# Loading required datasets and libraries
library(tidyverse)
library(gt)
library(gtExtras)
library(nycflights13)
library(janitor)
data("flights")
data("weather")
data("airports")Chapter 20
Joins
20.2.4 Exercises
Question 1
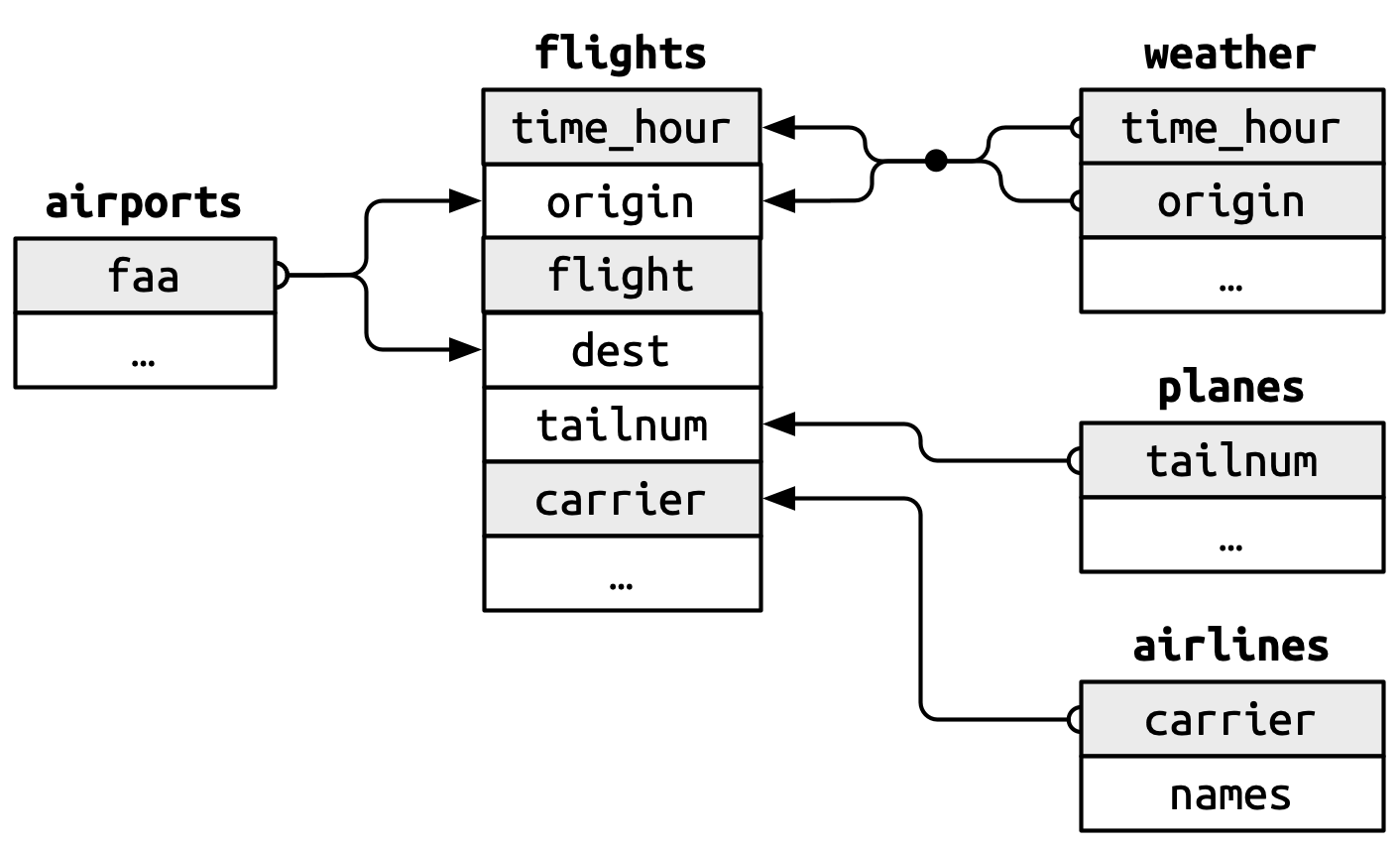
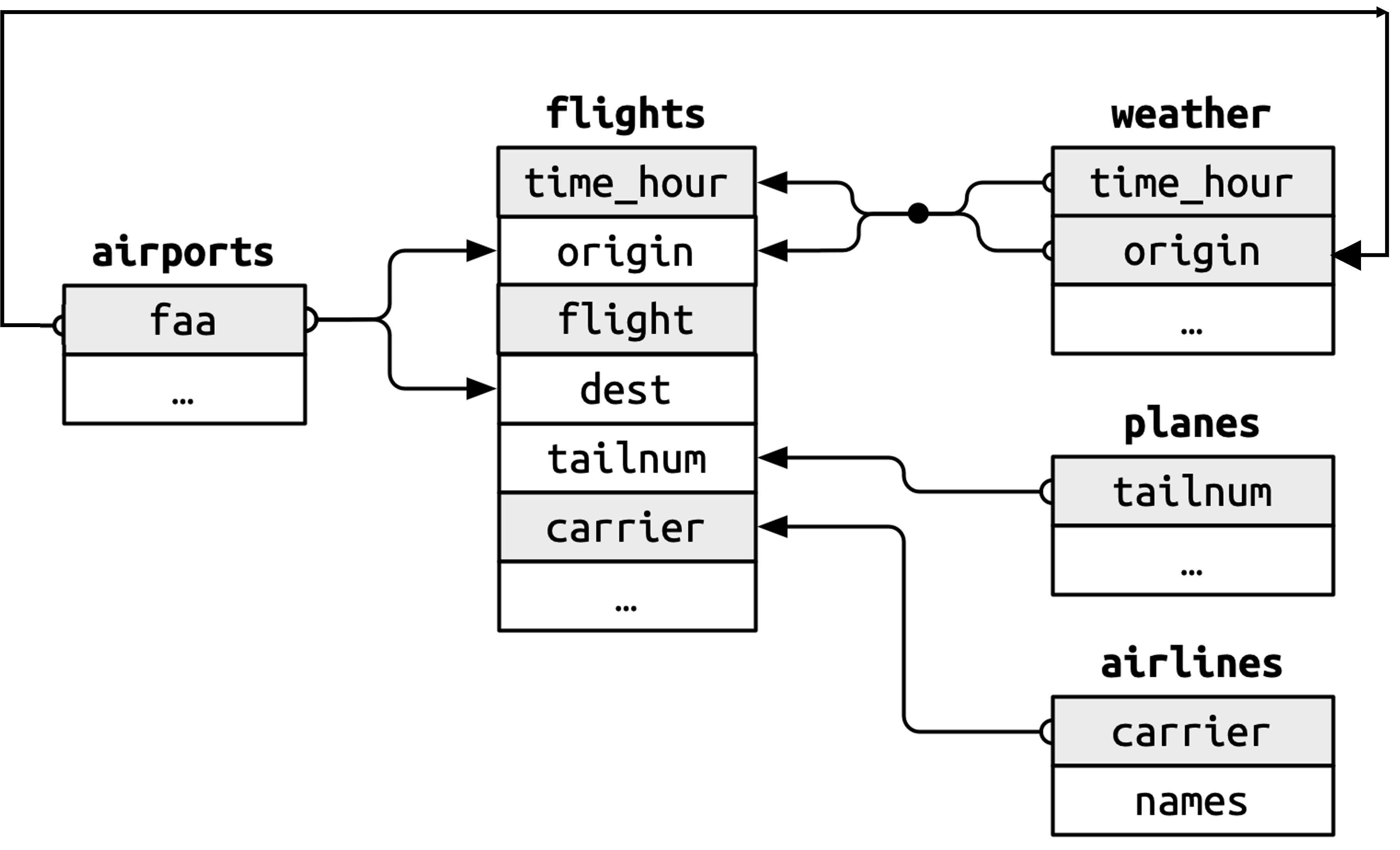
We forgot to draw the relationship between weather and airports in Figure 20.1. What is the relationship and how should it appear in the diagram?
The relation between weather and airports is depicted below in the image adapted and copied from R for Data Science 2(e), Fig 20.1.
{kind=link}
The primary key will be
airports$faa.It corresponds to a compound secondary key,
weather$originandweather$time_hour.
Question 2
weather only contains information for the three origin airports in NYC. If it contained weather records for all airports in the USA, what additional connection would it make to flights?
If weather contained the weather records for all airports in the USA, it would have made an additional connection to the variable dest in the flights dataset.
Question 3
The year, month, day, hour, and origin variables almost form a compound key for weather, but there’s one hour that has duplicate observations. Can you figure out what’s special about that hour?
As we can see in the Table 1 , on November 3, 2013 at 1 am, we have a duplicate weather record. This means that the combination of year, month, day, hour, and origin variables does not form a compound key for weather , since some observations are not unique.
This happens because the daylight savings time clock changed on November 3, 2013 in New York City as follows: –
Start of DST in 2013: Sunday, March 10, 2013 – 1 hour forward - 1 hour is skipped.
End of DST in 2013: Sunday, November 3, 2013 – 1 hour backward at 1 am.
weather |>
group_by(year, month, day, hour, origin) |>
count() |>
filter(n > 1) |>
ungroup() |>
gt() |>
gt_theme_538()| year | month | day | hour | origin | n |
|---|---|---|---|---|---|
| 2013 | 11 | 3 | 1 | EWR | 2 |
| 2013 | 11 | 3 | 1 | JFK | 2 |
| 2013 | 11 | 3 | 1 | LGA | 2 |
Question 4
We know that some days of the year are special and fewer people than usual fly on them (e.g., Christmas eve and Christmas day). How might you represent that data as a data frame? What would be the primary key? How would it connect to the existing data frames?
We can create a data frame or a tibble, as shown in the code below, named holidays to represent holidays and the pre-holiday days.
The primary key would be a compound key of year , month and day. It would connect to the existing data frames using a secondary compound key of of year , month and day.
