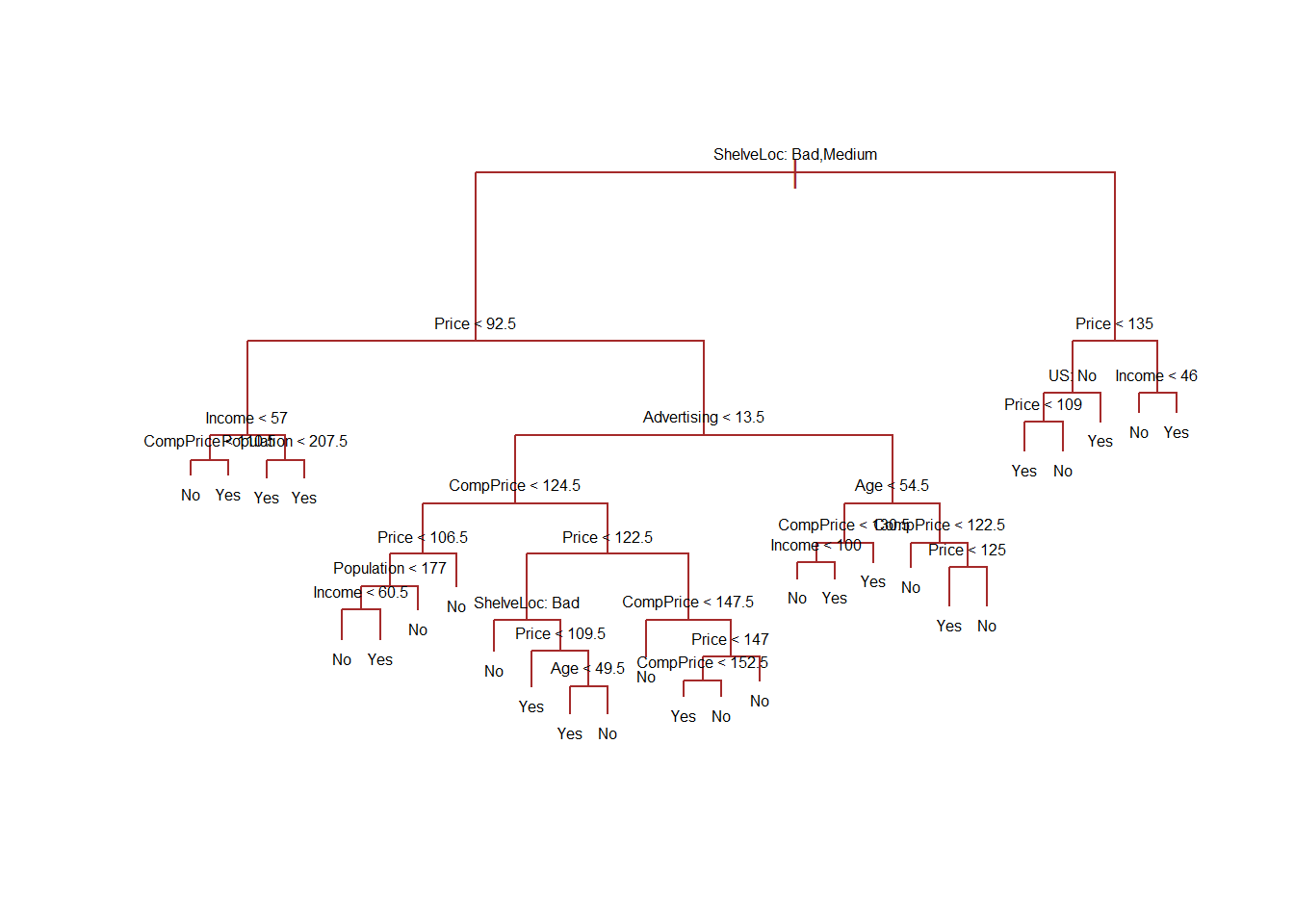
# Plotting the Classification treeplot(tree.carseats, col ="brown", type ="proportional")text(tree.carseats, pretty =0, cex =0.5)
# Examining the output from tree object printnames(tree.carseats)
[1] "frame" "where" "terms" "call" "y" "weights"
names(tree.carseats$frame)
[1] "var" "n" "dev" "yval" "splits" "yprob"
# Creating a testing and training set in Carseats Data Setnrow(Carseats)
[1] 400
set.seed(3)train <-sample(c(TRUE, FALSE), size =200, replace =TRUE)Test.Carseats <- Carseats[!train, ]Truth <- Carseats[!train, "SalesHigh"]# Fitting a classification tree to the training datatree.carseats <-tree(SalesHigh ~ ., data = Carseats, subset = train)# Obtaining predicted values in test datapred <-predict(tree.carseats, newdata = Test.Carseats, type ="class")# Creating Confusion Matrix; calculating test error ratetable(Predicted = pred, Truth)
Truth
Predicted No Yes
No 95 55
Yes 22 42
# Prediction Accuracymean(pred == Truth)
[1] 0.64
# Test error ratemean(pred != Truth)
[1] 0.36