[Note: to make things easier, without using a compound key, I have used the make_date() function to create a single key flight_date() ]
Code
# Create a tibble for the major holidays in the USA in 2013
holidays <- tibble(
year = 2013,
month = c(1, 2, 5, 7, 9, 10, 11, 12),
day = c(1, 14, 27, 4, 2, 31, 28, 25),
holiday_name = c(
"New Year's Day",
"Valentine's Day",
"Memorial Day",
"Independence Day",
"Labor Day",
"Halloween",
"Thanksgiving",
"Christmas Day"
),
holiday_type = "Holiday"
)
# Computing the pre-holiday date and adding it to holidays
holidays <- bind_rows(
# Exisitng tibble of holidays
holidays,
# A new tibble of holiday eves
holidays |>
mutate(
day = day-1,
holiday_name = str_c(holiday_name, " Eve"),
holiday_type = "Pre-Holiday"
) |>
slice(2:8)
) |>
mutate(flight_date = make_date(year, month, day))
# Display
holidays |>
gt() |>
# cols_label_with(fn = ~ make_clean_names(., case = "title")) |>
gt_theme_nytimes()| year | month | day | holiday_name | holiday_type | flight_date |
|---|---|---|---|---|---|
| 2013 | 1 | 1 | New Year's Day | Holiday | 2013-01-01 |
| 2013 | 2 | 14 | Valentine's Day | Holiday | 2013-02-14 |
| 2013 | 5 | 27 | Memorial Day | Holiday | 2013-05-27 |
| 2013 | 7 | 4 | Independence Day | Holiday | 2013-07-04 |
| 2013 | 9 | 2 | Labor Day | Holiday | 2013-09-02 |
| 2013 | 10 | 31 | Halloween | Holiday | 2013-10-31 |
| 2013 | 11 | 28 | Thanksgiving | Holiday | 2013-11-28 |
| 2013 | 12 | 25 | Christmas Day | Holiday | 2013-12-25 |
| 2013 | 2 | 13 | Valentine's Day Eve | Pre-Holiday | 2013-02-13 |
| 2013 | 5 | 26 | Memorial Day Eve | Pre-Holiday | 2013-05-26 |
| 2013 | 7 | 3 | Independence Day Eve | Pre-Holiday | 2013-07-03 |
| 2013 | 9 | 1 | Labor Day Eve | Pre-Holiday | 2013-09-01 |
| 2013 | 10 | 30 | Halloween Eve | Pre-Holiday | 2013-10-30 |
| 2013 | 11 | 27 | Thanksgiving Eve | Pre-Holiday | 2013-11-27 |
| 2013 | 12 | 24 | Christmas Day Eve | Pre-Holiday | 2013-12-24 |
Now, we can use this new tibble, join it with our existing data sets and try to figure out whether there is any difference in number of flights on holidays, and pre-holidays, vs. the rest of the days. The results are in Figure 1 .
Code
# A tibble on the number of flights each day, along with whether each day
# is holiday or not; and if yes, which holiday
nos_flights <- flights |>
mutate(flight_date = make_date(year, month, day)) |>
left_join(holidays) |>
group_by(flight_date, holiday_type, holiday_name) |>
count()
nos_flights |>
group_by(holiday_type) |>
summarize(avg_flights = mean(n)) |>
mutate(holiday_type = if_else(is.na(holiday_type),
"Other Days",
holiday_type)) |>
ggplot(aes(x = avg_flights,
y = reorder(holiday_type, avg_flights))) +
geom_bar(stat = "identity", fill = "grey") +
theme_minimal() +
theme(panel.grid = element_blank()) +
labs(y = NULL, x = "Average Number of flights (per day)",
title = "Holidays / pre-holiday have lower number of flights, on average") +
theme(plot.title.position = "plot")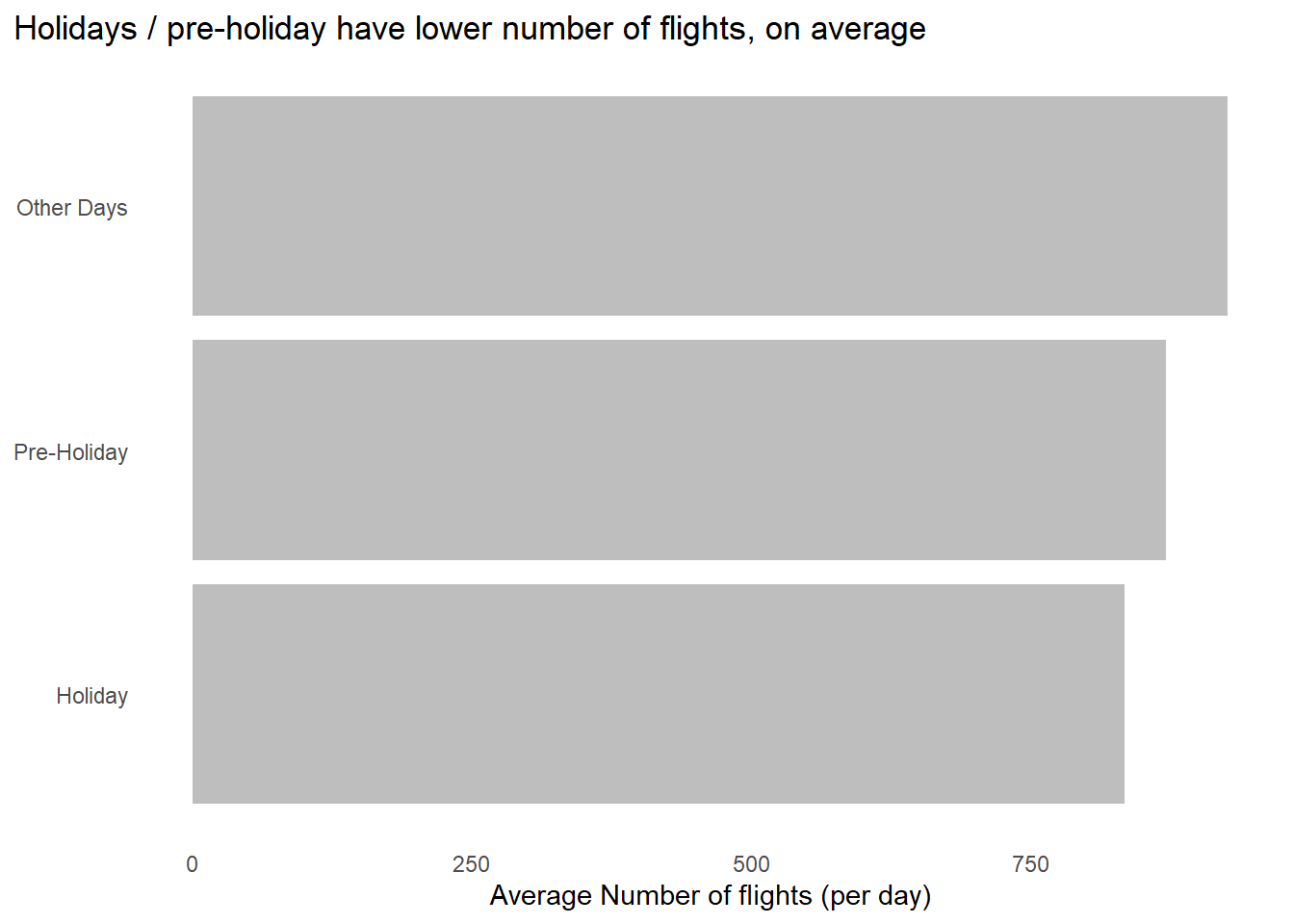
The number of flights on various holidays and pre-holiday days is shown in Figure 2 .
Code
nos_flights |>
group_by(holiday_name) |>
summarize(avg_flights = mean(n)) |>
mutate(holiday_name = if_else(is.na(holiday_name),
"Other Days",
holiday_name)) |>
mutate(col_var = holiday_name == "Other Days") |>
ggplot(aes(x = avg_flights,
y = reorder(holiday_name, avg_flights),
fill = col_var,
label = round(avg_flights, 0))) +
geom_bar(stat = "identity") +
geom_text(nudge_x = 20, size = 3) +
theme_minimal() +
theme(panel.grid = element_blank(),
plot.title.position = "plot",
legend.position = "none") +
labs(y = NULL, x = "Number of flights (per day)") +
scale_fill_brewer(palette = "Paired") +
coord_cartesian(xlim = c(500, 1050))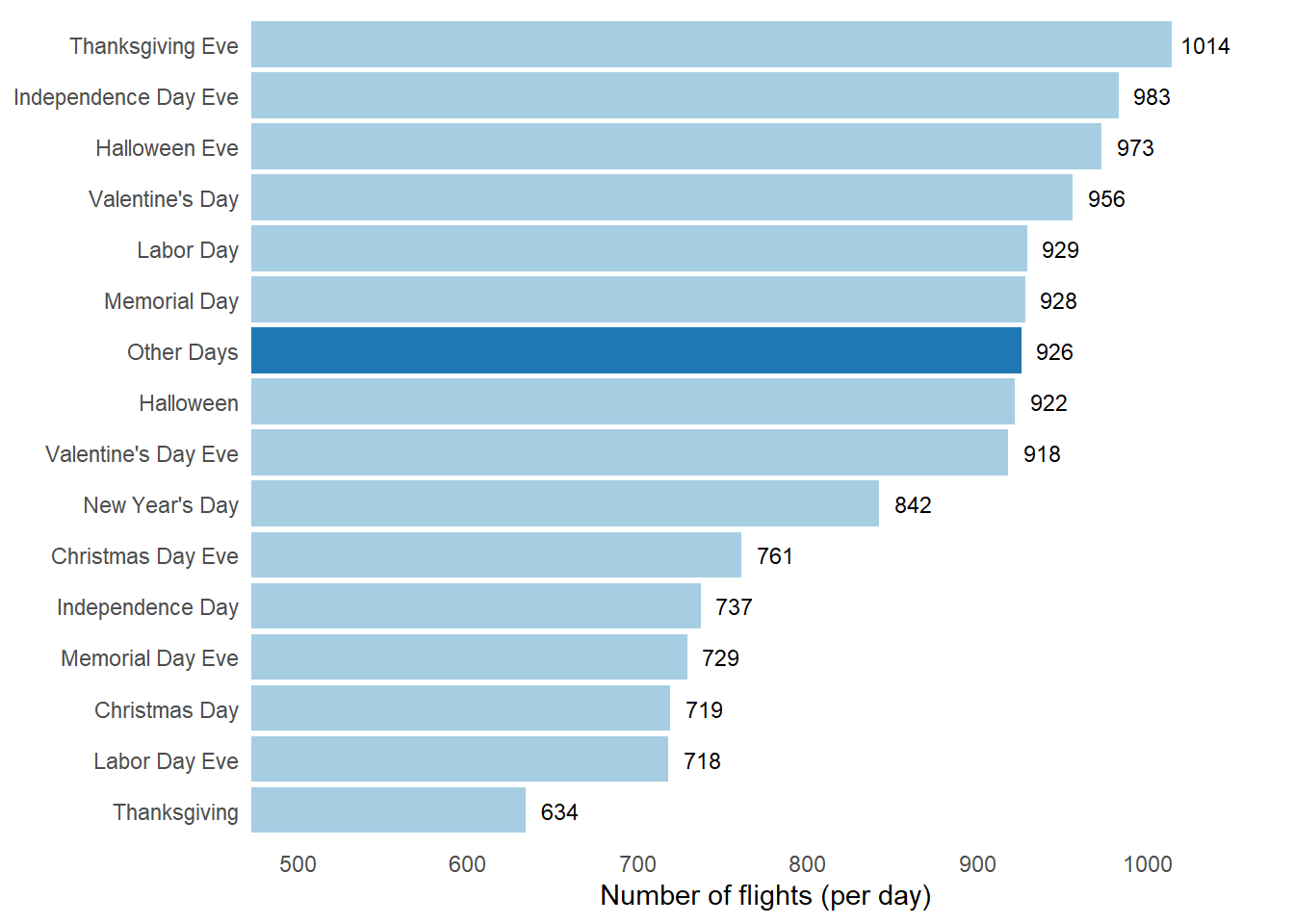
Question 5
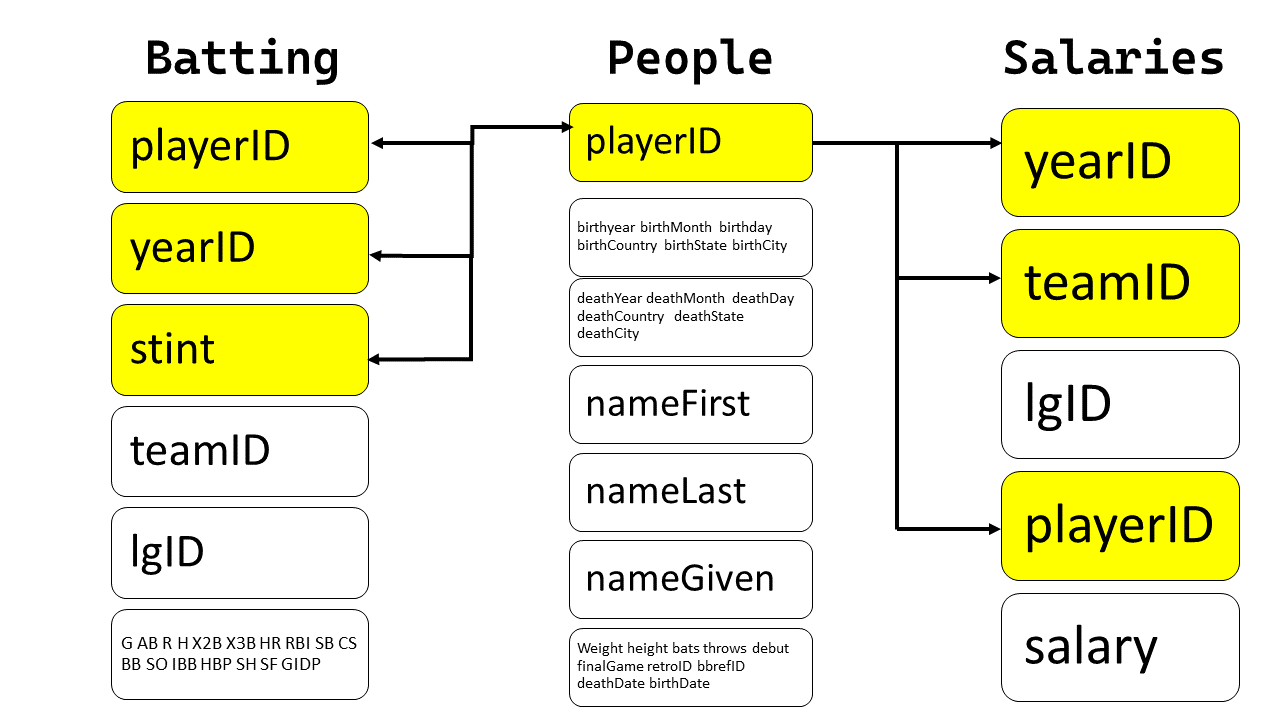
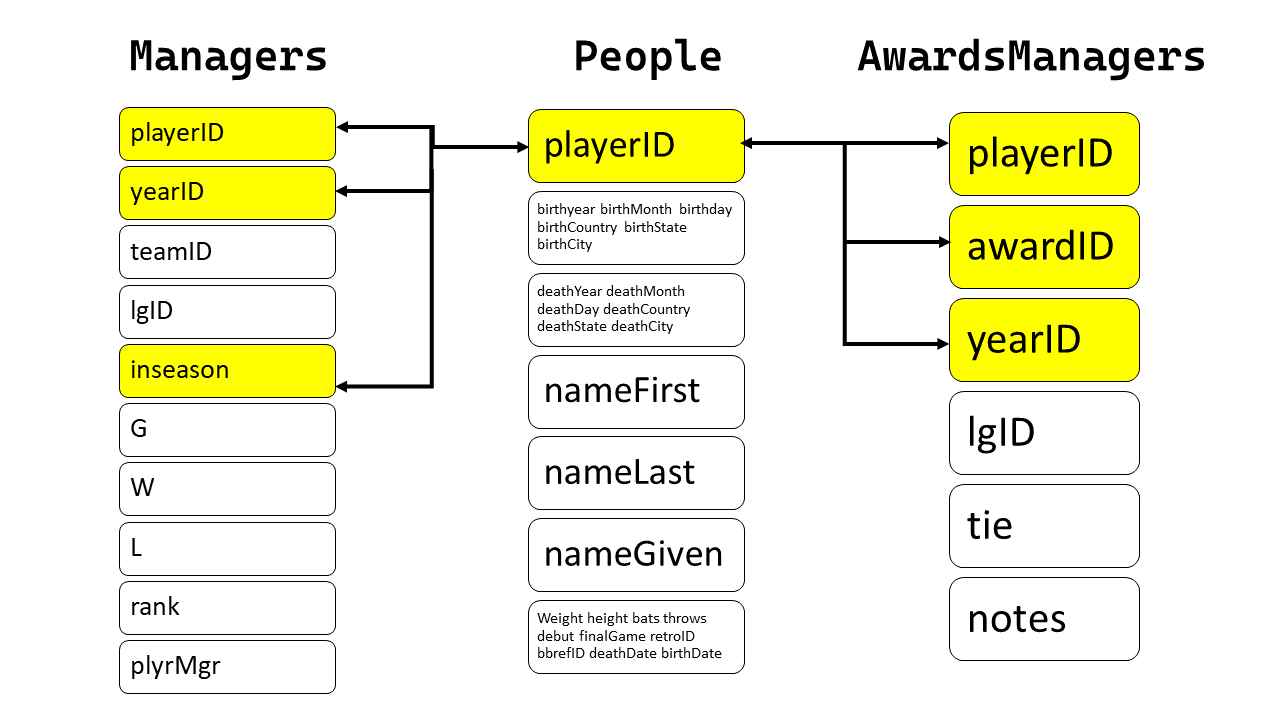
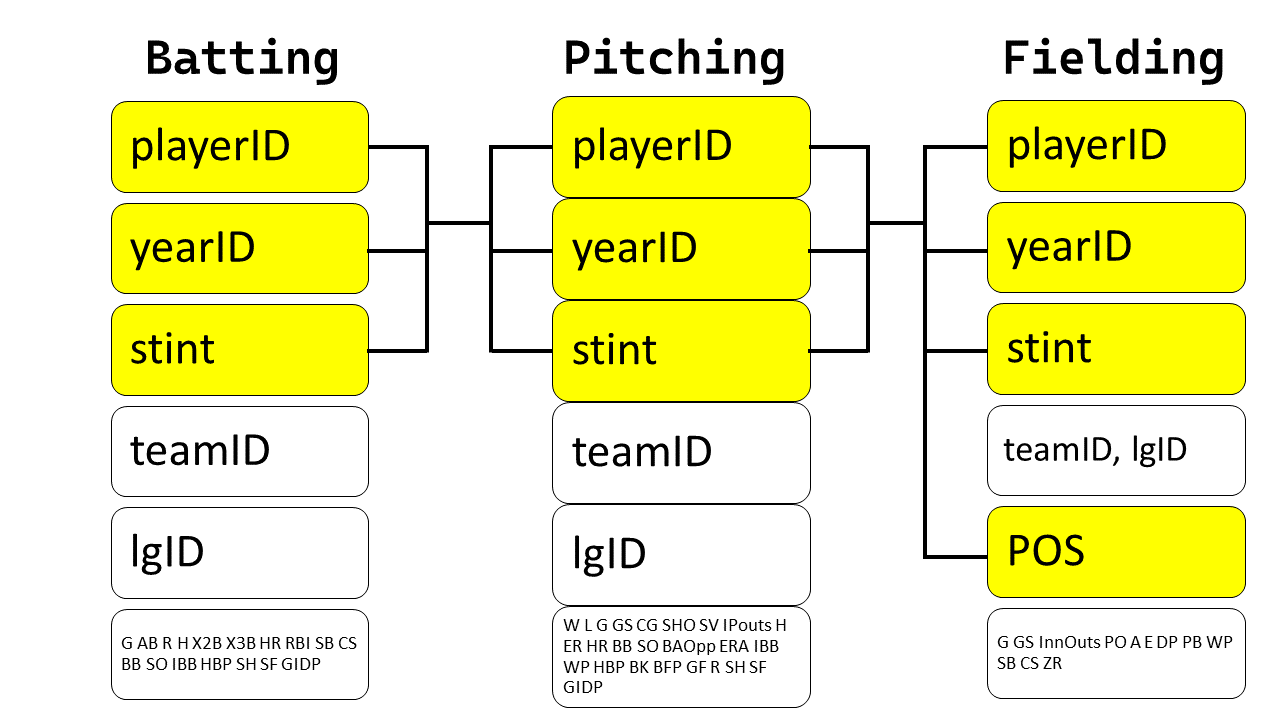
Draw a diagram illustrating the connections between the Batting, People, and Salaries data frames in the Lahman package. Draw another diagram that shows the relationship between People, Managers, AwardsManagers. How would you characterize the relationship between the Batting, Pitching, and Fielding data frames?