# Now, we prune the Classification Tree, finding the optimum pruning by C.V.cv.carseats <-cv.tree(tree.carseats, FUN = prune.misclass)# Examining the Cross Validation Pruning Tree Objectnames(cv.carseats)
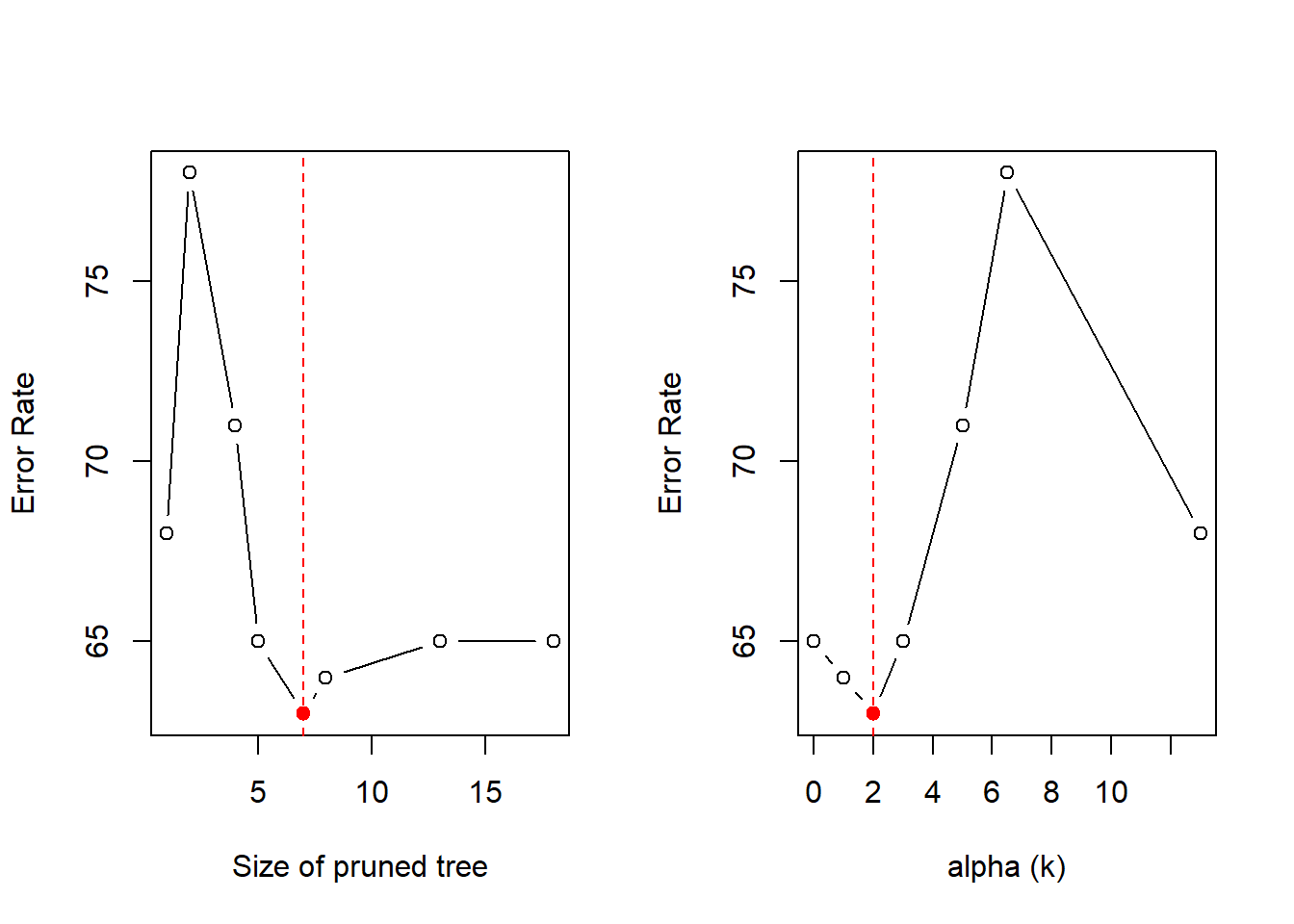
# Plotting the error rate as a fucntion of k (alpha) and size of tree (size)par(mfrow =c(1, 2))plot(x = cv.carseats$size, y = cv.carseats$dev, type ="b",ylab ="Error Rate", xlab ="Size of pruned tree")points(x =7, y =min(cv.carseats$dev), col ="red",pch =20, cex =1.5)abline(v =7, col ="red", lty =2)plot(x = cv.carseats$k, y = cv.carseats$dev, type ="b",ylab ="Error Rate", xlab ="alpha (k)")points(x =2, y =min(cv.carseats$dev), col ="red",pch =20, cex =1.5)abline(v =2, col ="red", lty =2)
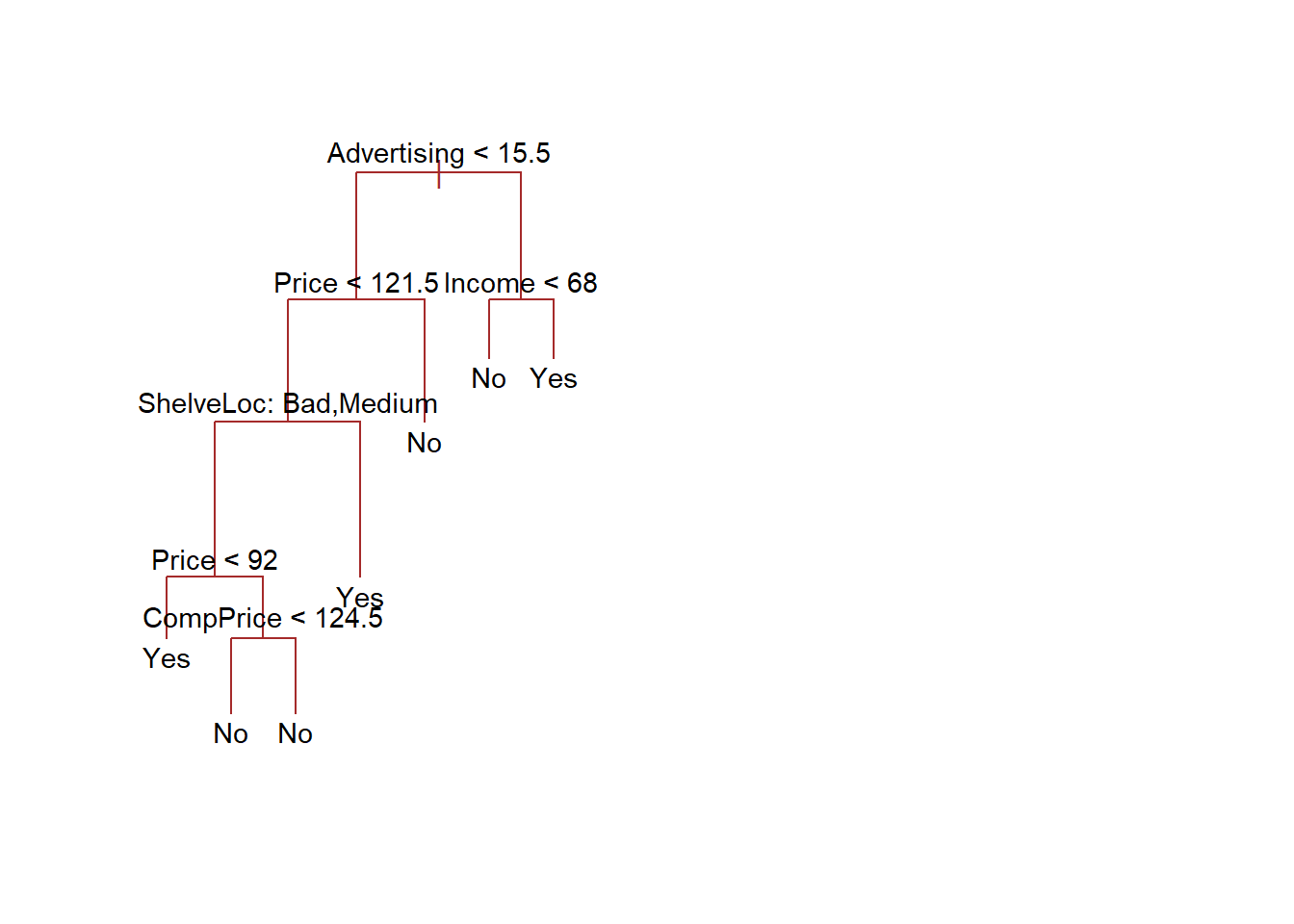
# Pruning the tree at the best number of variables (i.e. 7)prune.carseats <-prune.tree(tree.carseats, best =7)# Plotting the best (as per C.V.) pruned classification treeplot(prune.carseats, col ="brown")text(prune.carseats, cex =0.9, pretty =0)# Calculating the test error rate for the best pruned classification treepred <-predict(prune.carseats, newdata = Test.Carseats, type ="class")table(Predicted = pred, Truth)
Truth
Predicted No Yes
No 107 49
Yes 10 48
# Prediction Accuracymean(pred == Truth)
[1] 0.72
# Test error ratemean(pred != Truth)
[1] 0.28
8.3.2 Fitting Regression Trees
# Loading libraries and data setlibrary(MASS)library(tree)data(Boston)dim(Boston)
[1] 506 14
# creating a training and test subset of the dataset.seed(3)train <-sample(c(TRUE, FALSE), size =nrow(Boston) /2, replace =TRUE)Truth <- Boston[!train, "medv"]# Fitting a regression tree on the training data settree.boston <-tree(medv ~ ., data = Boston, subset = train)# Displaying the fitted regression treesummary(tree.boston)
Regression tree:
tree(formula = medv ~ ., data = Boston, subset = train)
Variables actually used in tree construction:
[1] "lstat" "rm" "nox" "crim"
Number of terminal nodes: 9
Residual mean deviance: 13 = 2910 / 223
Distribution of residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-12.5 -2.0 -0.1 0.0 2.0 15.0
names(tree.boston)
[1] "frame" "where" "terms" "call" "y" "weights"
names(tree.boston$frame)
[1] "var" "n" "dev" "yval" "splits"
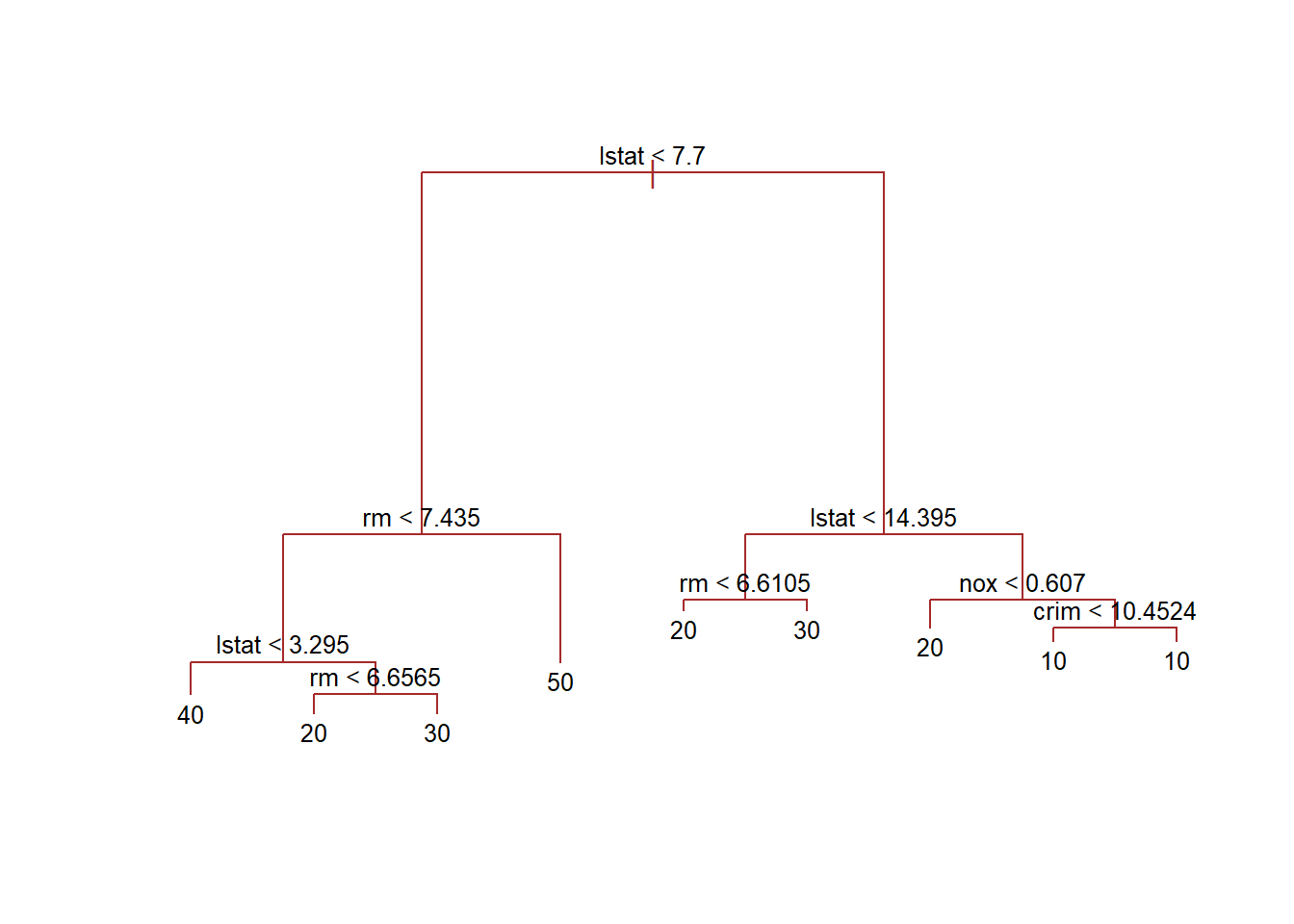
# Plotting the regression treeplot(tree.boston, col ="brown")text(tree.boston, pretty =0, cex =0.8)
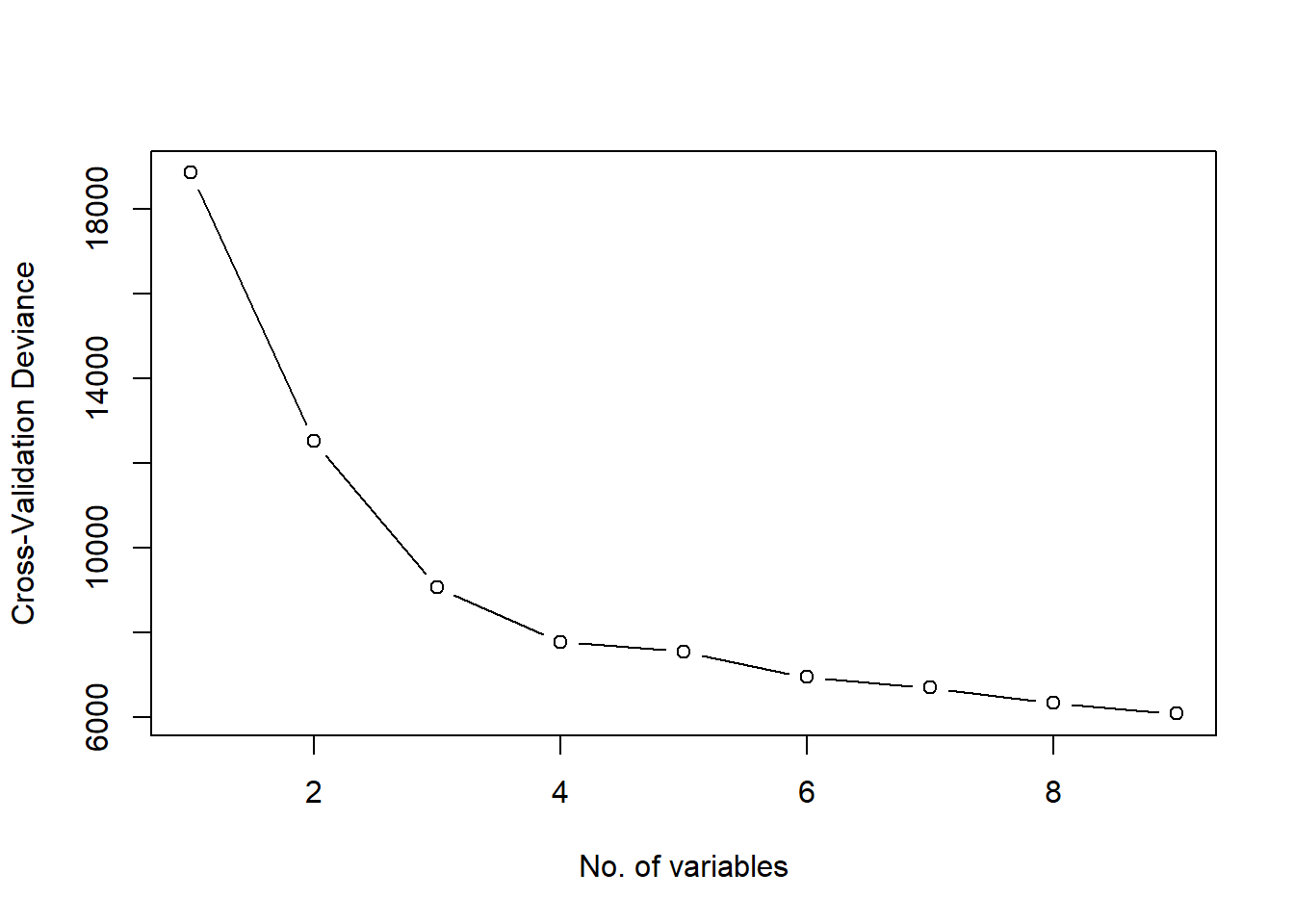
# Finding the best pruned regression tree using cross validationcv.boston <-cv.tree(tree.boston, K =10)cv.boston
plot(x = cv.boston$size, y = cv.boston$dev, xlab ="No. of variables",ylab ="Cross-Validation Deviance", type ="b")
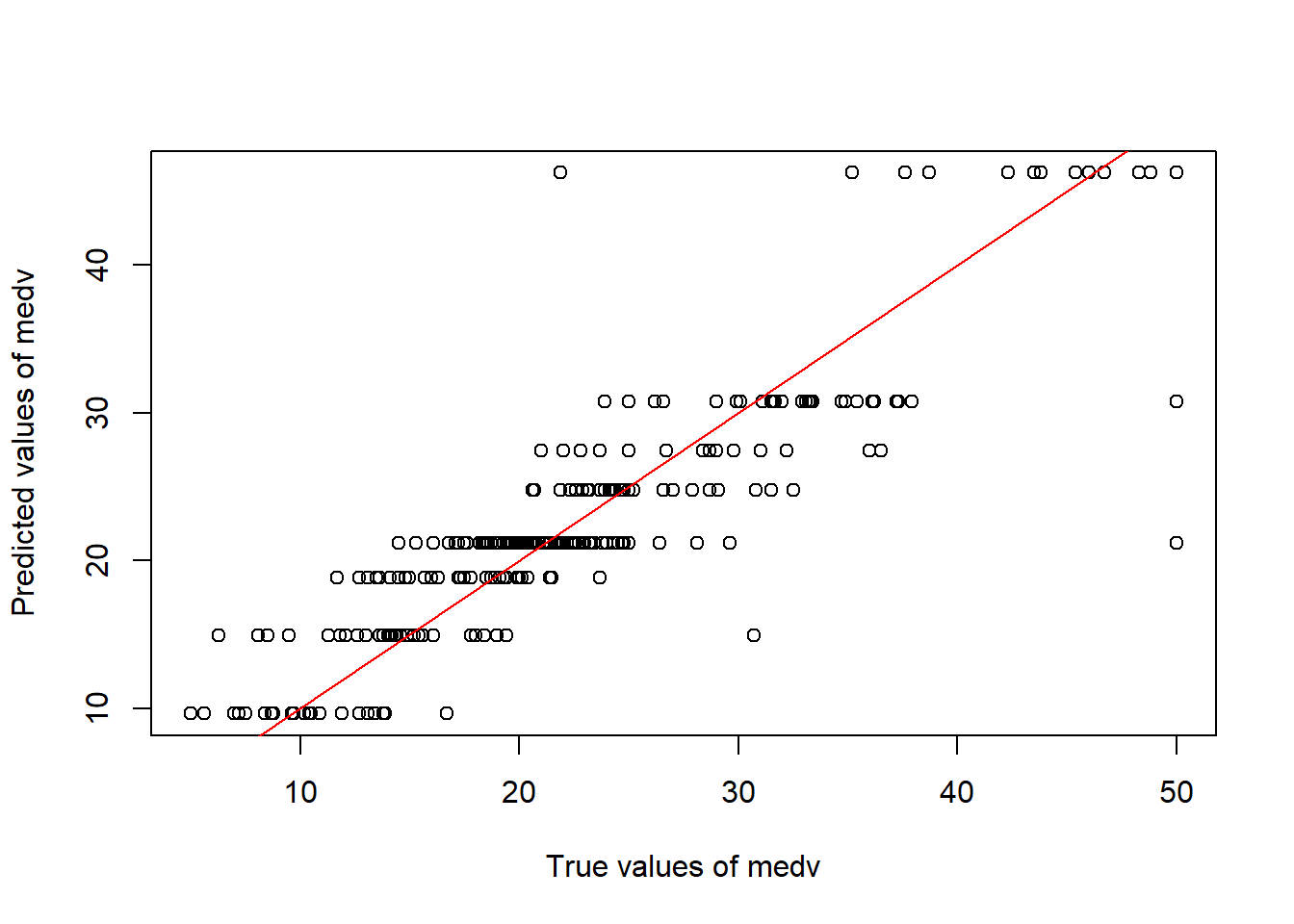
# Using the unpruned tree to make preductions on the test data setpred <-predict(tree.boston, newdata = Boston[!train, ])# Plotting Predicted vs. True values of medvplot(x = Truth, y = pred, xlab ="True values of medv",ylab ="Predicted values of medv")abline(a =0, b =1, col ="red")
# Calculating Test MSEoptions(digits =4)mean((pred - Truth)^2)
[1] 21.18