The data-frames are shown below, alongwith the check that playerID is a key: –
In Batting , the variables playerID , yearID and stint form a compound key.
library(Lahman)
Batting |> as_tibble() |>
group_by(playerID, yearID, stint) |>
count() |>
filter(n > 1)# A tibble: 0 × 4
# Groups: playerID, yearID, stint [0]
# ℹ 4 variables: playerID <chr>, yearID <int>, stint <int>, n <int>head(Batting) |> tibble() |>
gt() |> gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, stint))
) |>
tab_header(title = md("**`Batting`**"))Batting |
|||||||||||||||||||||
| playerID | yearID | stint | teamID | lgID | G | AB | R | H | X2B | X3B | HR | RBI | SB | CS | BB | SO | IBB | HBP | SH | SF | GIDP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| abercda01 | 1871 | 1 | TRO | NA | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NA | NA | NA | NA | 0 |
| addybo01 | 1871 | 1 | RC1 | NA | 25 | 118 | 30 | 32 | 6 | 0 | 0 | 13 | 8 | 1 | 4 | 0 | NA | NA | NA | NA | 0 |
| allisar01 | 1871 | 1 | CL1 | NA | 29 | 137 | 28 | 40 | 4 | 5 | 0 | 19 | 3 | 1 | 2 | 5 | NA | NA | NA | NA | 1 |
| allisdo01 | 1871 | 1 | WS3 | NA | 27 | 133 | 28 | 44 | 10 | 2 | 2 | 27 | 1 | 1 | 0 | 2 | NA | NA | NA | NA | 0 |
| ansonca01 | 1871 | 1 | RC1 | NA | 25 | 120 | 29 | 39 | 11 | 3 | 0 | 16 | 6 | 2 | 2 | 1 | NA | NA | NA | NA | 0 |
| armstbo01 | 1871 | 1 | FW1 | NA | 12 | 49 | 9 | 11 | 2 | 1 | 0 | 5 | 0 | 1 | 0 | 1 | NA | NA | NA | NA | 0 |
In People, the variable playerID is unique for each observation, and hence a primary key.
People |>
as_tibble() |>
group_by(playerID) |>
count() |>
filter(n > 1)# A tibble: 0 × 2
# Groups: playerID [0]
# ℹ 2 variables: playerID <chr>, n <int>head(People) |> tibble() |>
gt() |> gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID))
) |>
tab_header(title = md("**`People`**"))People |
|||||||||||||||||||||||||
| playerID | birthYear | birthMonth | birthDay | birthCountry | birthState | birthCity | deathYear | deathMonth | deathDay | deathCountry | deathState | deathCity | nameFirst | nameLast | nameGiven | weight | height | bats | throws | debut | finalGame | retroID | bbrefID | deathDate | birthDate |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| aardsda01 | 1981 | 12 | 27 | USA | CO | Denver | NA | NA | NA | NA | NA | NA | David | Aardsma | David Allan | 215 | 75 | R | R | 2004-04-06 | 2015-08-23 | aardd001 | aardsda01 | NA | 1981-12-27 |
| aaronha01 | 1934 | 2 | 5 | USA | AL | Mobile | 2021 | 1 | 22 | USA | GA | Atlanta | Hank | Aaron | Henry Louis | 180 | 72 | R | R | 1954-04-13 | 1976-10-03 | aaroh101 | aaronha01 | 2021-01-22 | 1934-02-05 |
| aaronto01 | 1939 | 8 | 5 | USA | AL | Mobile | 1984 | 8 | 16 | USA | GA | Atlanta | Tommie | Aaron | Tommie Lee | 190 | 75 | R | R | 1962-04-10 | 1971-09-26 | aarot101 | aaronto01 | 1984-08-16 | 1939-08-05 |
| aasedo01 | 1954 | 9 | 8 | USA | CA | Orange | NA | NA | NA | NA | NA | NA | Don | Aase | Donald William | 190 | 75 | R | R | 1977-07-26 | 1990-10-03 | aased001 | aasedo01 | NA | 1954-09-08 |
| abadan01 | 1972 | 8 | 25 | USA | FL | Palm Beach | NA | NA | NA | NA | NA | NA | Andy | Abad | Fausto Andres | 184 | 73 | L | L | 2001-09-10 | 2006-04-13 | abada001 | abadan01 | NA | 1972-08-25 |
| abadfe01 | 1985 | 12 | 17 | D.R. | La Romana | La Romana | NA | NA | NA | NA | NA | NA | Fernando | Abad | Fernando Antonio | 235 | 74 | L | L | 2010-07-28 | 2021-10-01 | abadf001 | abadfe01 | NA | 1985-12-17 |
In Salaries the variables playerID , yearID and stint form a compound key.
Salaries |>
as_tibble() |>
group_by(playerID, yearID, teamID) |>
count() |>
filter(n > 1)# A tibble: 0 × 4
# Groups: playerID, yearID, teamID [0]
# ℹ 4 variables: playerID <chr>, yearID <int>, teamID <fct>, n <int>head(Salaries) |> tibble() |>
gt() |> gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, teamID))
)|>
tab_header(title = md("**`Salaries`**"))Salaries |
||||
| yearID | teamID | lgID | playerID | salary |
|---|---|---|---|---|
| 1985 | ATL | NL | barkele01 | 870000 |
| 1985 | ATL | NL | bedrost01 | 550000 |
| 1985 | ATL | NL | benedbr01 | 545000 |
| 1985 | ATL | NL | campri01 | 633333 |
| 1985 | ATL | NL | ceronri01 | 625000 |
| 1985 | ATL | NL | chambch01 | 800000 |
The diagram illustrating the connections is shown below: –
Now, we show another diagram that shows the relationship between People, Managers, AwardsManagers.
For Managers, the key is a compound key of playerID, yearID and inseason
head(Managers) playerID yearID teamID lgID inseason G W L rank plyrMgr
1 wrighha01 1871 BS1 NA 1 31 20 10 3 Y
2 woodji01 1871 CH1 NA 1 28 19 9 2 Y
3 paborch01 1871 CL1 NA 1 29 10 19 8 Y
4 lennobi01 1871 FW1 NA 1 14 5 9 8 Y
5 deaneha01 1871 FW1 NA 2 5 2 3 8 Y
6 fergubo01 1871 NY2 NA 1 33 16 17 5 YManagers |>
as_tibble() |>
group_by(playerID, yearID, inseason) |>
count() |>
filter(n > 1)# A tibble: 0 × 4
# Groups: playerID, yearID, inseason [0]
# ℹ 4 variables: playerID <chr>, yearID <int>, inseason <int>, n <int>head(Managers) |> as_tibble() |>
gt() |>
gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, inseason))
) |>
tab_header(title = md("**`Managers`**"))Managers |
|||||||||
| playerID | yearID | teamID | lgID | inseason | G | W | L | rank | plyrMgr |
|---|---|---|---|---|---|---|---|---|---|
| wrighha01 | 1871 | BS1 | NA | 1 | 31 | 20 | 10 | 3 | Y |
| woodji01 | 1871 | CH1 | NA | 1 | 28 | 19 | 9 | 2 | Y |
| paborch01 | 1871 | CL1 | NA | 1 | 29 | 10 | 19 | 8 | Y |
| lennobi01 | 1871 | FW1 | NA | 1 | 14 | 5 | 9 | 8 | Y |
| deaneha01 | 1871 | FW1 | NA | 2 | 5 | 2 | 3 | 8 | Y |
| fergubo01 | 1871 | NY2 | NA | 1 | 33 | 16 | 17 | 5 | Y |
For AwardsManagers , the primary key is a compound key of playerID , awardID and yearID .
head(AwardsManagers) playerID awardID yearID lgID tie notes
1 larusto01 BBWAA Manager of the Year 1983 AL <NA> NA
2 lasorto01 BBWAA Manager of the Year 1983 NL <NA> NA
3 andersp01 BBWAA Manager of the Year 1984 AL <NA> NA
4 freyji99 BBWAA Manager of the Year 1984 NL <NA> NA
5 coxbo01 BBWAA Manager of the Year 1985 AL <NA> NA
6 herzowh01 BBWAA Manager of the Year 1985 NL <NA> NAAwardsManagers |>
as_tibble() |>
group_by(playerID, awardID, yearID) |>
count() |>
filter(n > 1)# A tibble: 0 × 4
# Groups: playerID, awardID, yearID [0]
# ℹ 4 variables: playerID <chr>, awardID <chr>, yearID <int>, n <int>head(AwardsManagers) |> as_tibble() |>
gt() |>
gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, awardID))
) |>
tab_header(title = md("**`AwardsManagers`**"))AwardsManagers |
|||||
| playerID | awardID | yearID | lgID | tie | notes |
|---|---|---|---|---|---|
| larusto01 | BBWAA Manager of the Year | 1983 | AL | NA | NA |
| lasorto01 | BBWAA Manager of the Year | 1983 | NL | NA | NA |
| andersp01 | BBWAA Manager of the Year | 1984 | AL | NA | NA |
| freyji99 | BBWAA Manager of the Year | 1984 | NL | NA | NA |
| coxbo01 | BBWAA Manager of the Year | 1985 | AL | NA | NA |
| herzowh01 | BBWAA Manager of the Year | 1985 | NL | NA | NA |
Hence, the relationship between People, Managers, AwardsManagers is as follows: –
Now, let’s try to characterize the relationship between Batting , Pitching and Fielding.
Pitching |> as_tibble() |>
group_by(playerID, yearID, stint) |>
count() |>
filter(n > 1)# A tibble: 0 × 4
# Groups: playerID, yearID, stint [0]
# ℹ 4 variables: playerID <chr>, yearID <int>, stint <int>, n <int>head(Pitching) |> as_tibble() |>
gt() |>
gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, stint))
) |>
tab_header(title = md("**`Pitching`**"))Pitching |
|||||||||||||||||||||||||||||
| playerID | yearID | stint | teamID | lgID | W | L | G | GS | CG | SHO | SV | IPouts | H | ER | HR | BB | SO | BAOpp | ERA | IBB | WP | HBP | BK | BFP | GF | R | SH | SF | GIDP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bechtge01 | 1871 | 1 | PH1 | NA | 1 | 2 | 3 | 3 | 2 | 0 | 0 | 78 | 43 | 23 | 0 | 11 | 1 | NA | 7.96 | NA | 7 | NA | 0 | 146 | 0 | 42 | NA | NA | NA |
| brainas01 | 1871 | 1 | WS3 | NA | 12 | 15 | 30 | 30 | 30 | 0 | 0 | 792 | 361 | 132 | 4 | 37 | 13 | NA | 4.50 | NA | 7 | NA | 0 | 1291 | 0 | 292 | NA | NA | NA |
| fergubo01 | 1871 | 1 | NY2 | NA | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 8 | 3 | 0 | 0 | 0 | NA | 27.00 | NA | 2 | NA | 0 | 14 | 0 | 9 | NA | NA | NA |
| fishech01 | 1871 | 1 | RC1 | NA | 4 | 16 | 24 | 24 | 22 | 1 | 0 | 639 | 295 | 103 | 3 | 31 | 15 | NA | 4.35 | NA | 20 | NA | 0 | 1080 | 1 | 257 | NA | NA | NA |
| fleetfr01 | 1871 | 1 | NY2 | NA | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 27 | 20 | 10 | 0 | 3 | 0 | NA | 10.00 | NA | 0 | NA | 0 | 57 | 0 | 21 | NA | NA | NA |
| flowedi01 | 1871 | 1 | TRO | NA | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | NA | 0.00 | NA | 0 | NA | 0 | 3 | 1 | 0 | NA | NA | NA |
In the Fielding dataset, the primary key is a compound key comprised of playerID , yearID , stint and POS.
Fielding |> as_tibble() |>
group_by(playerID, yearID, stint, POS) |>
count() |>
filter(n > 1)# A tibble: 0 × 5
# Groups: playerID, yearID, stint, POS [0]
# ℹ 5 variables: playerID <chr>, yearID <int>, stint <int>, POS <chr>, n <int>head(Fielding) |> as_tibble() |>
gt() |>
gt_theme_538() |>
tab_style(
style = list(cell_fill(color = "yellow"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(playerID, yearID, stint, POS))
) |>
tab_header(title = md("**`Fielding`**"))Fielding |
|||||||||||||||||
| playerID | yearID | stint | teamID | lgID | POS | G | GS | InnOuts | PO | A | E | DP | PB | WP | SB | CS | ZR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| abercda01 | 1871 | 1 | TRO | NA | SS | 1 | 1 | 24 | 1 | 3 | 2 | 0 | NA | NA | NA | NA | NA |
| addybo01 | 1871 | 1 | RC1 | NA | 2B | 22 | 22 | 606 | 67 | 72 | 42 | 5 | NA | NA | NA | NA | NA |
| addybo01 | 1871 | 1 | RC1 | NA | SS | 3 | 3 | 96 | 8 | 14 | 7 | 0 | NA | NA | NA | NA | NA |
| allisar01 | 1871 | 1 | CL1 | NA | 2B | 2 | 0 | 18 | 1 | 4 | 0 | 0 | NA | NA | NA | NA | NA |
| allisar01 | 1871 | 1 | CL1 | NA | OF | 29 | 29 | 729 | 51 | 3 | 7 | 1 | NA | NA | NA | NA | NA |
| allisdo01 | 1871 | 1 | WS3 | NA | C | 27 | 27 | 681 | 68 | 15 | 20 | 4 | 18 | NA | 0 | 0 | NA |
Thus, the relationship between the Batting, Pitching, and Fielding data frames is as follows: –
20.3.4 Exercises
Question 1
Find the 48 hours (over the course of the whole year) that have the worst delays. Cross-reference it with the weather data. Can you see any patterns?
First, we find out the 48 hours (over the course of the whole year) that have the worst delays. As we can see in Figure 3 , these are quite similar across the 3 origin airports, for which we have the weather data.
Code
# Create a dataframe of 48 hours with highestaverage delays
# (for each of the 3 origin airports)
delayhours = flights |>
group_by(origin, time_hour) |>
summarize(avg_delay = mean(dep_delay, na.rm = TRUE)) |>
arrange(desc(avg_delay), .by_group = TRUE) |>
slice_head(n = 48) |>
arrange(time_hour)
delayhours |>
ggplot(aes(y = time_hour, x = avg_delay)) +
geom_point(size = 2, alpha = 0.5) +
facet_wrap(~origin, dir = "h") +
theme_minimal() +
labs(x = "Average delay during the hour (in mins.)", y = NULL,
title = "The worst 48 hours for departure delays are similar across 3 airports")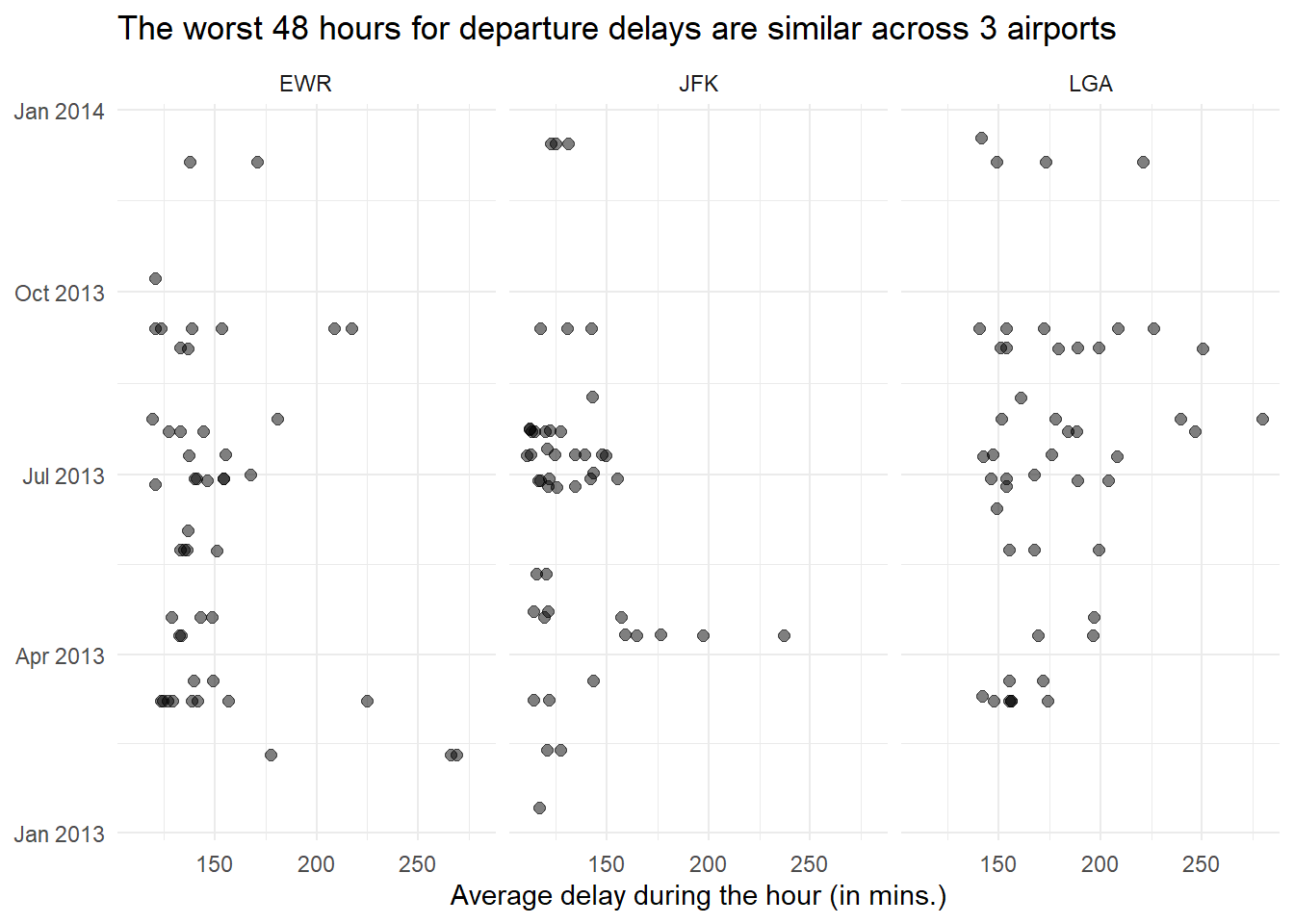
The Figure 4 depicts that across the three airports, the 48 hours with worst delays consistently have much higher rainfall (precipitation in inches) and poorer visibility (lower visibility in miles and higher dew-point in degrees F).