sqrt(mean((pred - Truth)^2))
[1] 4.602
8.3.3 Bagging and Random Forests
# Loading libraries and Data Setlibrary(MASS)library(randomForest)data(Boston)set.seed(3)# Fitting a bagging model with randomForest() with m = plength(names(Boston))
Call:
randomForest(formula = medv ~ ., data = Boston, mtry = 13, importance = TRUE, subset = train)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 13
Mean of squared residuals: 15.6
% Var explained: 80.71
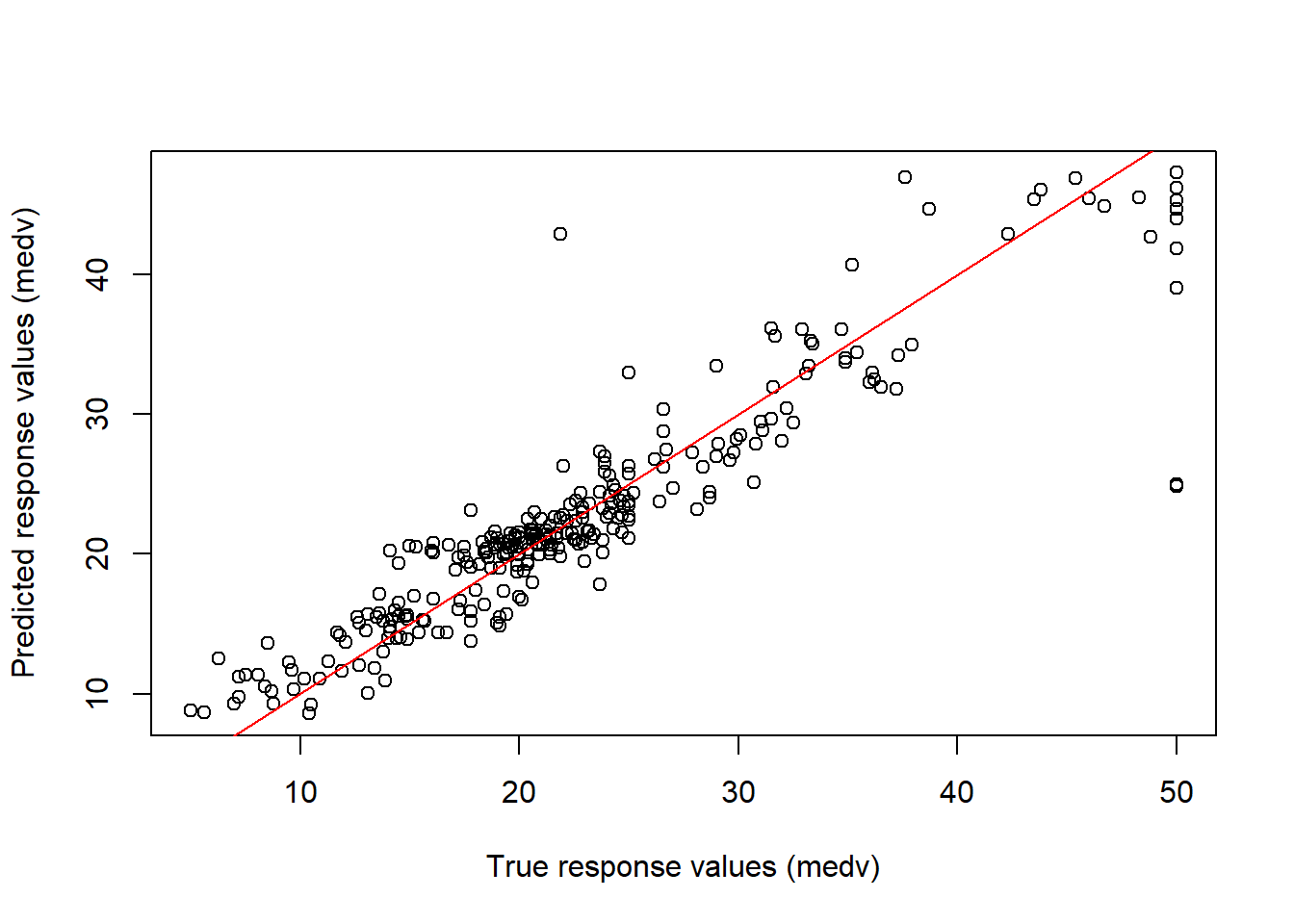
# Calculating test set predictions and plotting thempred <-predict(bag.boston, newdata = Boston[!train, ])plot(x = Truth, y = pred, xlab ="True response values (medv)",ylab ="Predicted response values (medv)")abline(a =0, b =1, col ="red")
# Calculating the Test MSEmean((pred - Truth)^2)
[1] 13.26
# Fitting a Random Forest Model with 6 variables mtryrf.boston <-randomForest(medv ~ .,data = Boston, subset = train,mtry =6, importance =TRUE)rf.boston
Call:
randomForest(formula = medv ~ ., data = Boston, mtry = 6, importance = TRUE, subset = train)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 6
Mean of squared residuals: 13.74
% Var explained: 83.01
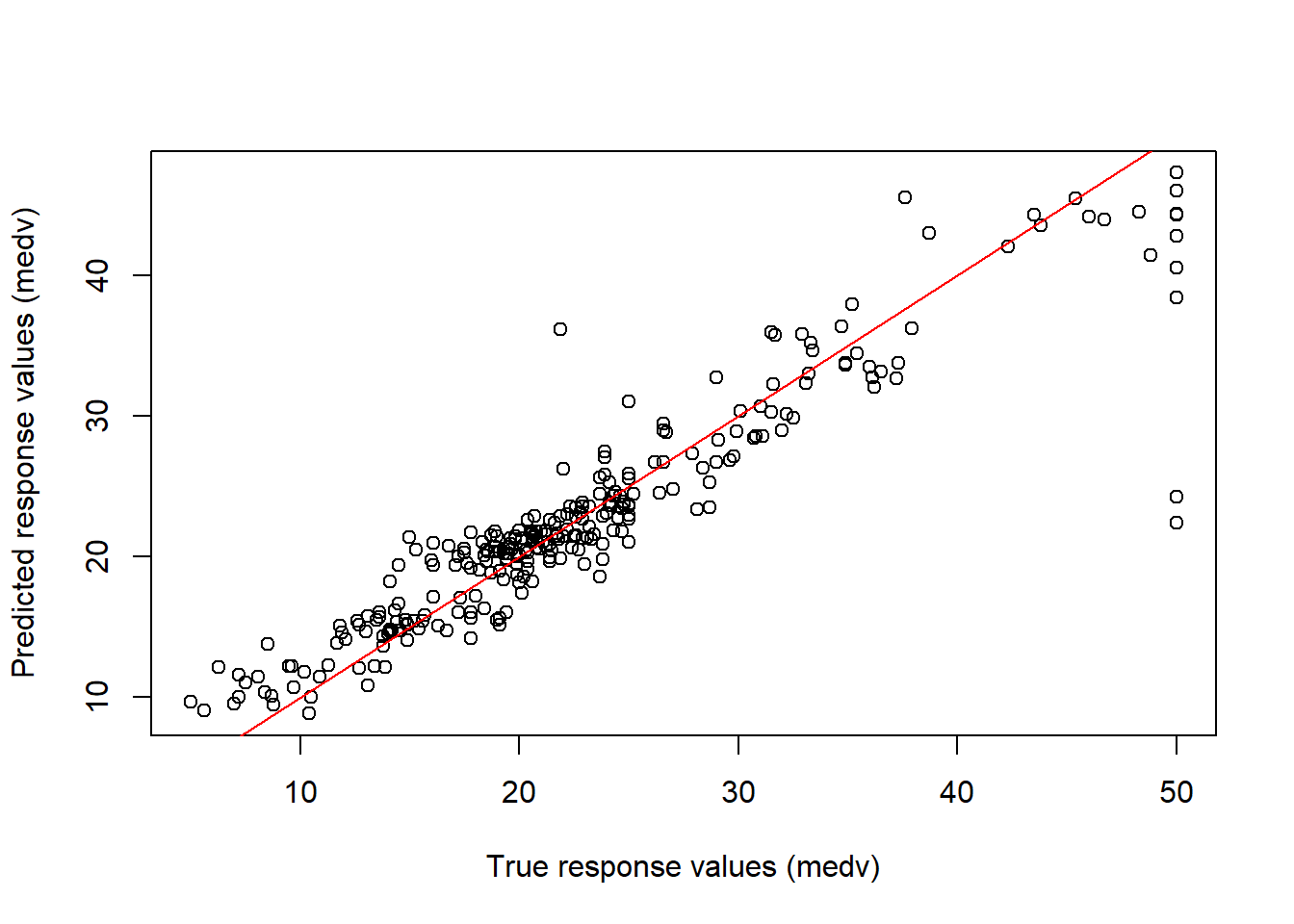
# Calculating test set predictions and plotting thempred <-predict(rf.boston, newdata = Boston[!train, ])plot(x = Truth, y = pred, xlab ="True response values (medv)",ylab ="Predicted response values (medv)")abline(a =0, b =1, col ="red")
# Calculating the Test MSEmean((pred - Truth)^2)
[1] 12.44
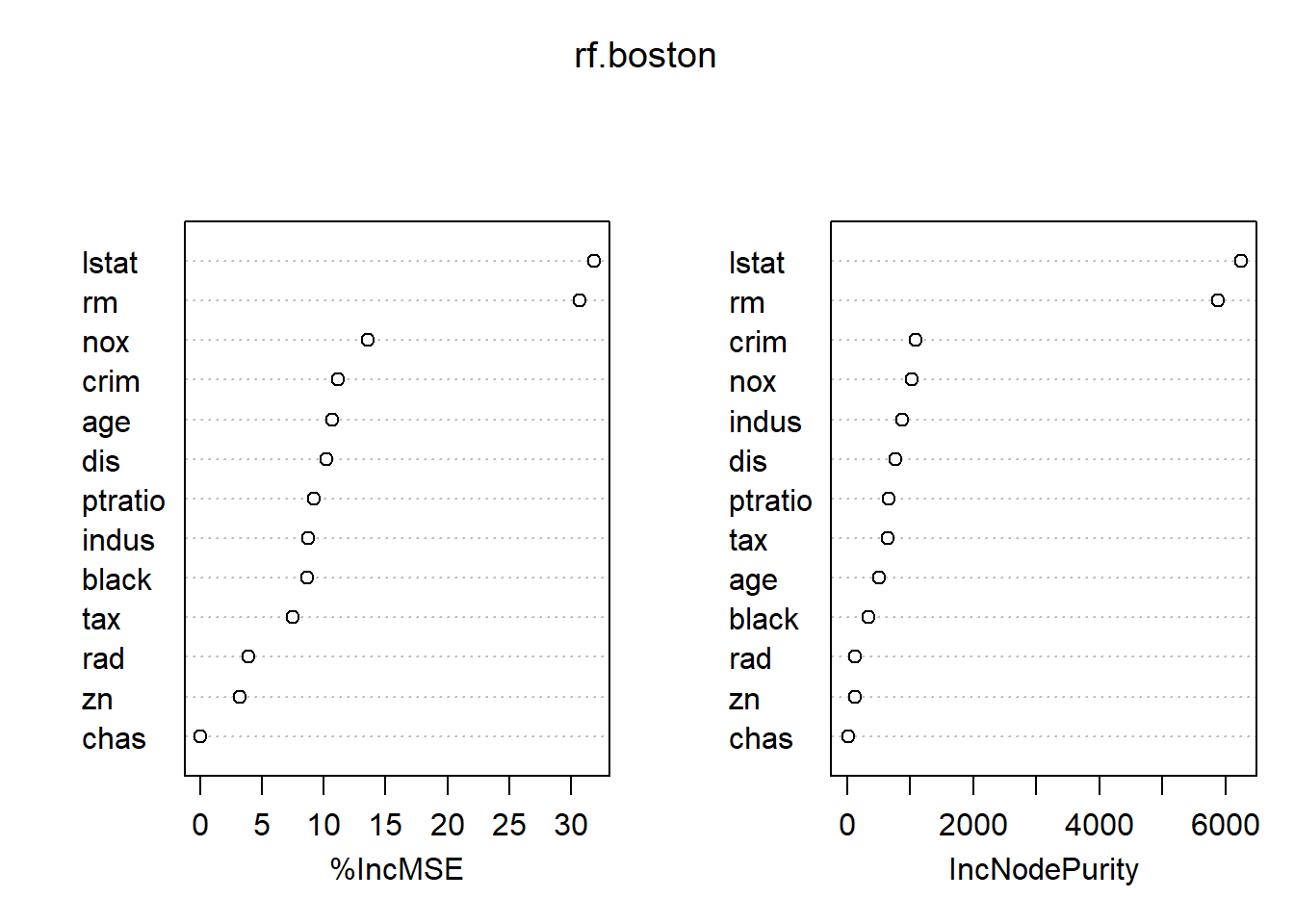
# Showing the importance of variables as table and plotround(importance(rf.boston), 2)
# Loading librarieslibrary(gbm)set.seed(3)# Fitting a boosting modelboost.boston <-gbm(medv ~ ., data = Boston[train, ], distribution ="gaussian",n.trees =5000, interaction.depth =4)boost.boston
gbm(formula = medv ~ ., distribution = "gaussian", data = Boston[train,
], n.trees = 5000, interaction.depth = 4)
A gradient boosted model with gaussian loss function.