Code
var_labels = c("Temperature (F)", "Dewpoint (F)",
"Relative Humidity %", "Precipitation (inches)",
"Visibility (miles)")
names(var_labels) = c("temp", "dewp", "humid", "precip", "visib")
g1 = weather |>
filter(origin == "EWR") |>
left_join(delayhours) |>
mutate(
del_hrs = if_else(is.na(avg_delay),
"Other hours",
"Hours with max delays"),
precip = precip * 25.4
) |>
pivot_longer(
cols = c(temp, dewp, humid, precip, visib),
names_to = "variable",
values_to = "values"
) |>
group_by(origin, del_hrs, variable) |>
summarise(means = mean(values, na.rm = TRUE)) |>
ggplot(aes(x = del_hrs, y = means, fill = del_hrs)) +
geom_bar(stat = "identity") +
facet_wrap( ~ variable, scales = "free", ncol = 5,
labeller = labeller(variable = var_labels)) +
scale_fill_brewer(palette = "Dark2") +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
axis.title = element_blank(),
axis.text.x = element_blank(),
legend.position = "bottom") +
labs(subtitle = "Weather Patterns for Newark Airport (EWR)",
fill = "")
g2 = weather |>
filter(origin == "JFK") |>
left_join(delayhours) |>
mutate(
del_hrs = if_else(is.na(avg_delay),
"Other hours",
"Hours with max delays"),
precip = precip * 25.4
) |>
pivot_longer(
cols = c(temp, dewp, humid, precip, visib),
names_to = "variable",
values_to = "values"
) |>
group_by(origin, del_hrs, variable) |>
summarise(means = mean(values, na.rm = TRUE)) |>
ggplot(aes(x = del_hrs, y = means, fill = del_hrs)) +
geom_bar(stat = "identity") +
facet_wrap( ~ variable, scales = "free", ncol = 5,
labeller = labeller(variable = var_labels)) +
scale_fill_brewer(palette = "Dark2") +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
axis.title = element_blank(),
axis.text.x = element_blank(),
legend.position = "bottom") +
labs(subtitle = "Weather Patterns for John F Kennedy Airport (JFK)",
fill = "")
g3 = weather |>
filter(origin == "LGA") |>
left_join(delayhours) |>
mutate(
del_hrs = if_else(is.na(avg_delay),
"Other hours",
"Hours with max delays"),
precip = precip * 25.4
) |>
pivot_longer(
cols = c(temp, dewp, humid, precip, visib),
names_to = "variable",
values_to = "values"
) |>
group_by(origin, del_hrs, variable) |>
summarise(means = mean(values, na.rm = TRUE)) |>
ggplot(aes(x = del_hrs, y = means, fill = del_hrs)) +
geom_bar(stat = "identity") +
facet_wrap( ~ variable, scales = "free", ncol = 5,
labeller = labeller(variable = var_labels)) +
scale_fill_brewer(palette = "Dark2") +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
axis.title = element_blank(),
axis.text.x = element_blank(),
legend.position = "bottom") +
labs(subtitle = "Weather Patterns for La Guardia Airport (LGA)",
fill = "")
library(patchwork)
g1 / g2 / g3 + plot_layout(guides = "collect") & theme(legend.position = "bottom")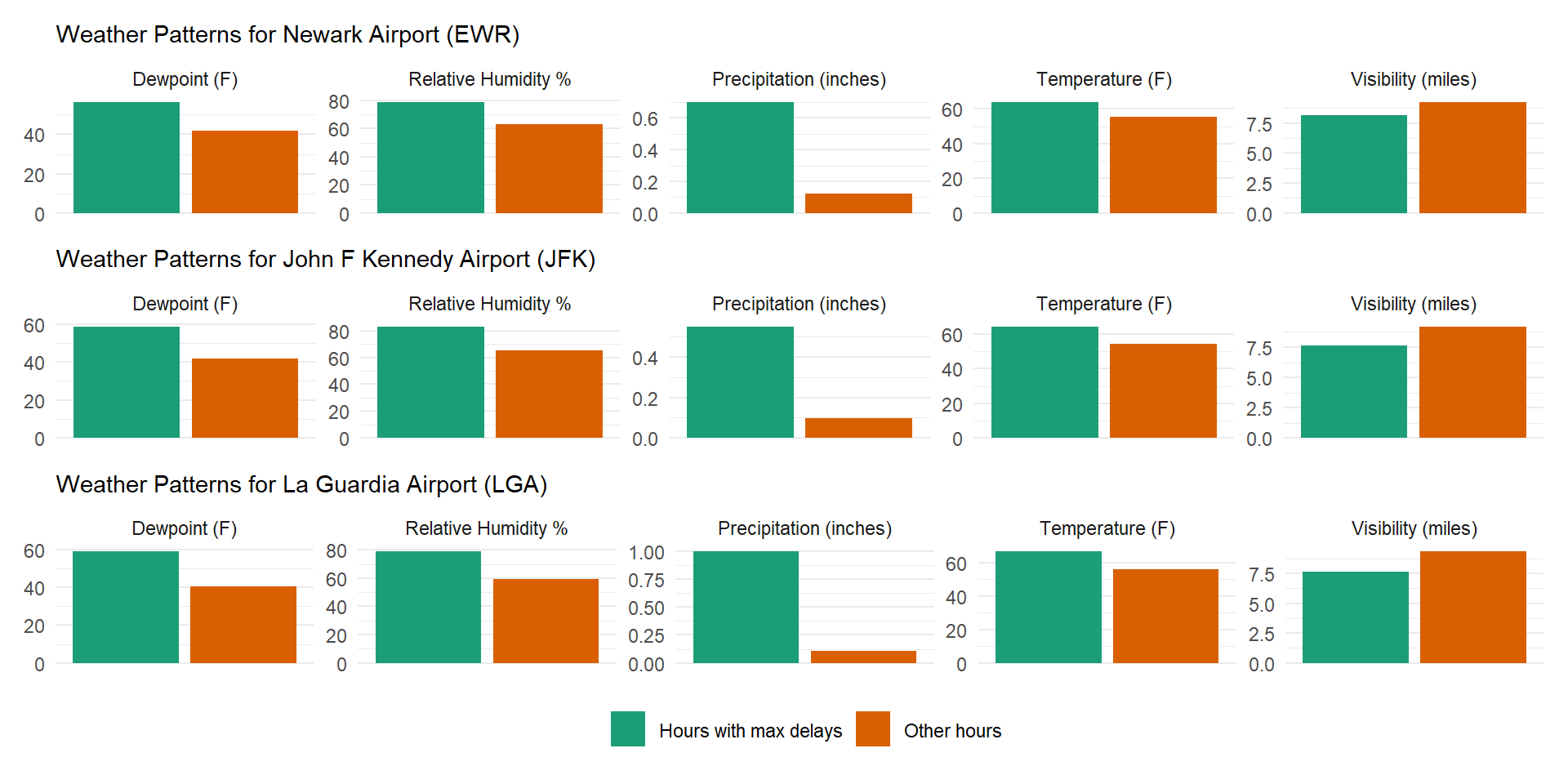
Question 2
Imagine you’ve found the top 10 most popular destinations using this code:
top_dest <- flights2 |>
count(dest, sort = TRUE) |>
head(10)How can you find all flights to those destinations?
We can first create a vector of the names of the top 10 destinations, using select(dest) and as_vector() . Thereafter, we can filter(dest %in% top_dest_vec) as shown below: –
flights2 <- flights |>
mutate(id = row_number(), .before = 1)
top_dest <- flights2 |>
count(dest, sort = TRUE) |>
head(10)
top_dest_vec <- top_dest |> select(dest) |> as_vector()
flights |>
filter(dest %in% top_dest_vec) # A tibble: 141,145 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 542 540 2 923 850
2 2013 1 1 554 600 -6 812 837
3 2013 1 1 554 558 -4 740 728
4 2013 1 1 555 600 -5 913 854
5 2013 1 1 557 600 -3 838 846
6 2013 1 1 558 600 -2 753 745
7 2013 1 1 558 600 -2 924 917
8 2013 1 1 558 600 -2 923 937
9 2013 1 1 559 559 0 702 706
10 2013 1 1 600 600 0 851 858
# ℹ 141,135 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Question 3
Does every departing flight have corresponding weather data for that hour?
No, as we can see from the code below, every departing flight DOES NOT have corresponding weather data for that hour. 1556 flights do not have associated weather data; and these correspond to 38 different hours during the year.
# Number of flights that do not have associated weather data
flights |>
anti_join(weather) |>
nrow()[1] 1556# Number of distinct time_hours that do not have such data
flights |>
anti_join(weather) |>
distinct(time_hour)# A tibble: 48 × 1
time_hour
<dttm>
1 2013-01-01 12:00:00
2 2013-01-06 06:00:00
3 2013-10-23 06:00:00
4 2013-10-23 07:00:00
5 2013-10-25 23:00:00
6 2013-10-25 20:00:00
7 2013-10-25 21:00:00
8 2013-10-25 22:00:00
9 2013-10-26 21:00:00
10 2013-11-02 20:00:00
# ℹ 38 more rows# A check to confirm our results
flights |>
select(year, month, day, origin, dest, time_hour) |>
left_join(weather) |>
summarise(
missing_temp_or_windspeed = mean(is.na(temp) & is.na(wind_speed)),
missing_dewp = mean(is.na(dewp))
)# A tibble: 1 × 2
missing_temp_or_windspeed missing_dewp
<dbl> <dbl>
1 0.00462 0.00467(as.numeric(flights |> anti_join(weather) |> nrow())) / nrow(flights)[1] 0.004620282Question 4
What do the tail numbers that don’t have a matching record in planes have in common? (Hint: one variable explains ~90% of the problems.)
The tail numbers that don’t have a matching record in planes mostly belong the a select few airline carriers, i.e., AA and MQ . The variable carrier explains most of the problems in missing data, as shown in Figure 5.
Code
# Create a unique flight ID for each flight
flights2 <- flights |>
mutate(id = row_number(), .before = 1)
ids_no_record = flights2 |>
anti_join(planes, by = join_by(tailnum)) |>
select(id) |>
as_vector() |> unname()
flights2 = flights2 |>
mutate(
missing_record = id %in% ids_no_record
)
label_vec = c("Flights with missing tailnum in planes", "Other flights")
names(label_vec) = c(FALSE, TRUE)
flights2 |>
group_by(missing_record) |>
count(carrier) |>
mutate(col_var = carrier %in% c("MQ", "AA")) |>
ggplot(aes(x = n, y = carrier, fill = col_var)) +
geom_bar(stat = "identity") +
facet_wrap(~ missing_record,
scales = "free_x",
labeller = labeller(missing_record = label_vec)) +
theme_bw() +
theme(legend.position = "none") +
labs(x = "Number of flights", y = "Carrier",
title = "Flights with missing tailnum in planes belong to a select few carriers") +
scale_fill_brewer(palette = "Set2")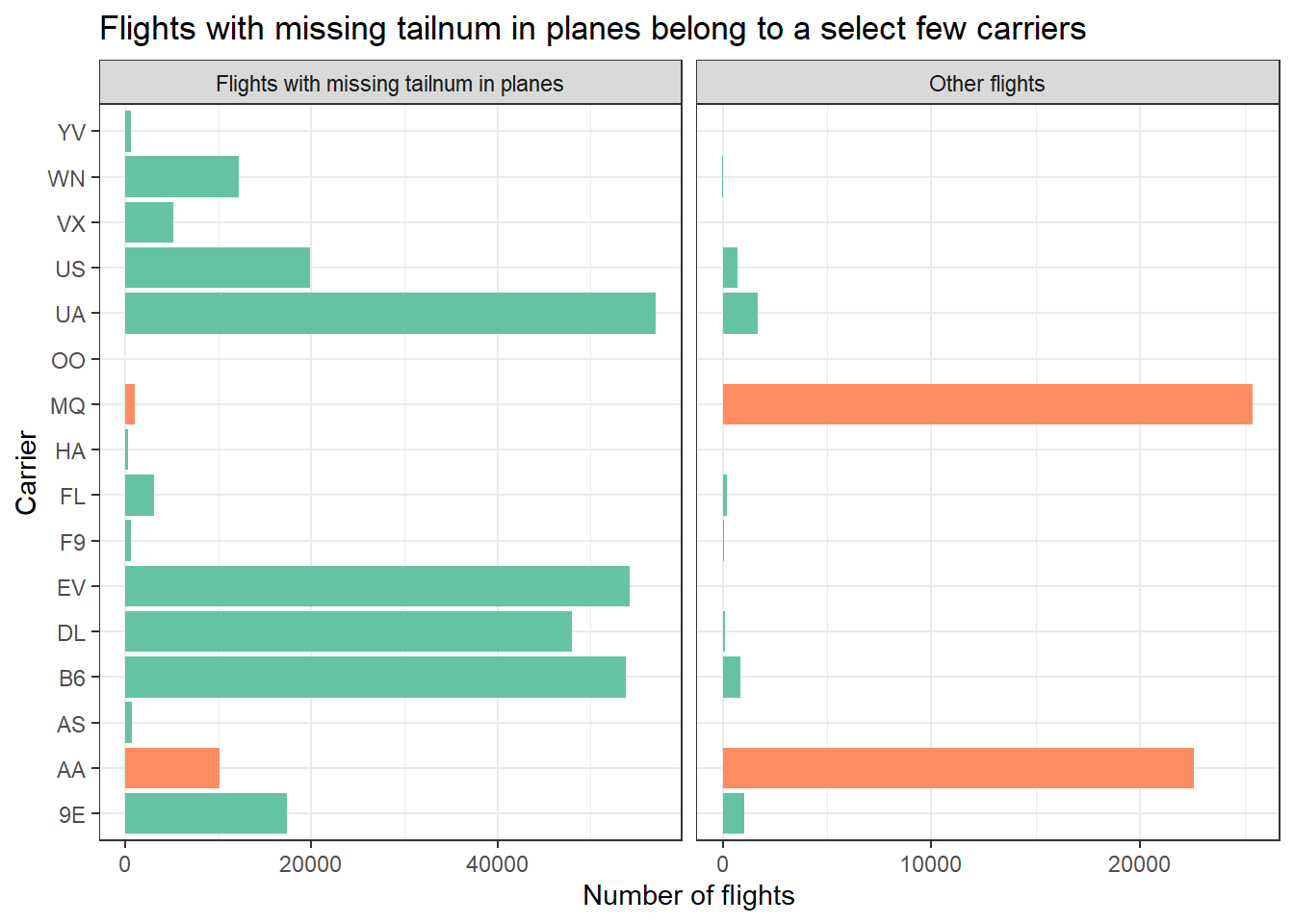
Question 5
Add a column to planes that lists every carrier that has flown that plane. You might expect that there’s an implicit relationship between plane and airline, because each plane is flown by a single airline. Confirm or reject this hypothesis using the tools you’ve learned in previous chapters.
Using the code below, we confirm that there are 17 such different airplanes (identified by tailnum) that have been flown by two carriers. These are shown in Figure 6 .
Code
# Displaying tail numbers which have been used by more than one carriers
flights |>
group_by(tailnum) |>
summarise(number_of_carriers = n_distinct(carrier)) |>
filter(number_of_carriers > 1) |>
drop_na() |>
gt() |>
opt_interactive(page_size_default = 5,
use_highlight = TRUE,
pagination_type = "simple") |>
cols_label_with(fn = ~ janitor::make_clean_names(., case = "title"))The following code adds a column to planes that lists every carrier that has flown that plane.
# A tibble that lists all carriers a tailnum has flown
all_carrs = flights |>
group_by(tailnum) |>
distinct(carrier) |>
summarise(carriers = paste0(carrier, collapse = ", ")) |>
arrange(desc(str_length(carriers)))
# Display the tibble
slice_head(all_carrs, n= 30) |>
gt() |> opt_interactive(page_size_default = 5)# Merge with planes
planes |>
left_join(all_carrs)# A tibble: 3,322 × 10
tailnum year type manufacturer model engines seats speed engine carriers
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr> <chr>
1 N10156 2004 Fixed w… EMBRAER EMB-… 2 55 NA Turbo… EV
2 N102UW 1998 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
3 N103US 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
4 N104UW 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
5 N10575 2002 Fixed w… EMBRAER EMB-… 2 55 NA Turbo… EV
6 N105UW 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
7 N107US 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
8 N108UW 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
9 N109UW 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
10 N110UW 1999 Fixed w… AIRBUS INDU… A320… 2 182 NA Turbo… US
# ℹ 3,312 more rowsQuestion 6
Add the latitude and the longitude of the origin and destination airport to flights. Is it easier to rename the columns before or after the join?
The code shown below adds the latitude and the longitude of the origin and destination airport to flights. As we can see, it easier to rename the columns after the join, so that we the same airport might (though not in this case) may be used as origin and/or dest. Further, the use of rename() after the join allows us to write the code in flow.
flights |>
left_join(airports, by = join_by(dest == faa)) |>
rename(
"dest_lat" = lat,
"dest_lon" = lon
) |>
left_join(airports, by = join_by(origin == faa)) |>
rename(
"origin_lat" = lat,
"origin_lon" = lon
) |>
relocate(origin, origin_lat, origin_lon,
dest, dest_lat, dest_lon,
.before = 1)# A tibble: 336,776 × 33
origin origin_lat origin_lon dest dest_lat dest_lon year month day
<chr> <dbl> <dbl> <chr> <dbl> <dbl> <int> <int> <int>
1 EWR 40.7 -74.2 IAH 30.0 -95.3 2013 1 1
2 LGA 40.8 -73.9 IAH 30.0 -95.3 2013 1 1
3 JFK 40.6 -73.8 MIA 25.8 -80.3 2013 1 1
4 JFK 40.6 -73.8 BQN NA NA 2013 1 1
5 LGA 40.8 -73.9 ATL 33.6 -84.4 2013 1 1
6 EWR 40.7 -74.2 ORD 42.0 -87.9 2013 1 1
7 EWR 40.7 -74.2 FLL 26.1 -80.2 2013 1 1
8 LGA 40.8 -73.9 IAD 38.9 -77.5 2013 1 1
9 JFK 40.6 -73.8 MCO 28.4 -81.3 2013 1 1
10 LGA 40.8 -73.9 ORD 42.0 -87.9 2013 1 1
# ℹ 336,766 more rows
# ℹ 24 more variables: dep_time <int>, sched_dep_time <int>, dep_delay <dbl>,
# arr_time <int>, sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, name.x <chr>, alt.x <dbl>, tz.x <dbl>,
# dst.x <chr>, tzone.x <chr>, name.y <chr>, alt.y <dbl>, tz.y <dbl>,
# dst.y <chr>, tzone.y <chr>Question 7
Compute the average delay by destination, then join on the airports data frame so you can show the spatial distribution of delays. Here’s an easy way to draw a map of the United States:
airports |>
semi_join(flights, join_by(faa == dest)) |>
ggplot(aes(x = lon, y = lat)) +
borders("state") +
geom_point() +
coord_quickmap()You might want to use the size or color of the points to display the average delay for each airport.
The following code and the resulting Figure 7 displays the result. I would like to avoid using size as an aesthetic, as it is not easy to compare on a continuous scale, and leads to visually tough comparison. Instead, I prefer to use an interactive visualization shown further below.
# Create a dataframe of 1 row for origin airports
or_apts = airports |>
filter(faa %in% c("EWR", "JFK", "LGA")) |>
select(-c(alt, tz, dst, tzone)) |>
rename(dest = faa) |>
mutate(type = "New York City",
avg_delay = 0)
# Start with the flights data-set
flights |>
# Compute average delay for each location
group_by(dest) |>
summarise(avg_delay = mean(arr_delay, na.rm = TRUE)) |>
# Add the latitude and longitude data
left_join(airports, join_by(dest == faa)) |>
select(-c(alt, tz, dst, tzone)) |>
mutate(type = "Destinations") |>
# Add a row for origin airports data
bind_rows(or_apts) |>
# Plot the map and points
ggplot(aes(x = lon, y = lat,
col = avg_delay,
shape = type,
label = name)) +
borders("state", colour = "white", fill = "lightgrey") +
geom_point(size = 2) +
coord_quickmap(xlim = c(-130, -65),
ylim = c(23, 50)) +
scale_color_viridis_c(option = "C") +
labs(col = "Average Delay at Arrival (mins.)", shape = "") +
# Themes and Customization
theme_void() +
theme(legend.position = "bottom")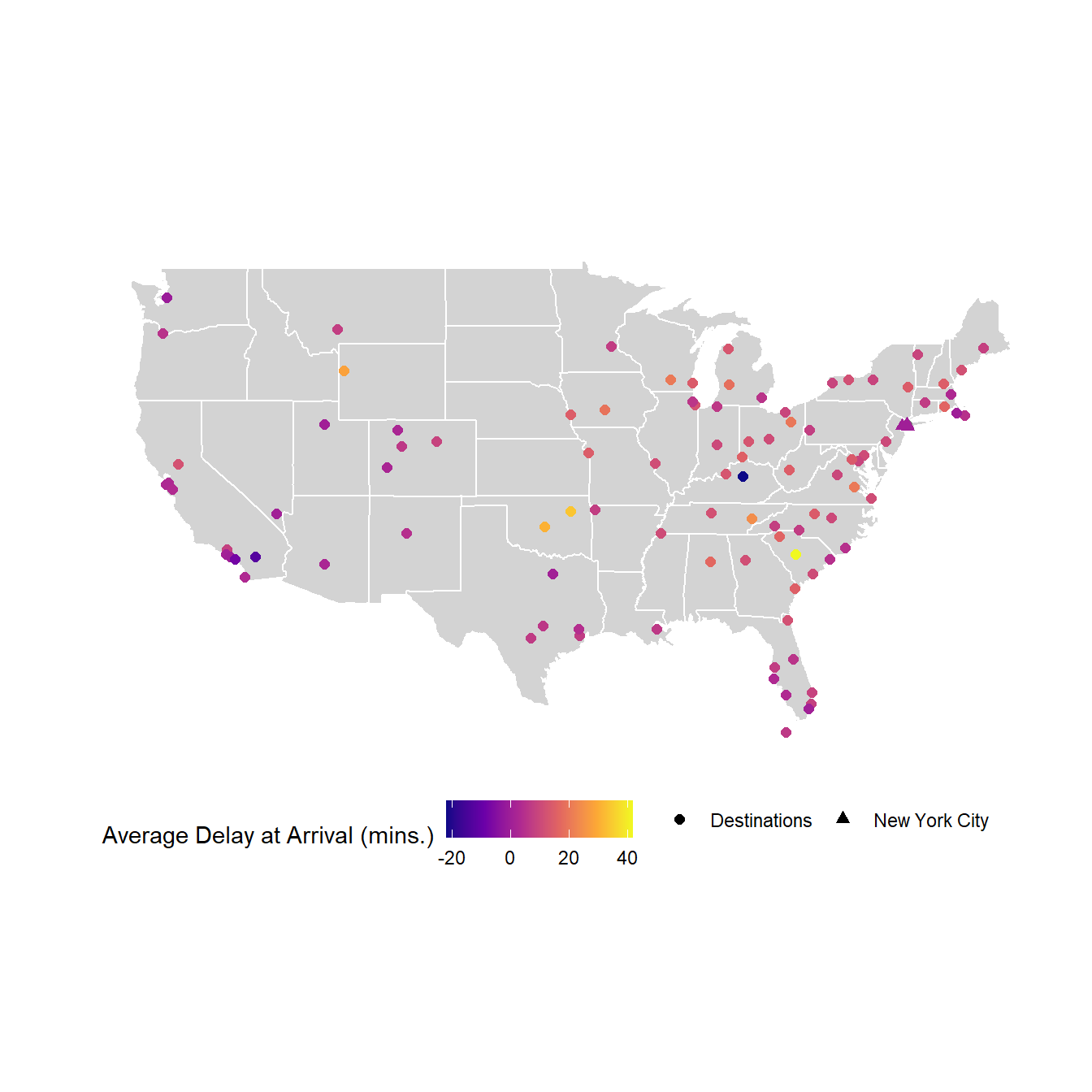
An interactive map to see average arrival delays: –
Question 8
What happened on June 13 2013? Draw a map of the delays, and then use Google to cross-reference with the weather.