5000 iterations were performed.
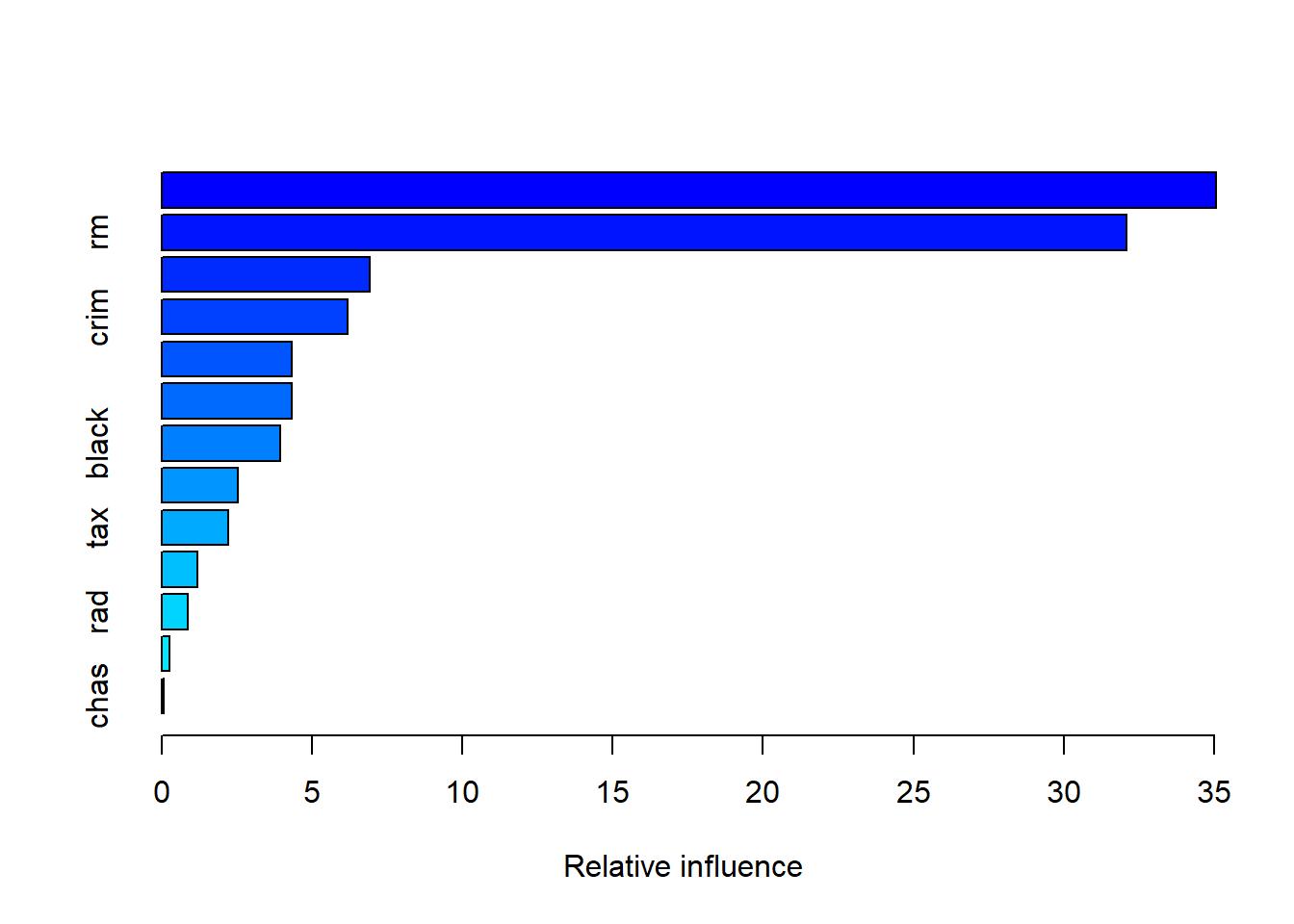
There were 13 predictors of which 13 had non-zero influence.
var rel.inf
lstat lstat 35.06153
rm rm 32.09065
dis dis 6.92124
crim crim 6.19716
nox nox 4.33675
age age 4.31233
black black 3.94817
ptratio ptratio 2.51777
tax tax 2.22554
indus indus 1.18808
rad rad 0.86941
zn zn 0.25900
chas chas 0.07236
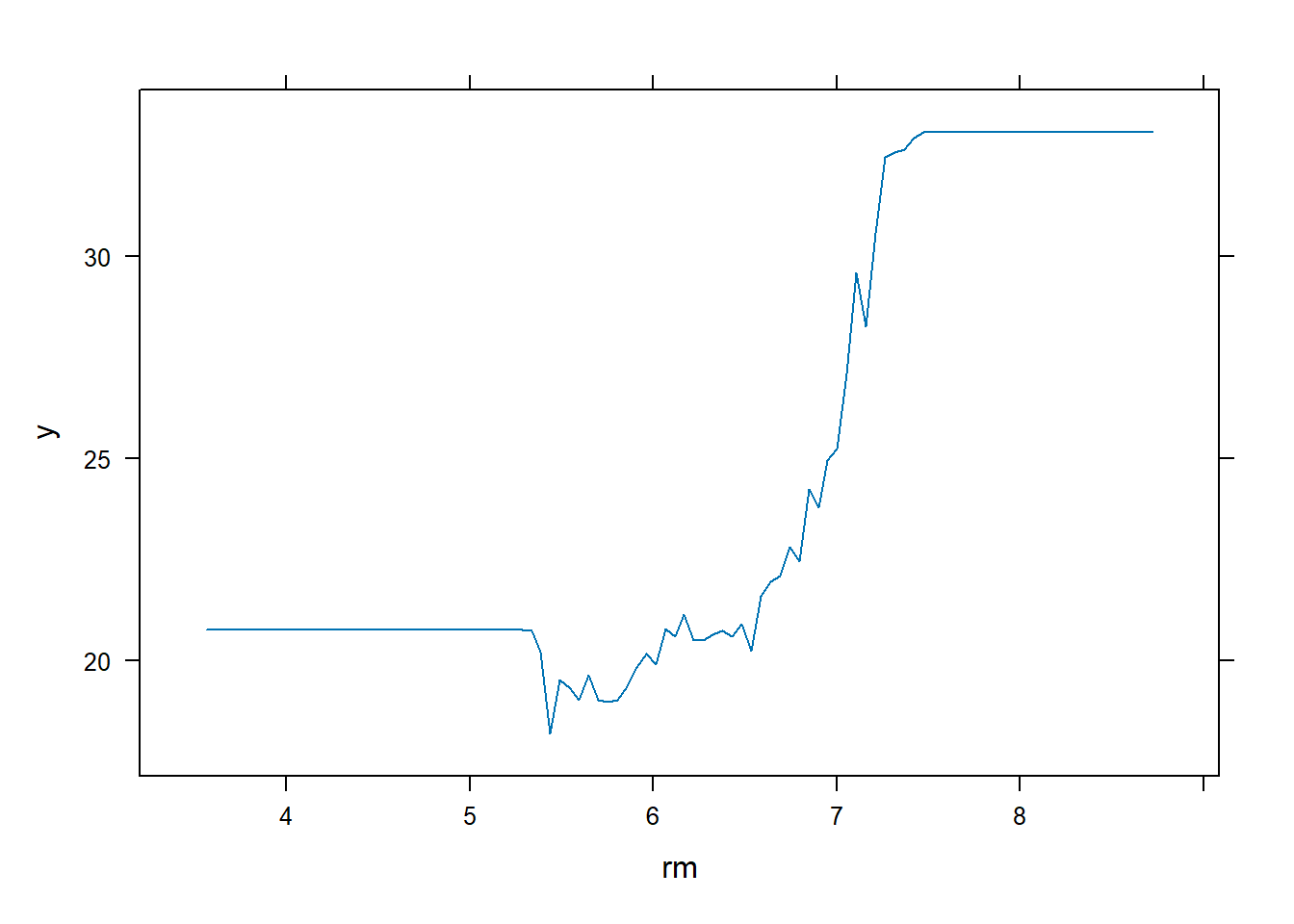
# Plotting the marginal effects of selected variables on the responsepar(mfrow =c(1,2))plot(boost.boston, i ="rm")
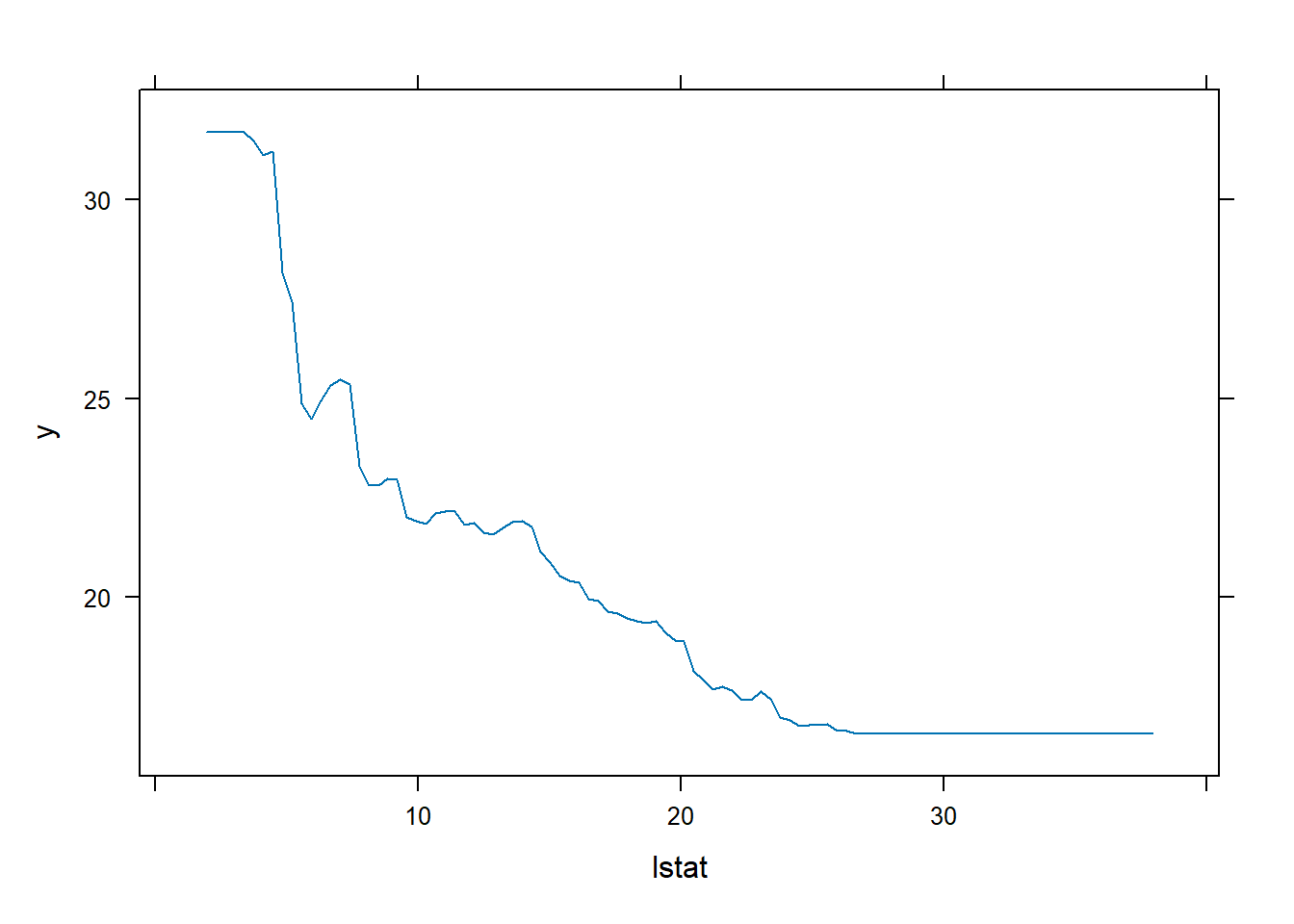
plot(boost.boston, i ="lstat")
# Use boosted model to predict the medv on test data setpred <-predict(boost.boston, newdata = Boston[!train,])# Calculating the test MSEmean((pred - Truth)^2)
[1] 13.89
# Using boosting model with differnt lambda value = 0.2 (instead of default 0.001)boost.boston <-gbm(medv ~ ., data = Boston[train, ], distribution ="gaussian",n.trees =5000, interaction.depth =4, shrinkage =0.2)pred <-predict(boost.boston, newdata = Boston[!train,])mean((pred - Truth)^2)