In the map shown in figure Figure 8 , we see abnormally large delays for all destinations than normal.
Code
flights |>
mutate(Date = if_else((month == 6 & day == 13),
"June 13, 2013",
"Rest of the year")) |>
group_by(Date) |>
summarise(average_departure_delay = mean(dep_delay, na.rm = TRUE)) |>
gt() |>
cols_label_with(fn = ~ janitor::make_clean_names(., case = "title")) |>
fmt_number(columns = average_departure_delay) |>
gt_theme_538()| Date | Average Departure Delay |
|---|---|
| June 13, 2013 | 45.79 |
| Rest of the year | 12.55 |
Further, when we search the weather on internet using google, we find that a major storm system had hit New York City on June 13, 2013. Thus, the departure delays are expected. The links to the weather reports are here, and in an article on severe flight cancellations and delays.
# Start with the flights data-set for June 13, 2013
flights |>
filter(month == 6 & day == 13) |>
# Compute average delay for each location
group_by(dest) |>
summarise(avg_delay = mean(arr_delay, na.rm = TRUE)) |>
# Add the latitude and longitude data
left_join(airports, join_by(dest == faa)) |>
select(-c(alt, tz, dst, tzone)) |>
# Plot the map and points
ggplot(aes(x = lon, y = lat,
col = avg_delay,
label = name)) +
borders("state", colour = "white", fill = "lightgrey") +
geom_point(size = 3) +
coord_quickmap(xlim = c(-130, -65),
ylim = c(23, 50)) +
scale_color_viridis_c(option = "C") +
labs(col = "Average Delay at Arrival (mins.)", shape = "",
title = "Flight delays on June 13, 2013 re much higher than normal") +
# Themes and Customization
theme_void() +
theme(legend.position = "bottom")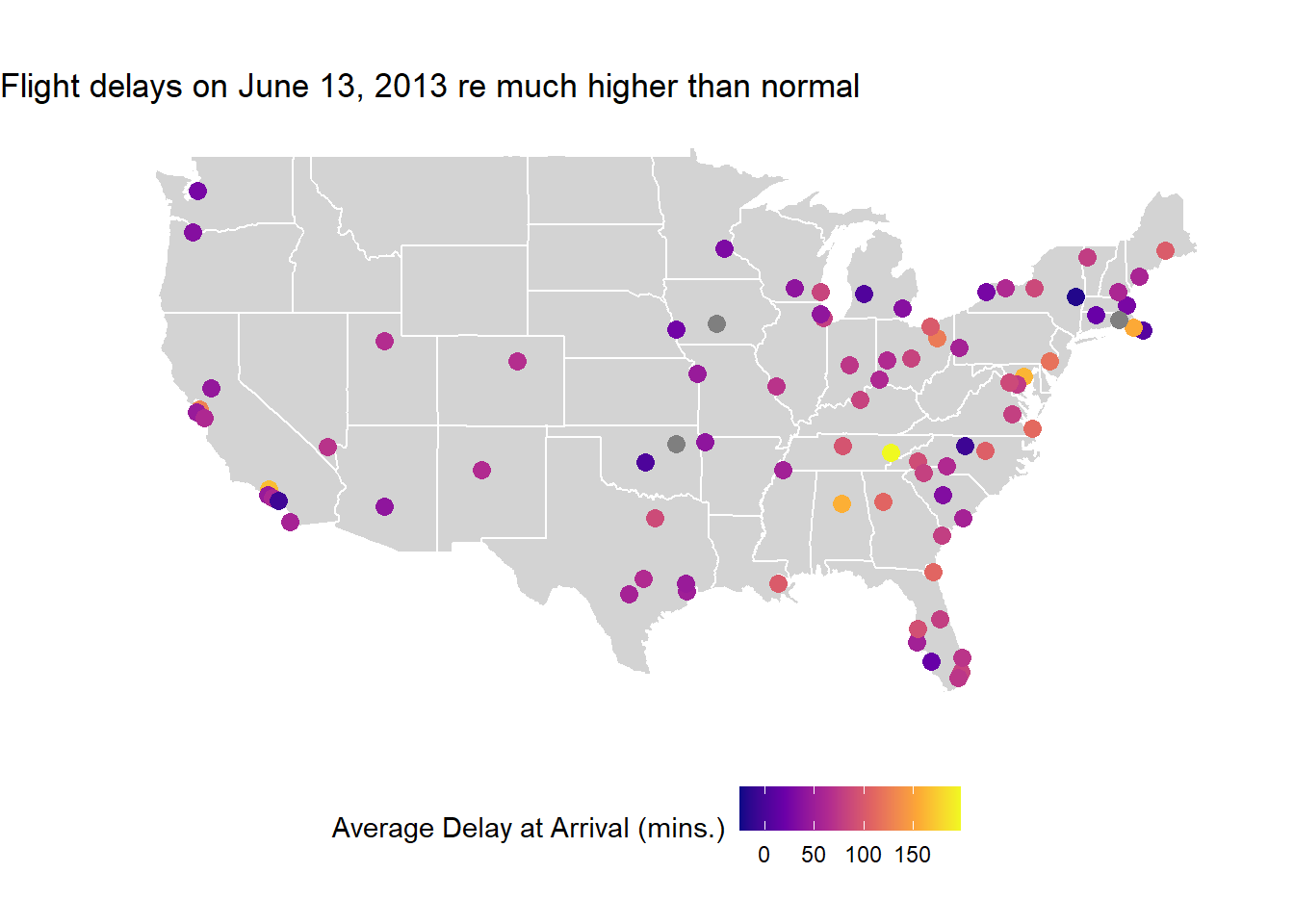
20.5.5 Exercises
Question 1
Can you explain what’s happening with the keys in this equi join? Why are they different?
x |>
full_join(y, by = "key")
#> # A tibble: 4 × 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 3 x3 <NA>
#> 4 4 <NA> y3
x |>
full_join(y, by = "key", keep = TRUE)
#> # A tibble: 4 × 4
#> key.x val_x key.y val_y
#> <dbl> <chr> <dbl> <chr>
#> 1 1 x1 1 y1
#> 2 2 x2 2 y2
#> 3 3 x3 NA <NA>
#> 4 NA <NA> 4 y3Yes, the key column names in the output are different because when we use the option keep = TRUE in the full_join() function, the execution by dplyr retains both the keys and names them as key.x and key.y for ease of recognition.
Question 2
When finding if any party period overlapped with another party period we used q < q in the join_by()? Why? What happens if you remove this inequality?
The default syntax for function inner_join is inner_join(x, y, by = NULL, ...) . The default for by = argument is NULL, where the default *_join() will perform a natural join, using all variables in common across x and y.
Thus, when we skip q < q , the inner_join finds that the variables q , start and end are common. The start and end variables are taken care of by the helper function overlaps() . But q remains. Since q is common in parties and parties all observations get matched. To prevent observations from matching on q we can keep a condition q < q , and thus each observation and match is repeated only once, leading to correct results.
parties <- tibble(
q = 1:4,
party = ymd(c("2022-01-10", "2022-04-04", "2022-07-11", "2022-10-03")),
start = ymd(c("2022-01-01", "2022-04-04", "2022-07-11", "2022-10-03")),
end = ymd(c("2022-04-03", "2022-07-11", "2022-10-02", "2022-12-31"))
)
# Using the correct code in textbook
parties |>
inner_join(parties, join_by(overlaps(start, end, start, end), q < q)) |>
select(start.x, end.x, start.y, end.y)# A tibble: 1 × 4
start.x end.x start.y end.y
<date> <date> <date> <date>
1 2022-04-04 2022-07-11 2022-07-11 2022-10-02# Removing the "q < q" in the join_by()
parties |>
inner_join(parties, join_by(overlaps(start, end, start, end))) |>
select(start.x, end.x, start.y, end.y)# A tibble: 6 × 4
start.x end.x start.y end.y
<date> <date> <date> <date>
1 2022-01-01 2022-04-03 2022-01-01 2022-04-03
2 2022-04-04 2022-07-11 2022-04-04 2022-07-11
3 2022-04-04 2022-07-11 2022-07-11 2022-10-02
4 2022-07-11 2022-10-02 2022-04-04 2022-07-11
5 2022-07-11 2022-10-02 2022-07-11 2022-10-02
6 2022-10-03 2022-12-31 2022-10-03 2022-12-31